

CogVLM2: Visual Language Models for Image and Video Understanding
CogVLM2: Visual Language Models for Image and Video Understanding

Today's paper introduces CogVLM2, a new family of visual language models for image and video understanding. The CogVLM2 family includes models for image comprehension, video analysis, and bilingual (English-Chinese) visual language tasks. These models aim to enhance vision-language fusion, improve efficiency for high-resolution inputs, and expand into broader modalities and applications.
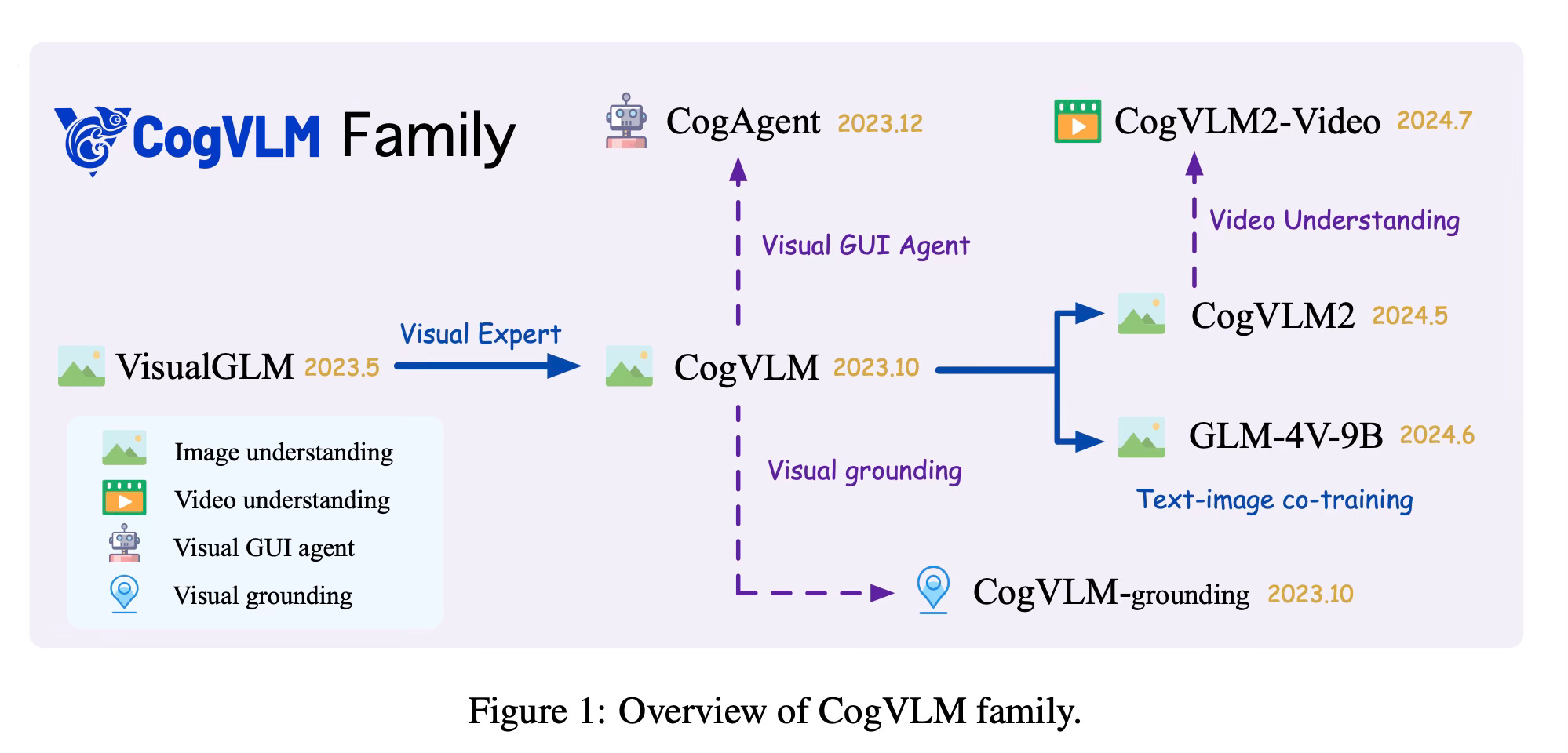
Method Overview
The CogVLM2 family builds upon previous work in visual language models, but with several key differences. At its core, the models use a Vision Transformer (ViT) encoder to process image inputs, followed by an adapter that bridges visual and linguistic features. This adapter uses a 2x2 convolutional layer and a SwiGLU module to efficiently reduce sequence length while preserving critical image information.
