

Rho-1: Not All Tokens Are What You Need
Rho-1: Not All Tokens Are What You Need

This paper introduces a new language model called RHO-1 that employs Selective Language Modeling (SLM). Unlike traditional language models that learn to predict every next token in a corpus, RHO-1 selectively trains on useful tokens that align with the desired distribution. The main idea is that not all tokens in a corpus are equally important for language model training.
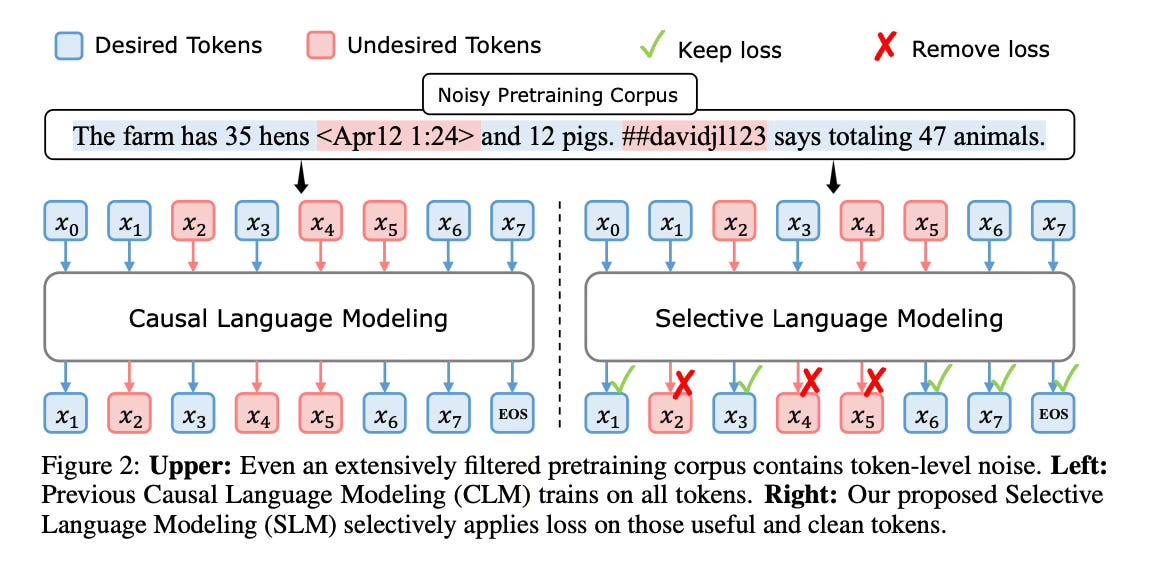
Method Overview
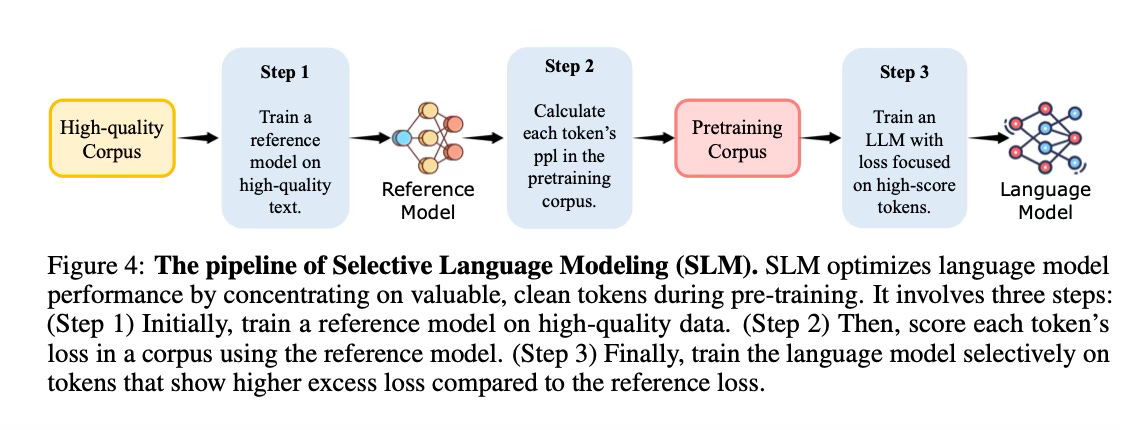
The Selective Language Modeling approach involves three main steps:
1. Train a reference model on a curated, high-quality dataset that reflects the desired data distribution. This reference model is used to assess the token loss within a larger pretraining corpus.
2. Score each token in the pretraining corpus using the reference model. The reference loss of a token is computed based on the probability the reference model assigns to that token. This establishes a reference for selective pretraining, allowing the focus to be on the most influential tokens.
3. Train the language model selectively, focusing the loss on tokens that exhibit a high excess loss compared to the reference model. The excess loss for a token is defined as the difference between the current training model loss and the reference loss. A token selection ratio determines the proportion of tokens to include based on their excess loss. The intuition is that tokens with high excess loss are more learnable and better aligned with the desired distribution, naturally excluding irrelevant or low quality tokens.
