

Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context

Gemini 1.5 Pro represents the latest advancement in the Gemini model lineup, introducing a multimodal mixture-of-experts architecture that significantly expands the capacity for understanding and interacting with complex, long-context information. Capable of processing millions of tokens across text, video, and audio modalities, this model sets new benchmarks in long-context retrieval tasks, long-document question-answering (QA), and long-context automatic speech recognition (ASR), among others.
Method Overview
At its core, Gemini 1.5 Pro utilizes a sparse mixture-of-expert (MoE) Transformer-based model. This architecture, complemented by advances in training and serving infrastructure, allows the model to efficiently process and understand inputs up to 10 million tokens in length. This vast improvement in context length enables the model to handle entire collections of documents, hours of video, and days of audio without significant degradation in performance.
Training Approach: Trained on Google's TPUv4 accelerators, Gemini 1.5 Pro utilizes a diverse multimodal and multilingual dataset sourced from various domains, including web documents, code, images, audio, and video.
Results
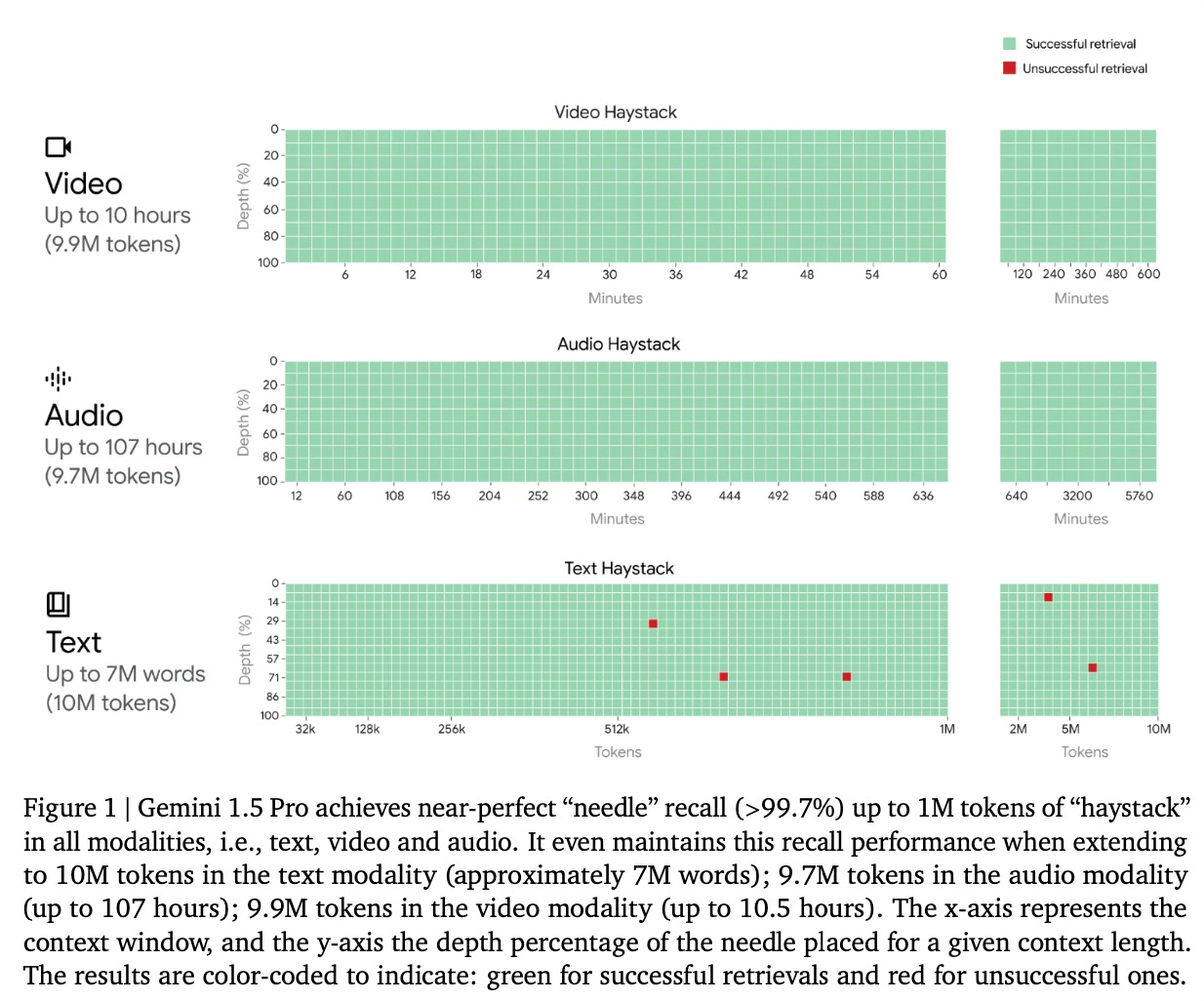
Gemini 1.5 Pro achieves near-perfect recall (>99%) in long-context retrieval tasks across all tested modalities and demonstrates superior performance in long-document QA and long-context ASR tasks.
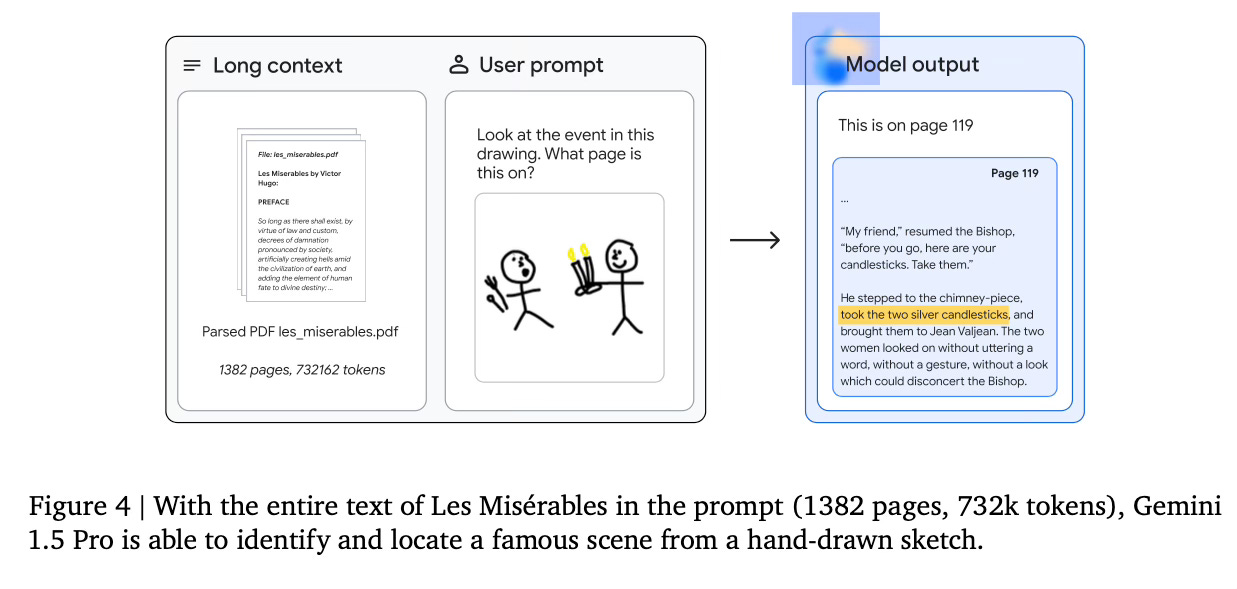
For example, it is able to find functions in huge codebases or identify scenes from large books given a sketch of the scene.

