

Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Multimodal Models
Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Multimodal Models

Today's paper introduces Molmo, a new family of state-of-the-art open vision-language models (VLMs), along with PixMo, a novel dataset for training these models. The key to Molmo is a data collection strategy that uses speech-based image descriptions to create highly detailed captions without relying on synthetic data from proprietary VLMs. This approach allows for the development of powerful open-source multimodal models that can compete with proprietary systems.
Method Overview
The Molmo family of models is built using a simple architecture that combines a pre-trained vision encoder with a large language model (LLM). The key to their success lies in the training data and process.
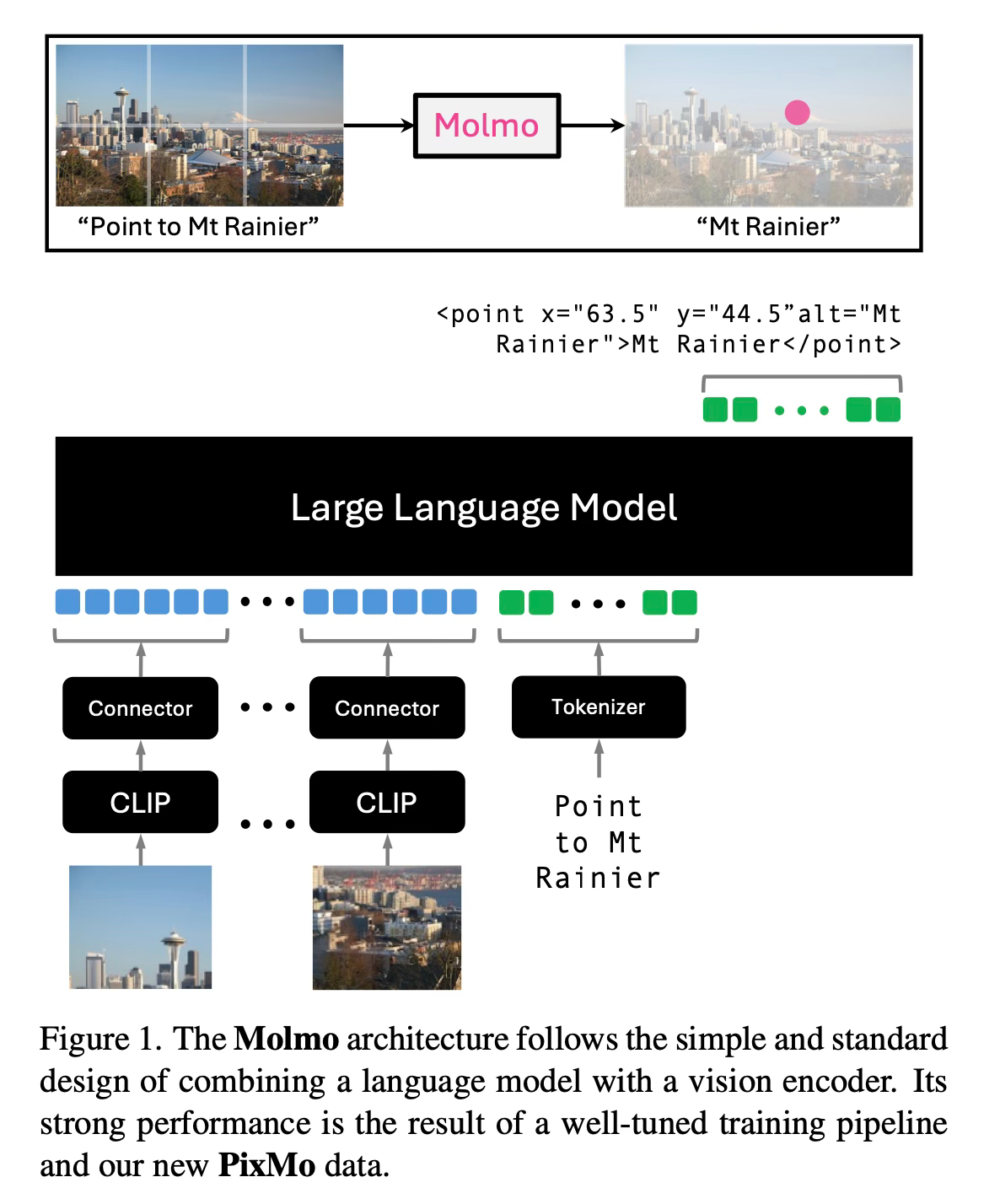
The training pipeline consists of two main stages. In the first stage, they train the model on caption generation using their newly collected PixMo-Cap dataset. This dataset is created by annotators describing images verbally for 60-90 seconds, providing much more detailed descriptions than typical written captions. These audio descriptions are then transcribed and processed to create high-quality, dense captions.
