

No "Zero-Shot" Without Exponential Data: Pretraining Concept Frequency Determines Multimodal Model Performance
No "Zero-Shot" Without Exponential Data: Pretraining Concept Frequency Determines Multimodal Model Performance

This paper investigates the relationship between the frequency of concepts in the pretraining datasets of multimodal models and the models' zero-shot performance on downstream tasks involving those concepts. The authors find that across a wide range of models and datasets, there is a consistent log-linear scaling trend between concept frequency and zero-shot performance, indicating that these models require exponentially more pretraining data to achieve linear improvements in downstream performance.
Method Overview
The authors analyze the concept frequencies and zero-shot performance of both image-text models (like CLIP) and text-to-image models (like Stable Diffusion). They define concepts as the specific objects or class categories targeted in downstream tasks. For image-text models, they look at 4,029 concepts sourced from 17 classification datasets, 2 retrieval datasets, and the text captions of 8 image generation datasets.

To estimate concept frequencies, the authors develop efficient algorithms to search for the concepts in the text captions and images of the pretraining datasets. For text, they use part-of-speech tagging and lemmatization to standardize word forms and enable fast indexing and searching. For images, they use an open-vocabulary multi-label tagging model called RAM++ to tag which concepts are present. By intersecting the image and text search results, they determine the frequency that each concept appears in an aligned image-text pair.
The authors then evaluate a range of CLIP and Stable Diffusion models on zero-shot classification, text-image retrieval, and text-to-image generation tasks to measure performance on the downstream concepts. By comparing the pretraining concept frequencies to the downstream performance, they are able to uncover the log-linear scaling trends.