When it comes to core capabilities, it maintains high performance levels across a wide range of benchmarks, significantly outperforming Gemini 1.0 versions in math, science, reasoning, multilinguality, video understanding, and image understanding tasks. Moreover, it achieves comparable or superior results to Gemini 1.0 Ultra.

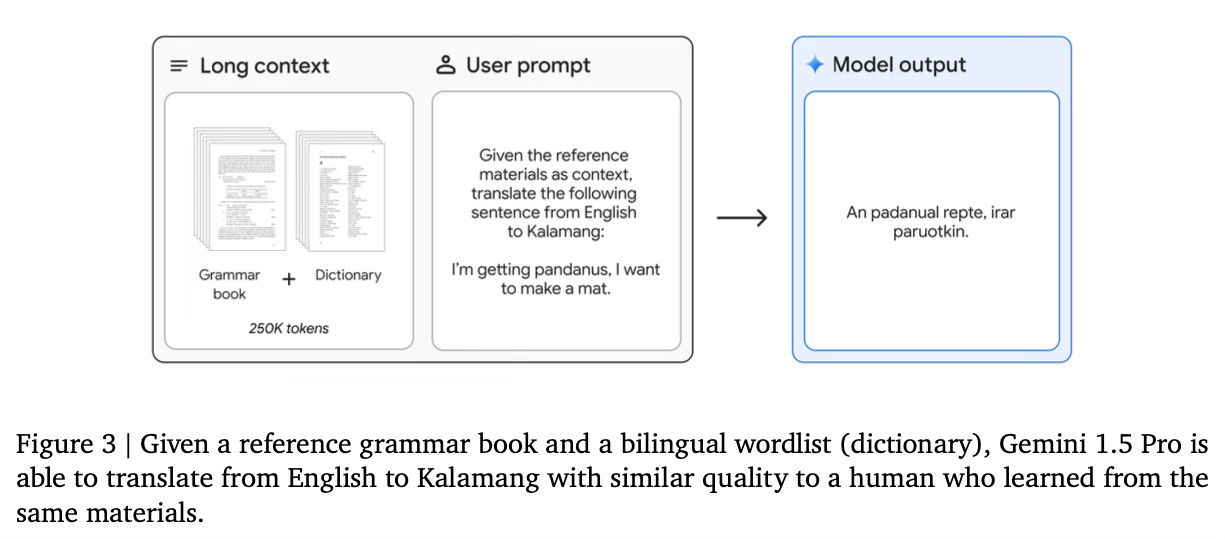
Finally, the large context can be used for acquiring new capabilities. For example, using in-context Language Learning the model is able to learn languages that have minimal online presence. By giving a reference grammar book for the target language, the model can successfully learn to translate between English and Kalamang, a language with fewer than 200 speakers.
Conclusion
The introduction of Gemini 1.5 Pro represents a significant advancement in the field of AI and LLMs, particularly in multimodal understanding and processing of long-context information. For more details please consult the full paper.
Congrats to the authors for their work!
Gemini Team Google. "Gemini 1.5: Unlocking Multimodal Understanding Across Millions of Tokens of Context." Google, 2024.