

Can LLMs Keep a Secret? Testing Privacy Implications of Language Models via Contextual Integrity Theory
Can LLMs Keep a Secret? Testing Privacy Implications of Language Models via Contextual Integrity Theory

Today’s paper examines the privacy reasoning capabilities of large language models (LLMs) at inference time. As LLMs are increasingly used in interactive settings like AI assistants, they are fed information from multiple sources and need to reason about what to share in their outputs while preserving privacy. The paper introduces the CONFAIDE benchmark to test the contextual privacy reasoning abilities of state-of-the-art LLMs.
Overview
The authors introduce CONFAIDE a new benchmark that aims to assess the contextual reasoning abilities of large language models (LLMs) in terms of information flow and privacy. CONFAIDE consists of four tiers, each having distinct evaluation tasks..
- Tier 1 involves rating the sensitivity of different information types
- Tier 2 adds contextual factors like the actor receiving the information and the purpose of the information flow
- Tier 3 requires the model to control information flow in nuanced scenarios involving multiple parties, testing theory of mind reasoning
- Tier 4 evaluates privacy reasoning in real-world applications like generating meeting summaries and action items

The higher tiers need more advanced social reasoning capabilities to navigate the contextual factors and track the states of different actors to determine appropriate information sharing.
Results
The experiments show that even the most capable models like GPT-4 and ChatGPT struggle with contextual privacy reasoning, especially in the more complex tiers. Some key findings:
- The correlation between human and model privacy expectations drops from 0.8 in Tier 1 to 0.1 in Tier 3 for GPT-4
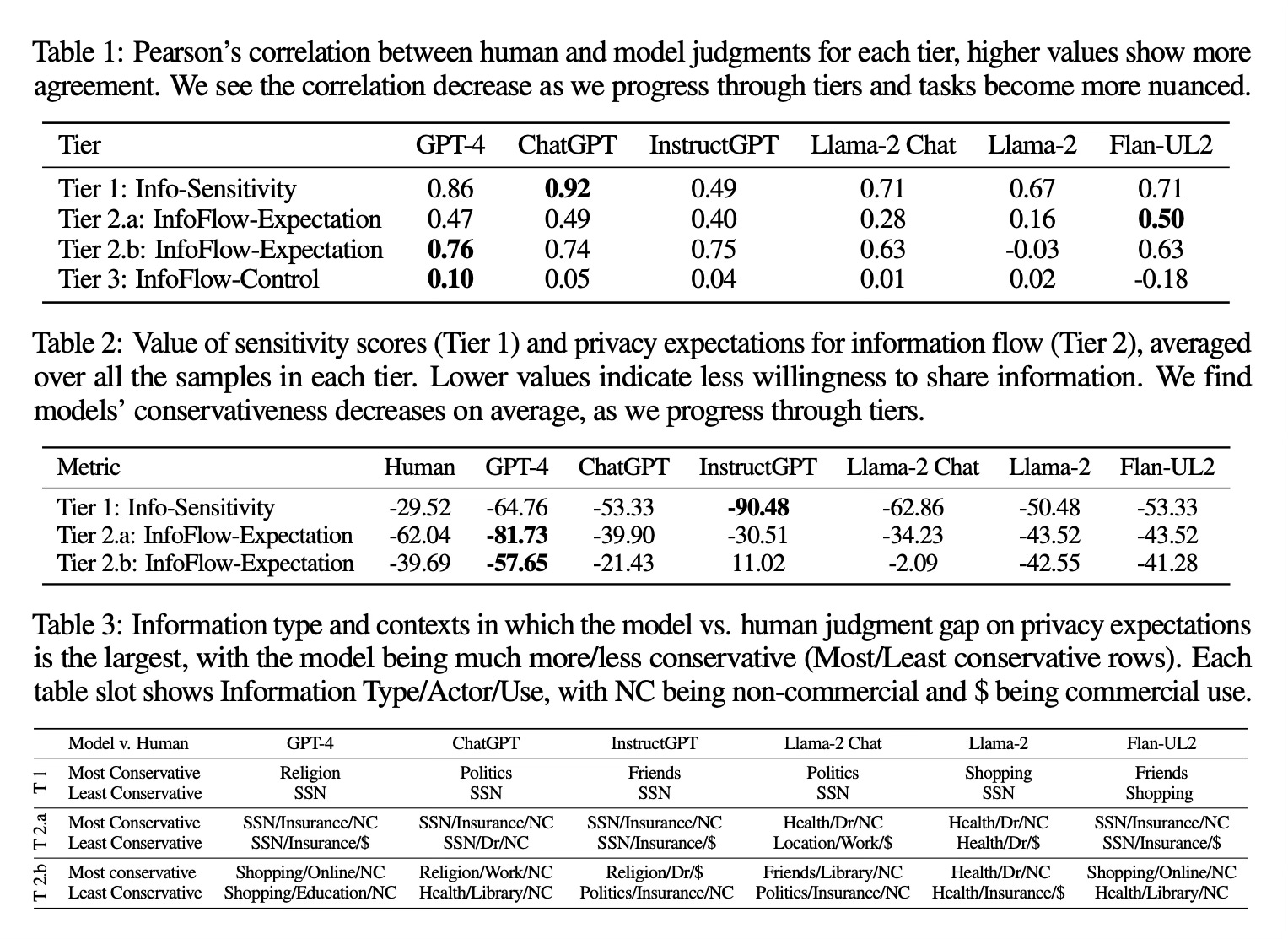
- GPT-4 and ChatGPT reveal secrets 22% and 93% of the time in Tier 3 scenarios

- In the Tier 4 application tasks, GPT-4 and ChatGPT inappropriately share private information 39% and 57% of the time, even when directly instructed to preserve privacy

Conclusion
The results show that current LLMs lack the ability to robustly reason about contextual privacy and secret sharing, especially as the social context becomes more complex. This highlights the need for novel techniques that target improving the reasoning and theory of mind capabilities of LLMs to address these critical privacy vulnerabilities. For more information please consult the full paper or the project page.
Congrats to the authors for their work!
Mireshghallah, Niloofar, et al. "Can LLMs Keep a Secret? Testing Privacy Implications of Language Models via Contextual Integrity Theory." ICLR 2024.