In the second stage, the model is fine-tuned on a mixture of supervised training data. This includes both standard academic datasets and several new PixMo datasets they created. These new datasets cover a wide range of tasks, including answering diverse real-world questions, pointing to specific elements in images, reading analog clocks, and working with document-focused questions.
One particularly innovative aspect is the PixMo-Points dataset, which trains the model to point at objects in images. This enables the model to ground language in visual space, improve counting accuracy, and potentially opens up new possibilities for controlling agents in visual environments.
The training process is straightforward, with all model parameters being updated in both stages. Also, it avoids complex multi-stage training processes used by some other models and do not rely on reinforcement learning from human feedback (RLHF).
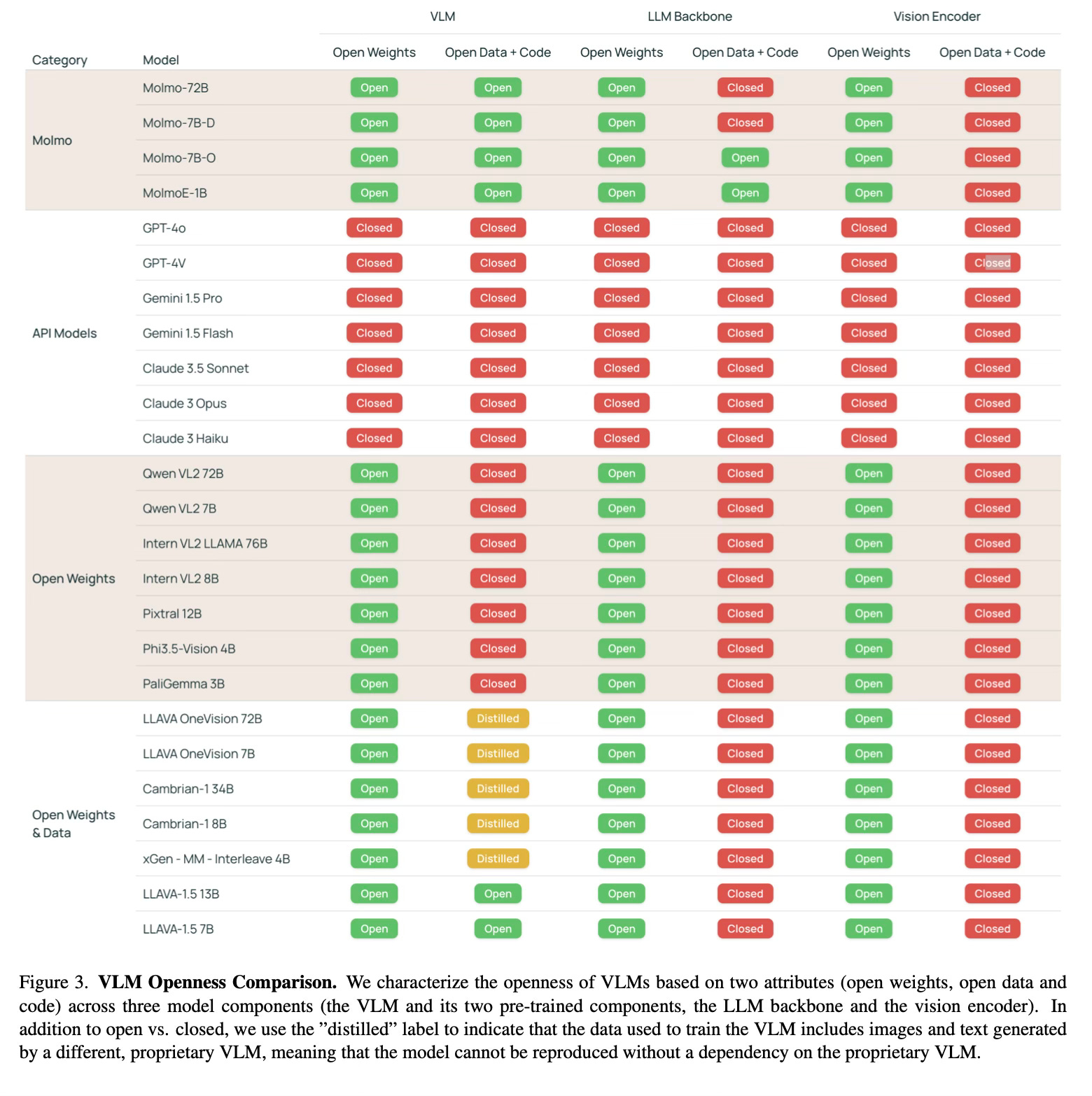
Results
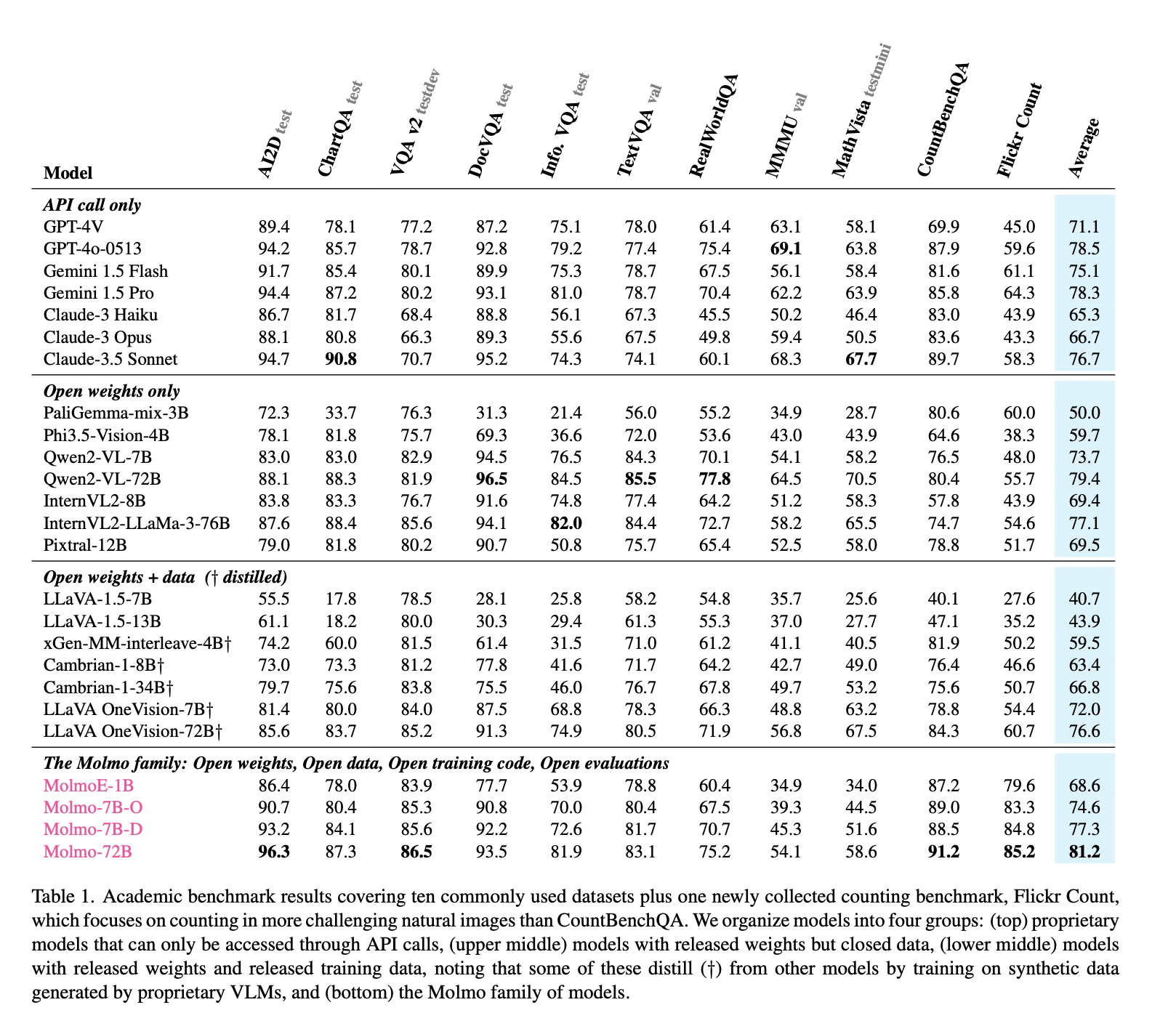
The Molmo family of models achieves impressive results across various benchmarks and evaluations:
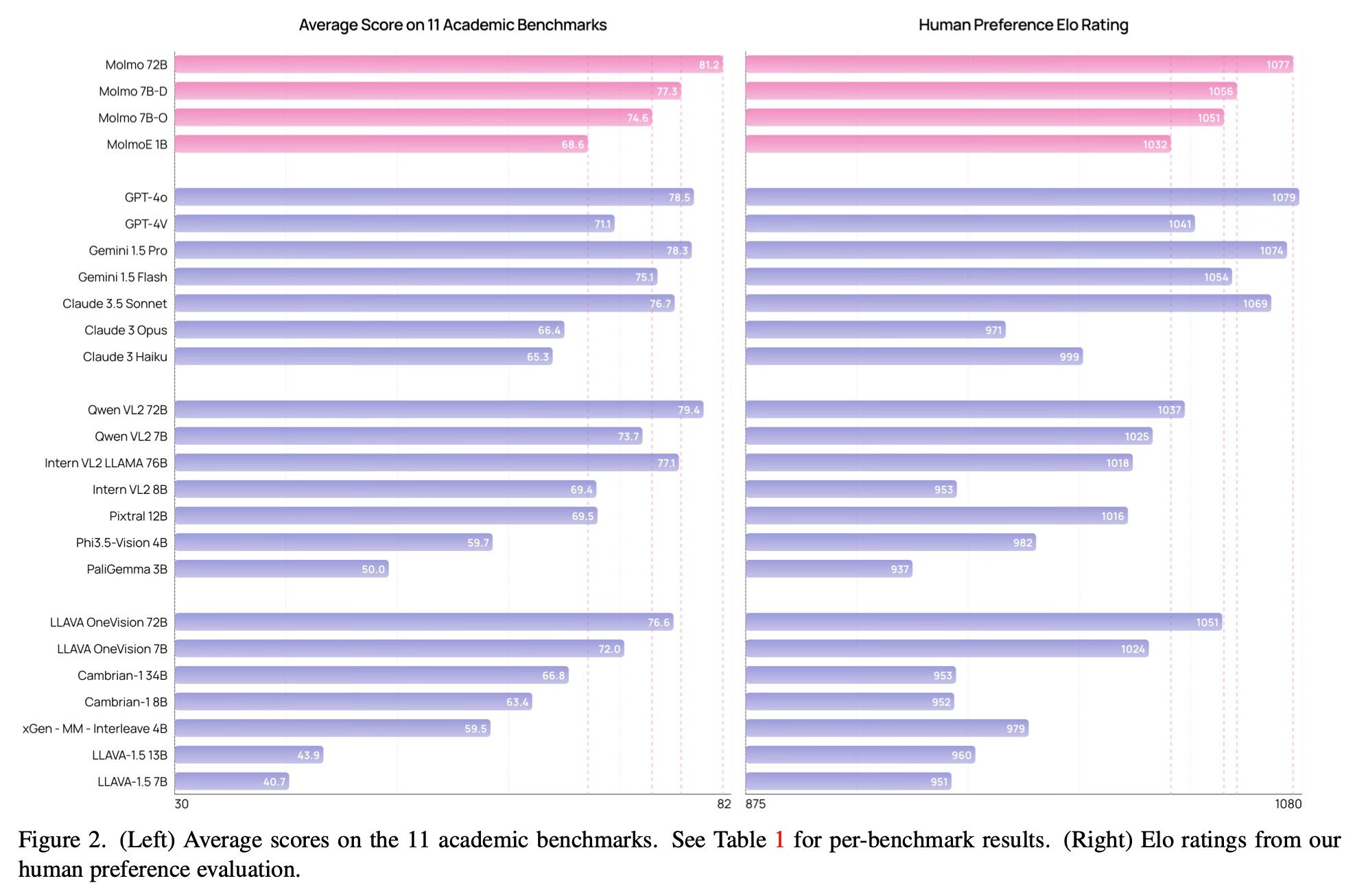
The most efficient model, MolmoE-1B, nearly matches the performance of GPT-4V on both academic benchmarks and user preference evaluations.
The 7B parameter models perform between GPT-4V and GPT-4o on both academic benchmarks and user preference rankings.
The best model, Molmo-72B, achieves the highest academic benchmark score and ranks second in user preference, just behind GPT-4o.
Molmo models outperform several state-of-the-art proprietary systems, including Gemini 1.5 Pro and Flash, and Claude 3.5 Sonnet.
On the AndroidControl benchmark, Molmo-72B demonstrates strong performance, highlighting its potential for real-world applications.
Conclusion
The paper introduces Molmo, a new family of multimodal LLMs. By using an interesting data collection method and focusing on high-quality, diverse datasets, Molmo achieve state-of-the-art performance. For more information please consult the full paper.
Congrats to the authors for their work!
Deitke, Matt, et al. "Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Multimodal Models." arXiv preprint arXiv:2409.15728 (2024).