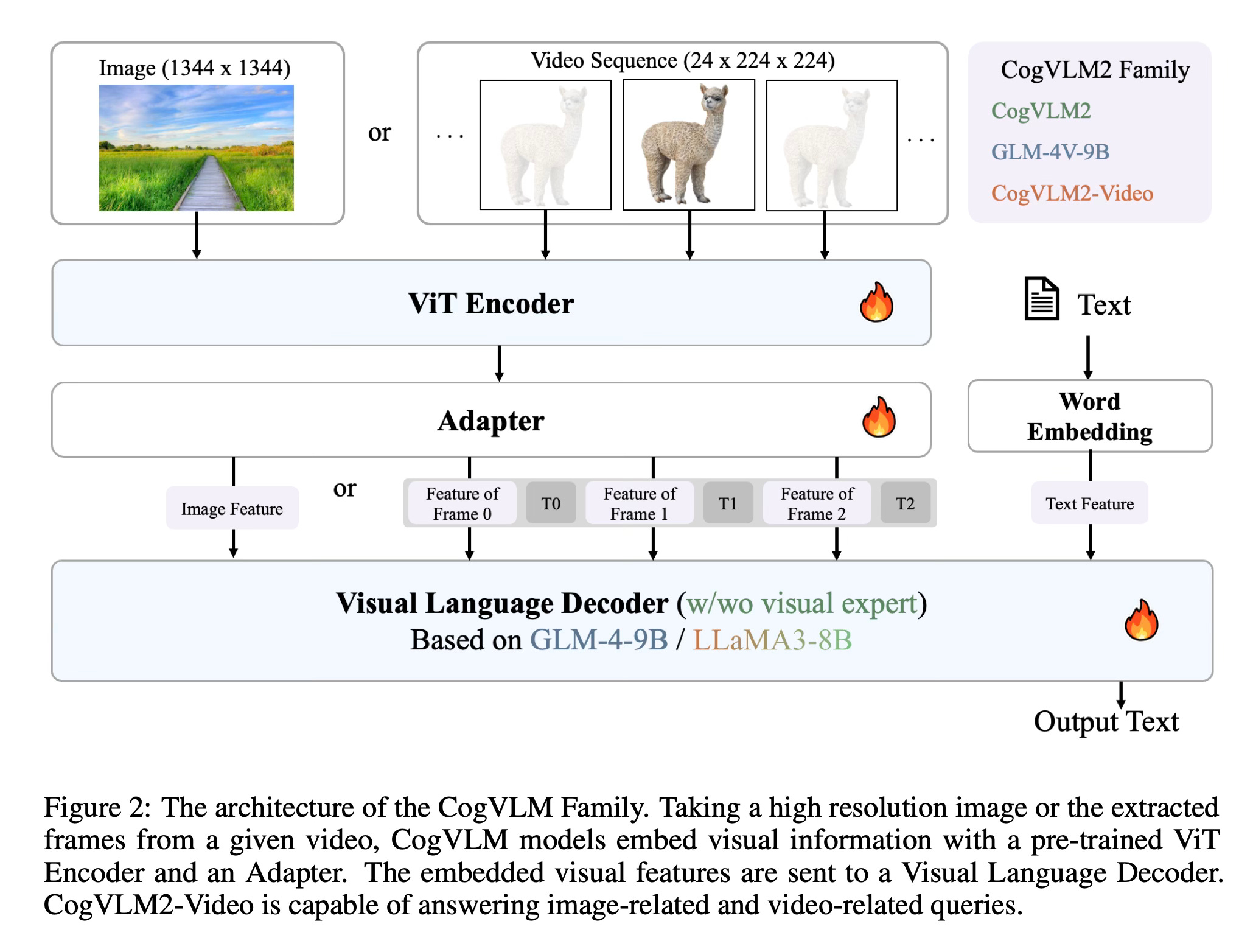
For image understanding, CogVLM2 employs a visual expert architecture that allows for deep fusion of visual and linguistic features without compromising language capabilities. It also incorporates a 2x2 downsampling module to increase input resolution while maintaining efficiency.
CogVLM2-Video extends the architecture to handle video inputs. It introduces multi-frame video images and timestamps as encoder inputs, allowing the model to maintain temporal awareness. This enables capabilities such as temporal localization and timestamp detection.
GLM-4V, another member of the family, is designed for bilingual (English and Chinese) visual language tasks. It uses a similar architecture to CogVLM2 but employs image-language co-training instead of visual experts to preserve language knowledge.