By selectively applying the loss only to tokens deemed most beneficial, RHO-1 optimizes the learning process. The full sequence is still input to the model, but the loss is removed for undesired tokens without additional cost.
Results
When continual pretraining on a 15B OpenWebMath corpus, RHO-1 yields an absolute improvement in few-shot accuracy of up to 30% on 9 math tasks compared to traditional language modeling.
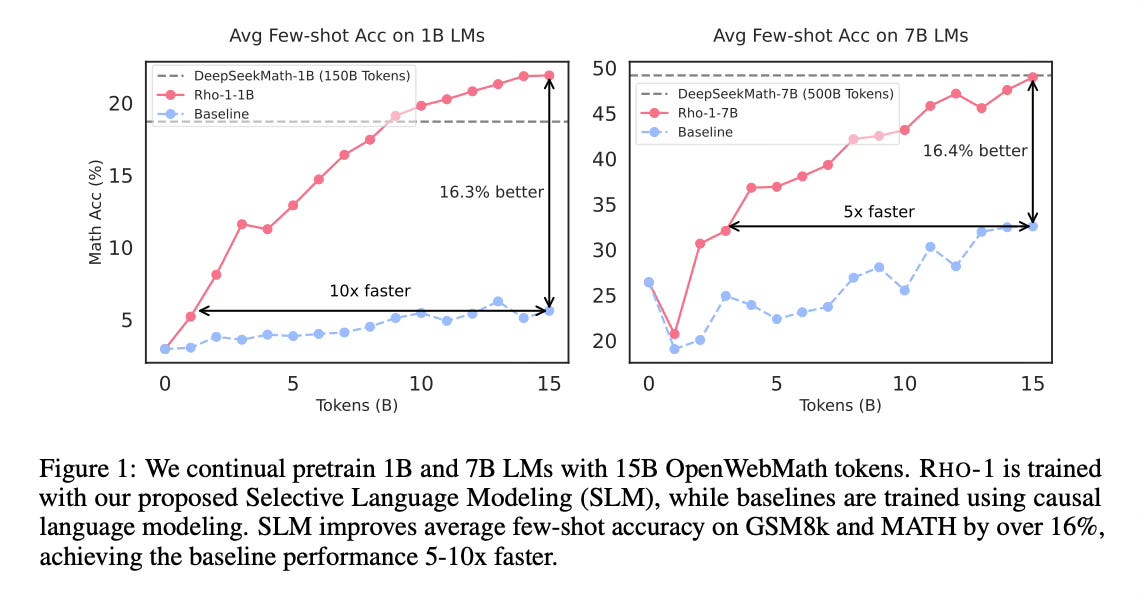
After fine-tuning, RHO-1-1B and 7B achieved state-of-the-art results compared to models of similar size on various datasets.

Furthermore, when pretraining on 80B general tokens, RHO-1 achieves a 6.8% average enhancement across 15 diverse tasks, increasing both efficiency and performance compared to standard pretraining.

Conclusion
RHO-1 introduces a novel Selective Language Modeling approach that significantly enhances token efficiency during pretraining and improves downstream task performance. By selectively focusing the training on the most influential tokens as determined by a reference model, RHO-1 optimizes the learning process and achieves strong results in both math and general domains with a fraction of the pretraining tokens. For more information please consult the full paper or the project page.
Model: https://huggingface.co/microsoft/rho-math-1b-v0.1
Congrats to the authors for their work!
Lin, Zhenghao, et al. "RHO-1: Not All Tokens Are What You Need." arXiv preprint arXiv:2404.07965 (2024).