

Multi-Head Mixture-of-Experts
Multi-Head Mixture-of-Experts

Today’s paper proposes Multi-Head Mixture-of-Experts (MH-MoE), a method to improve the expert activation and fine-grained understanding capabilities of Sparse Mixtures of Experts (SMoE) models. SMoE models activate distinct experts for specific input tokens to improve efficiency, but suffer from low expert utilization and lack of fine-grained analytical capabilities.
Method Overview
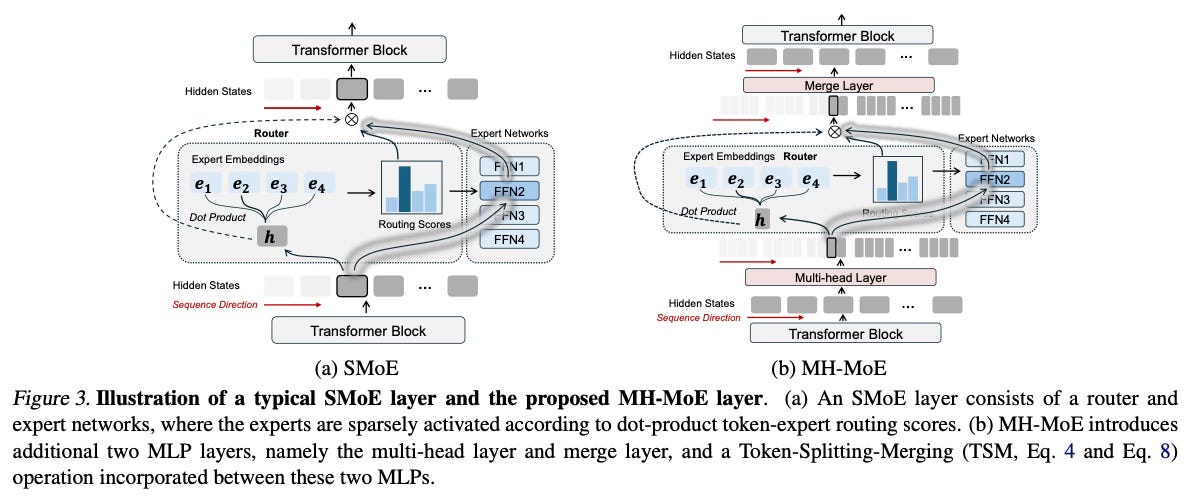
MH-MoE employs a multi-head mechanism to split each input token into multiple sub-tokens. These sub-tokens are then assigned to and processed by a diverse set of experts in parallel. After expert processing, the sub-tokens are seamlessly reintegrated into the original token form.

This multi-head token splitting approach enables MH-MoE to collectively attend to information from various representation spaces within different experts. It deepens the model's understanding of context while significantly enhancing expert activation, as each token activates multiple experts via its sub-tokens.
MH-MoE is straightforward to implement and decoupled from other SMoE optimization methods, making it easy to integrate with existing SMoE frameworks. The shapes of the input and output remain unchanged, so no additional computational cost is introduced in subsequent layers.
Results
The authors evaluate MH-MoE on three tasks: language understanding, multi-lingual understanding and multi-modal understanding.

Across all three settings, MH-MoE outperforms the SMoE baseline (X-MoE) and a dense model without experts. MH-MoE achieves denser expert activation (e.g. 90% vs 8% for X-MoE) and demonstrates finer-grained understanding capabilities, especially for ambiguous words and semantically rich image regions. Increasing the number of experts further improves MH-MoE's performance.

Conclusion
Multi-Head Mixture-of-Experts is an effective method to improve the expert utilization and representational power of Sparse Mixtures of Experts models. By splitting tokens into sub-tokens that activate different experts, MH-MoE enables the model to capture diverse information and achieve finer-grained understanding.For more information please consult the full paper.
Code: https://github.com/yushuiwx/MH-MoE
Congrats to the authors for their work!
Wu, Xun, et al. "Multi-Head Mixture-of-Experts." arXiv preprint arXiv:2404.15045 (2023).