

LLaVA-3D: A Simple yet Effective Pathway to Empowering LMMs with 3D-awareness
LLaVA-3D: A Simple yet Effective Pathway to Empowering LMMs with 3D-awareness

Today's paper introduces LLaVA-3D, a new approach for empowering large multimodal models (LMMs) with 3D spatial awareness. The authors propose a simple yet effective method to adapt 2D LMMs for 3D scene understanding tasks while preserving their 2D image comprehension capabilities.
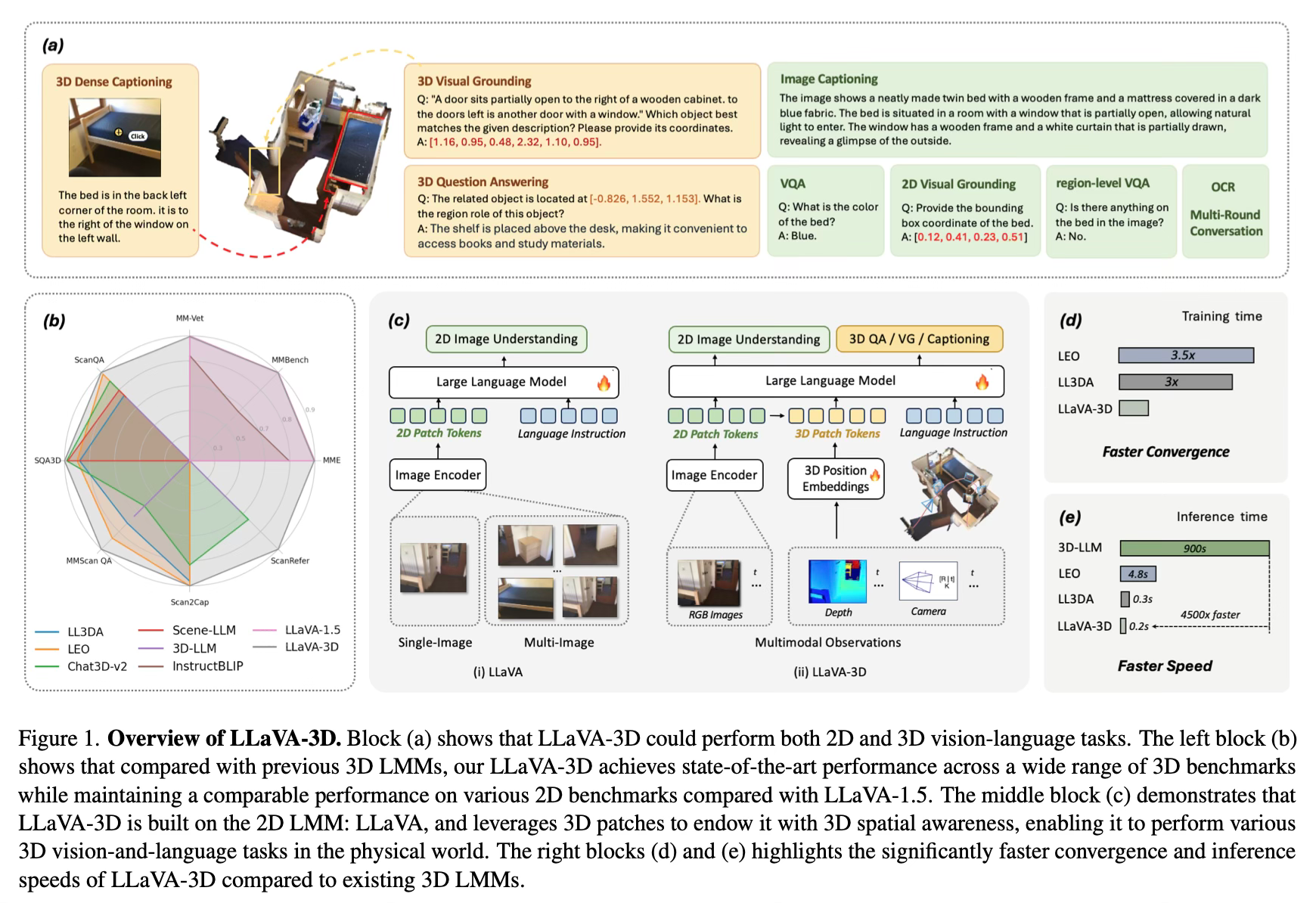
Method Overview
LLaVA-3D builds upon the existing LLaVA model, which is designed for 2D image understanding. It introduces "3D Patches", a new representation that bridges 2D features with 3D spatial context.