Results
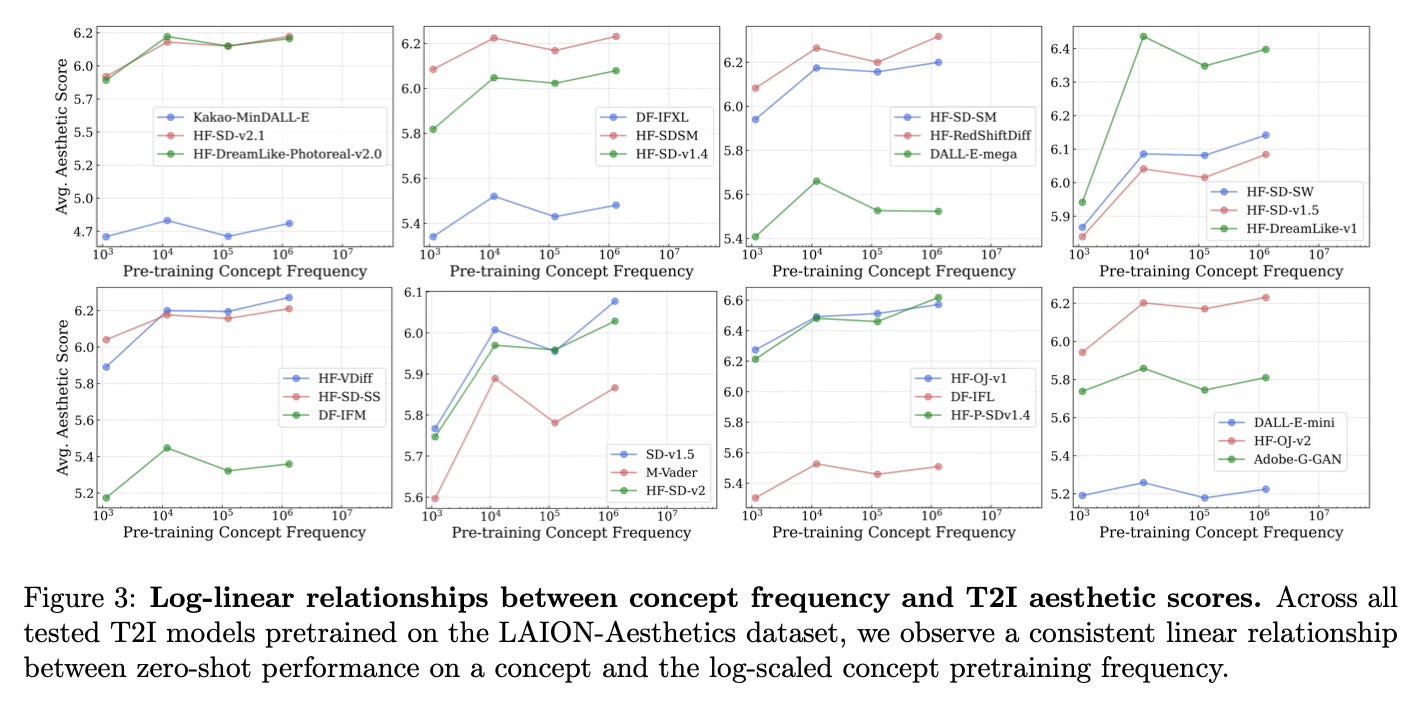
The key finding is the consistent log-linear relationship between the pretraining frequency of a concept and a model's zero-shot performance on that concept.
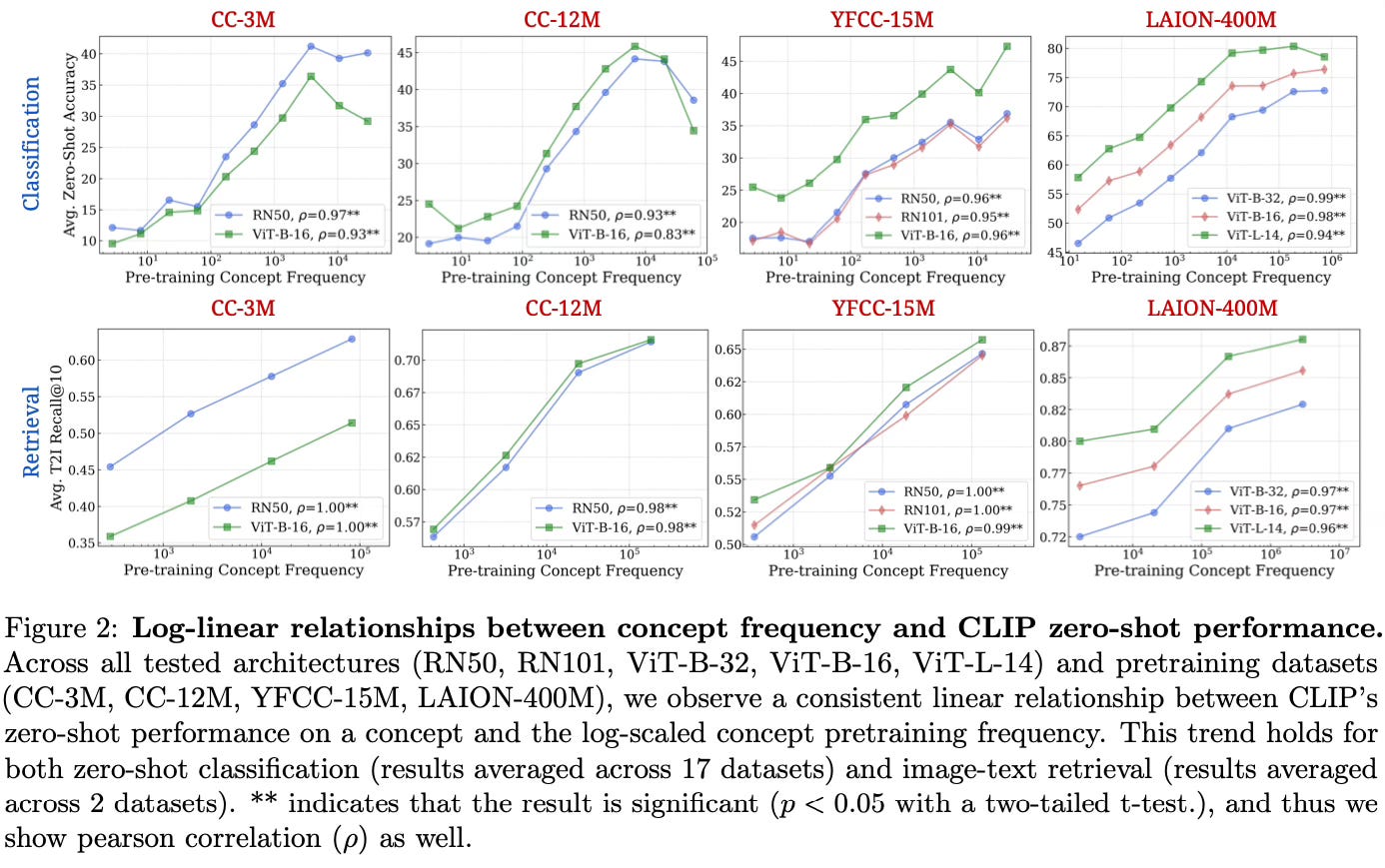
This scaling trend holds across:
- Both discriminative (CLIP) and generative (Stable Diffusion) models
- Different model architectures and scales
- Different pretraining datasets
- Different downstream tasks (classification, retrieval, generation)
- Different performance metrics
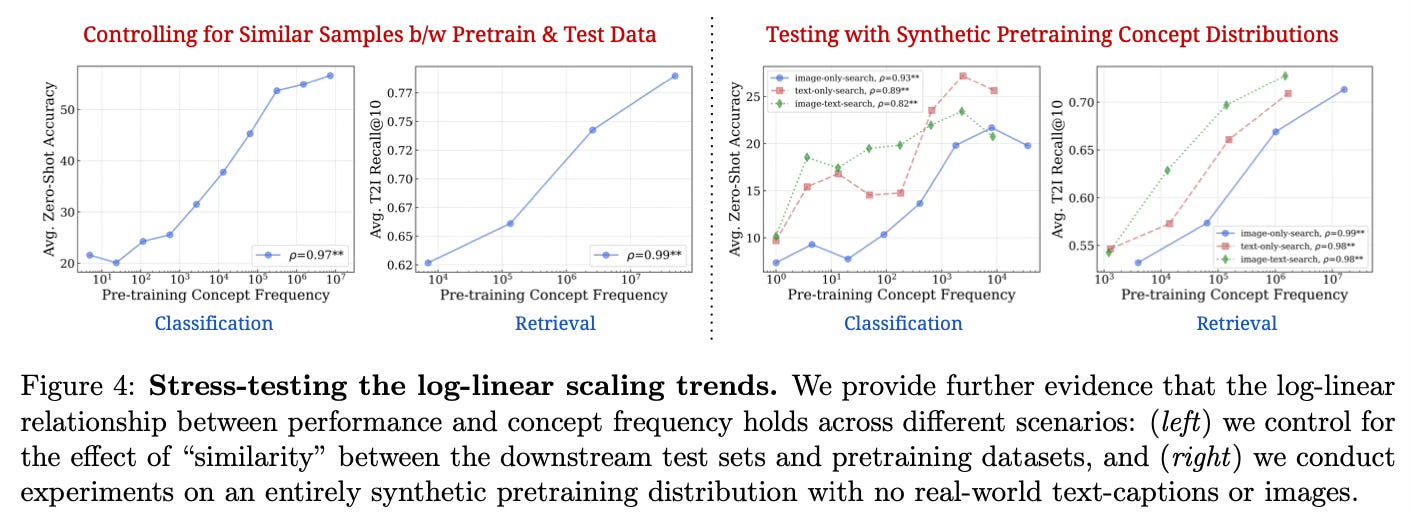
- Controlling for pretraining/test set similarity
- Testing on purely synthetic data distributions
The authors also find that the pretraining concept distributions are extremely long-tailed, with significant misalignment between concepts appearing in images vs text. To further test the impact of the long-tailed distributions, they create a new benchmark called "Let It Wag!" focused on rare concepts. Current models significantly underperform on this benchmark compared to more balanced datasets like ImageNet.


Conclusion
This work reveals that current multimodal models require exponentially increasing amounts of pretraining data to make linear improvements on downstream tasks, following a sample-inefficient log-linear scaling law. The authors conclude that the impressive "zero-shot" capabilities of models like CLIP and Stable Diffusion can be largely attributed to the presence of test concepts in their large pretraining datasets, rather than an inherent ability to perform "zero-shot" generalization. For more information please consult the full paper.
Code: https://github.com/bethgelab/frequency_determines_performance
Data: https://huggingface.co/datasets/bethgelab/Let-It-Wag
Congrats to the authors for their work!
Udandarao, Vishaal, et al. "No “Zero-Shot” Without Exponential Data: Pretraining Concept Frequency Determines Multimodal Model Performance." arXiv preprint arXiv:2404.04125 (2024).