The training process for these models involves both pre-training and post-training phases. In pre-training, they use a combination of existing large-scale image-text datasets and custom-created datasets. These include synthetic OCR datasets, digital world grounding datasets, and recaptioned datasets. The pre-training process employs techniques such as iterative refinement and synthetic data generation to improve data quality and diversity.
Post-training involves fine-tuning on a variety of visual question-answering datasets and carefully annotated alignment corpora. This phase helps to enhance the models' performance on specific tasks and align their outputs with human preferences.
Results
The CogVLM2 family achieves state-of-the-art results on several benchmarks:
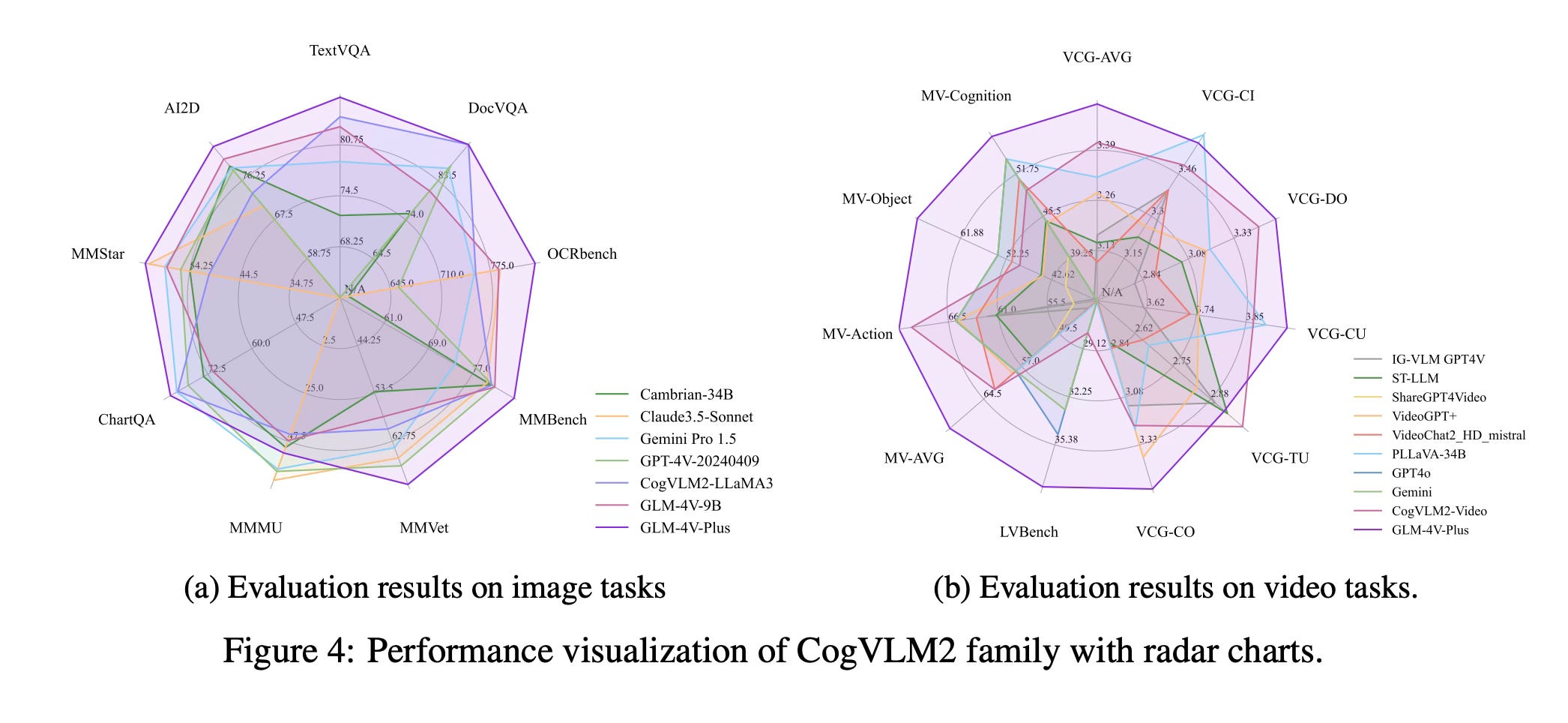
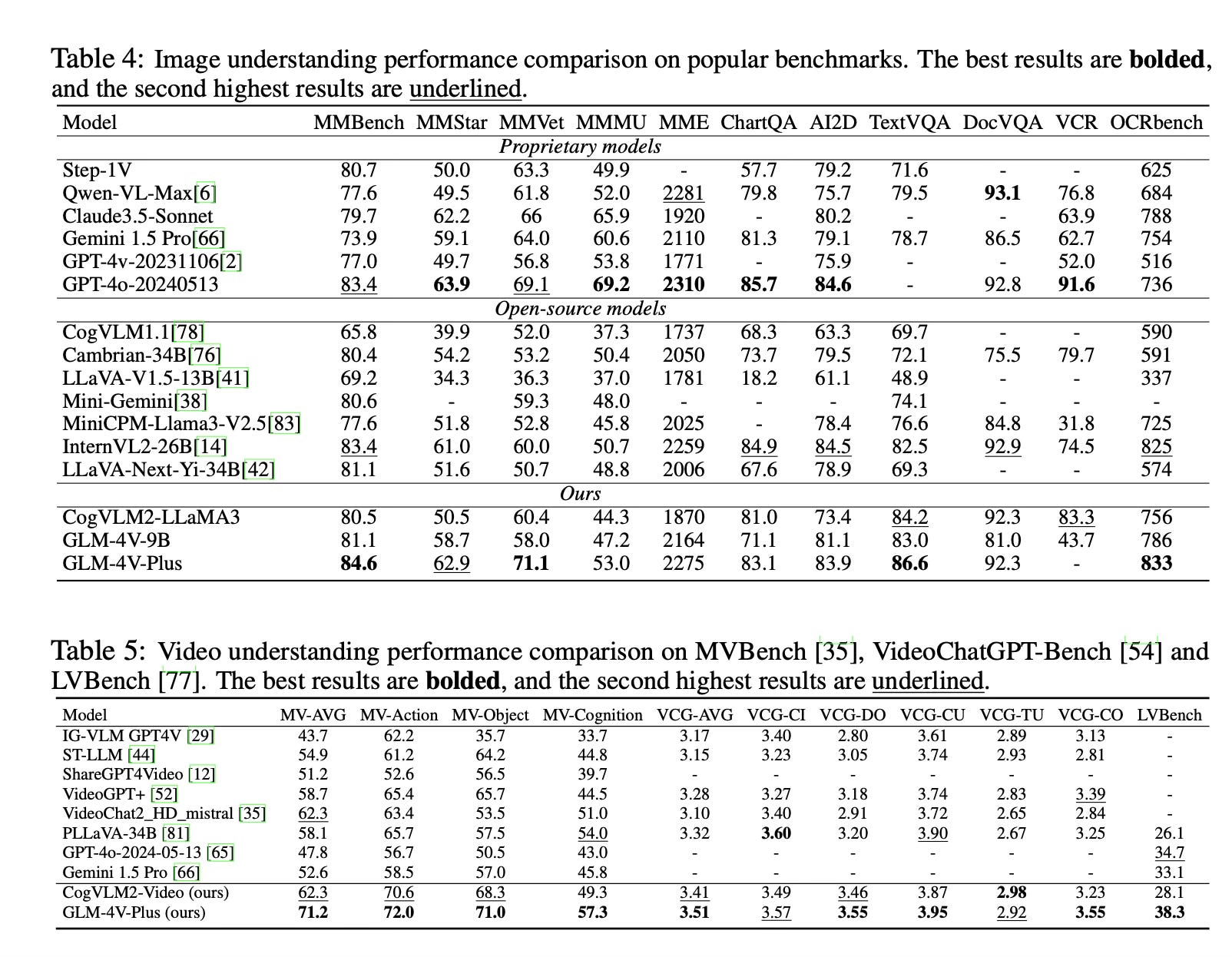
CogVLM2 shows strong performance in natural image understanding and OCR capabilities, achieving top scores on benchmarks like MMBench, VCR, MM-Vet, TextVQA, DocVQA, and ChartQA.
GLM-4V-9B shows good results in OCRbench and outperforms other open-source models in tasks like MMStar, AI2D, and MMMU.
CogVLM2-Video achieves state-of-the-art performance on public video understanding benchmarks and excels in video captioning and temporal grounding tasks.
Conclusion
The CogVLM2 family represents a new advancement in visual language models, offering improved vision-language fusion, efficient processing of high-resolution inputs, and expanded capabilities across various modalities. For more information please consult the full paper.
Congrats to the authors for their work!
Hong, Wenyi, et al. "CogVLM2: Visual Language Models for Image and Video Understanding." arXiv preprint arXiv:2408.16500 (2024).