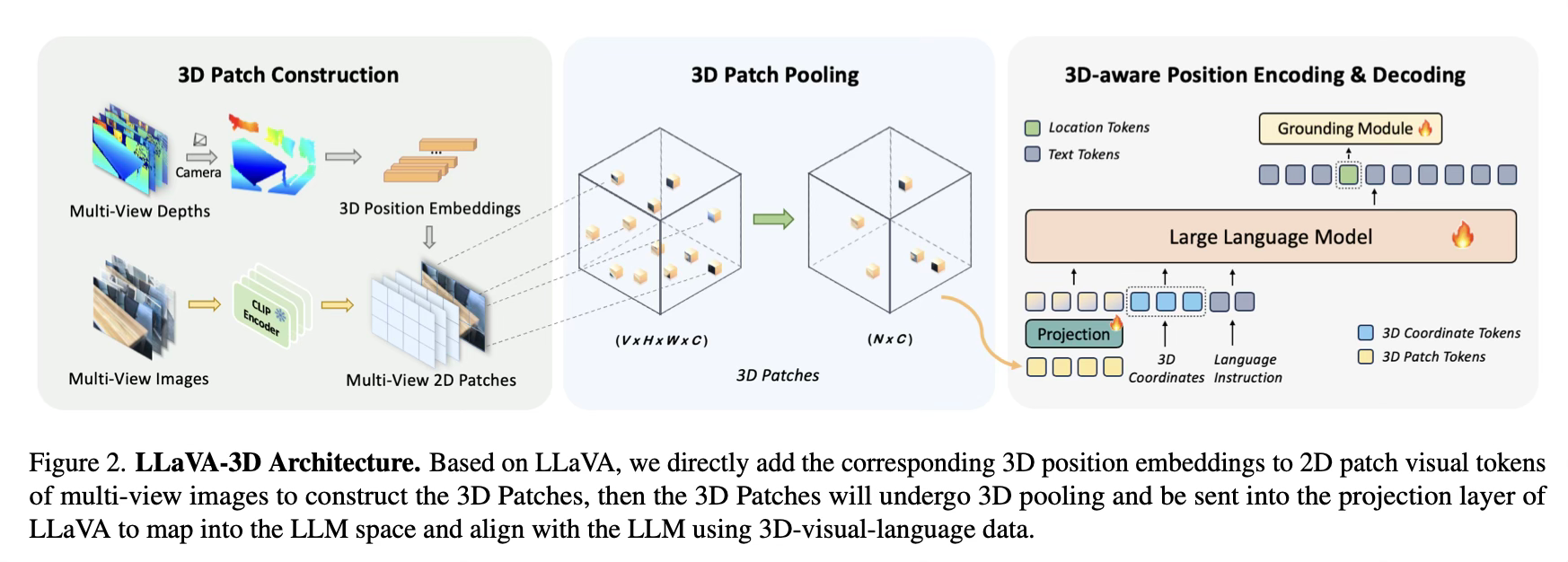
To create 3D Patches, the model takes multi-view images of a 3D scene as input. It extracts 2D patch features using a pre-trained CLIP visual encoder. These 2D features are then augmented with 3D positional embeddings, which encode the 3D spatial information of each patch. This simple yet effective approach allows the model to leverage the strong visual-semantic alignment of 2D features while gaining 3D spatial awareness.
To handle the large number of 3D Patches generated from multiple input images, the authors introduce 3D-aware pooling strategies. They explore two methods: Voxelization Pooling and Farthest Point Sampling (FPS) Pooling. These techniques reduce the number of visual tokens while preserving the overall 3D structure of the scene.
The model is trained in two stages. First, it aligns the 3D Patches with language using region-level and scene-level caption data. Then, it undergoes instruction tuning on a mixture of 2D and 3D vision-language tasks. This approach allows LLaVA-3D to develop strong 3D understanding capabilities while maintaining its 2D image comprehension skills.
For tasks requiring precise 3D localization, such as 3D visual grounding, LLaVA-3D incorporates a specialized grounding module. This module takes the last layer embedding of a predicted location token and combines it with 3D scene features to generate accurate 3D bounding boxes.
Results
LLaVA-3D achieves state-of-the-art performance across a wide range of 3D vision-language benchmarks:
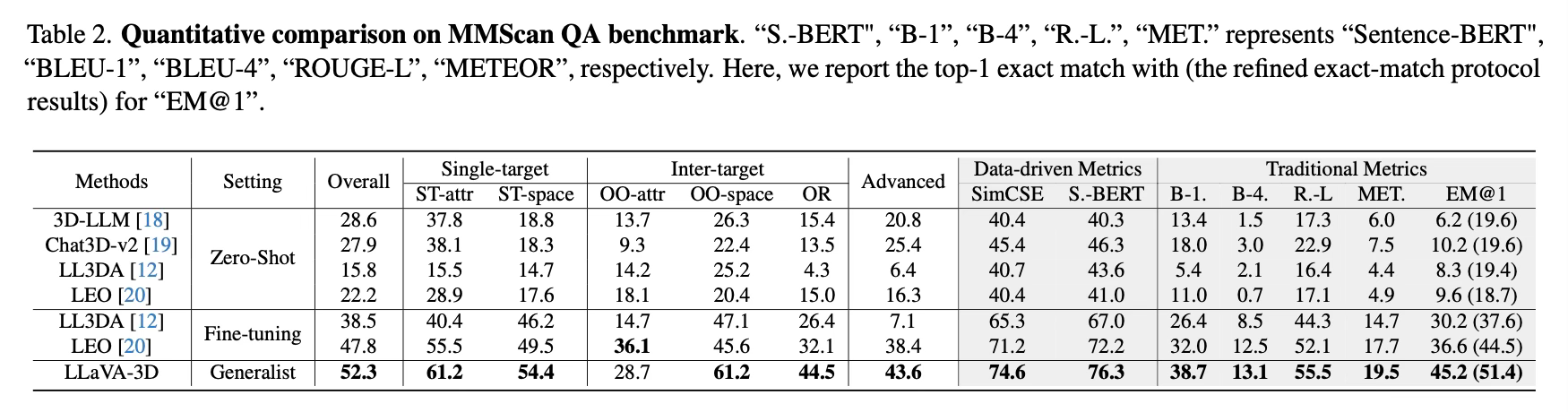
On 3D question answering tasks (ScanQA, SQA3D, MMScan QA), it outperforms existing 3D LMMs and even surpasses some task-specific models.
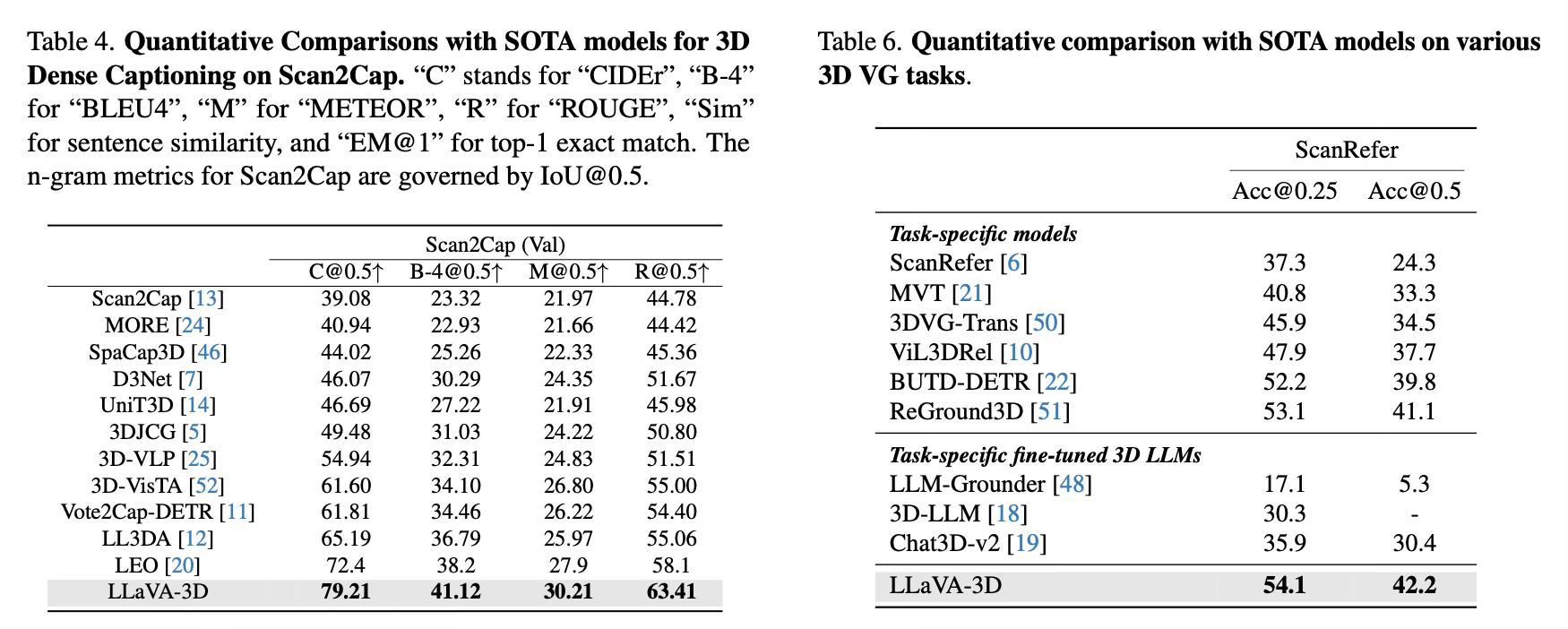
For 3D dense captioning on the Scan2Cap benchmark, LLaVA-3D significantly improves upon previous methods, achieving a CIDEr score of 79.21.
In 3D visual grounding on the ScanRefer dataset, it achieves an Acc@0.25 of 54.1% and Acc@0.5 of 42.2%, surpassing both task-specific and general 3D LMMs.
Importantly, LLaVA-3D maintains comparable performance to the original LLaVA model on various 2D image understanding benchmarks, demonstrating its ability to serve as a unified model for both 2D and 3D tasks.
Conclusion
LLaVA-3D presents a simple yet effective approach to empower 2D LMMs with 3D spatial awareness. By introducing 3D Patches and leveraging the strong priors from pre-trained 2D LMMs, the model achieves state-of-the-art performance on various 3D vision-language tasks while maintaining strong 2D image understanding capabilities. For more information please consult the full paper.
Congrats to the authors for their work!
Zhu, Chenming, et al. "LLaVA-3D: A Simple yet Effective Pathway to Empowering LMMs with 3D-awareness." arXiv preprint arXiv:2409.18125 (2024).