

Scaling Synthetic Data Creation with 1,000,000,000 Personas
Scaling Synthetic Data Creation with 1,000,000,000 Personas

Today's paper introduces Persona Hub, a collection of 1 billion diverse personas automatically curated from web data, and proposes a novel persona-driven data synthesis methodology. This approach enables the creation of diverse synthetic data at scale for various scenarios, potentially revolutionizing synthetic data creation and applications in practice.

Method Overview
The core idea of the paper is to use personas to steer LLMs towards creating diverse synthetic data. The authors introduce Persona Hub, a collection of 1 billion diverse personas automatically curated from web data. These personas act as distributed carriers of world knowledge and can tap into almost every perspective encapsulated within an LLM.
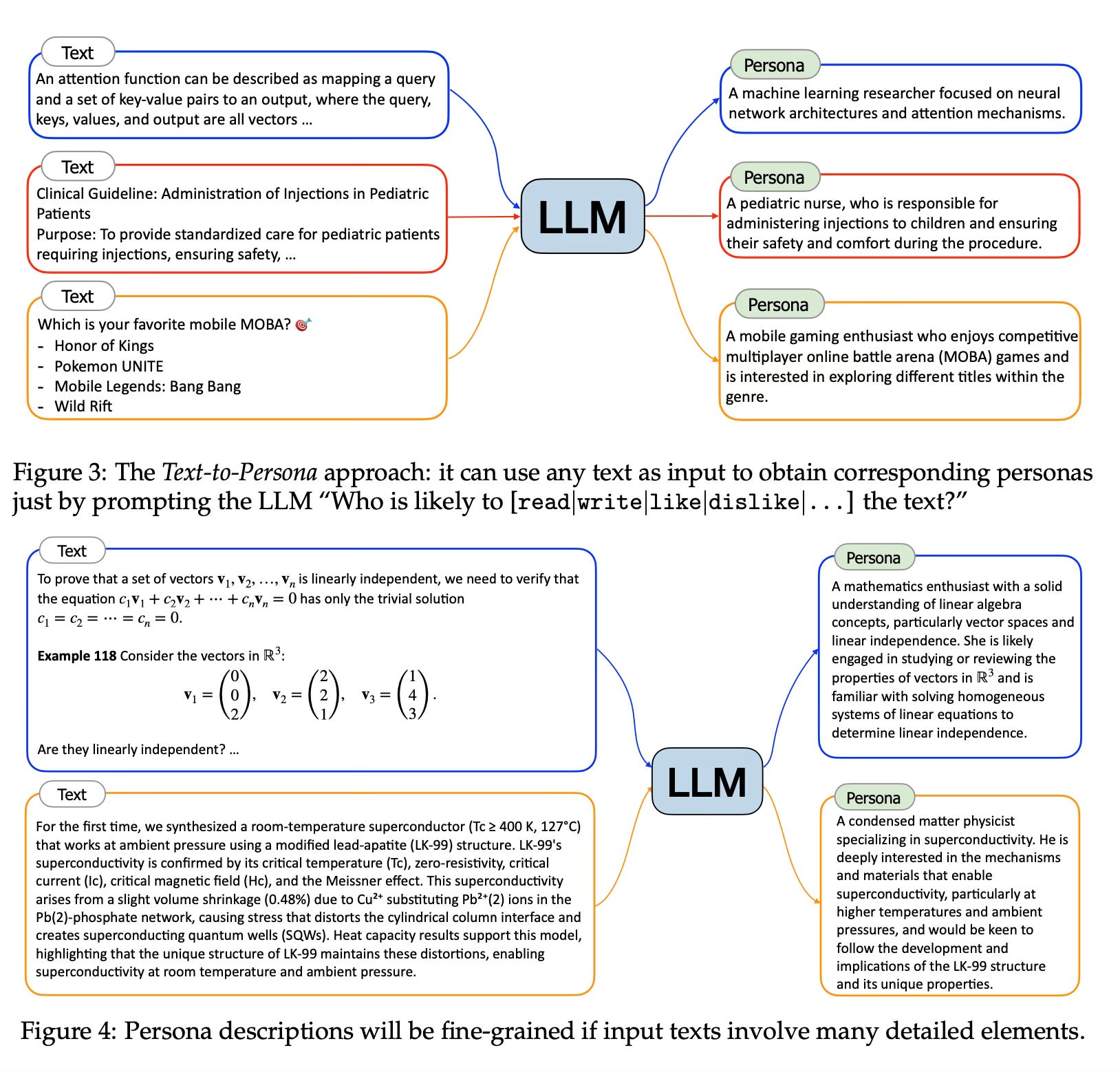
The method involves two main approaches to derive personas:
Text-to-Persona: This approach uses web text data to infer personas who are likely to read, write, like, or dislike the text. By applying this method to massive web text data, billions of diverse personas can be obtained.
Persona-to-Persona: This method derives new personas based on interpersonal relationships with existing personas. It helps to supplement personas that might be missed by the Text-to-Persona approach.
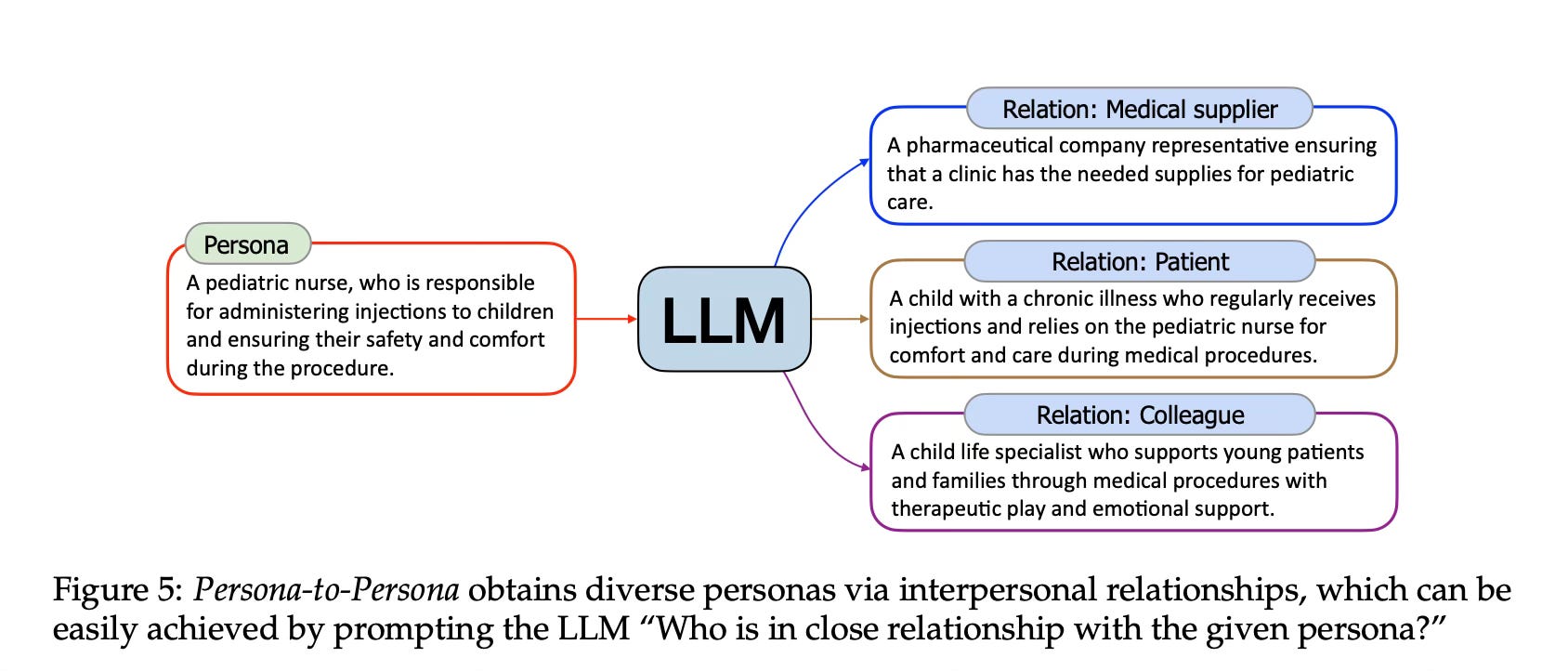
After obtaining the personas, the authors use a deduplication process to ensure diversity in the Persona Hub. The persona-driven data synthesis methodology then integrates a persona into a data synthesis prompt, guiding the LLM to adopt the persona's perspective when creating synthetic data.

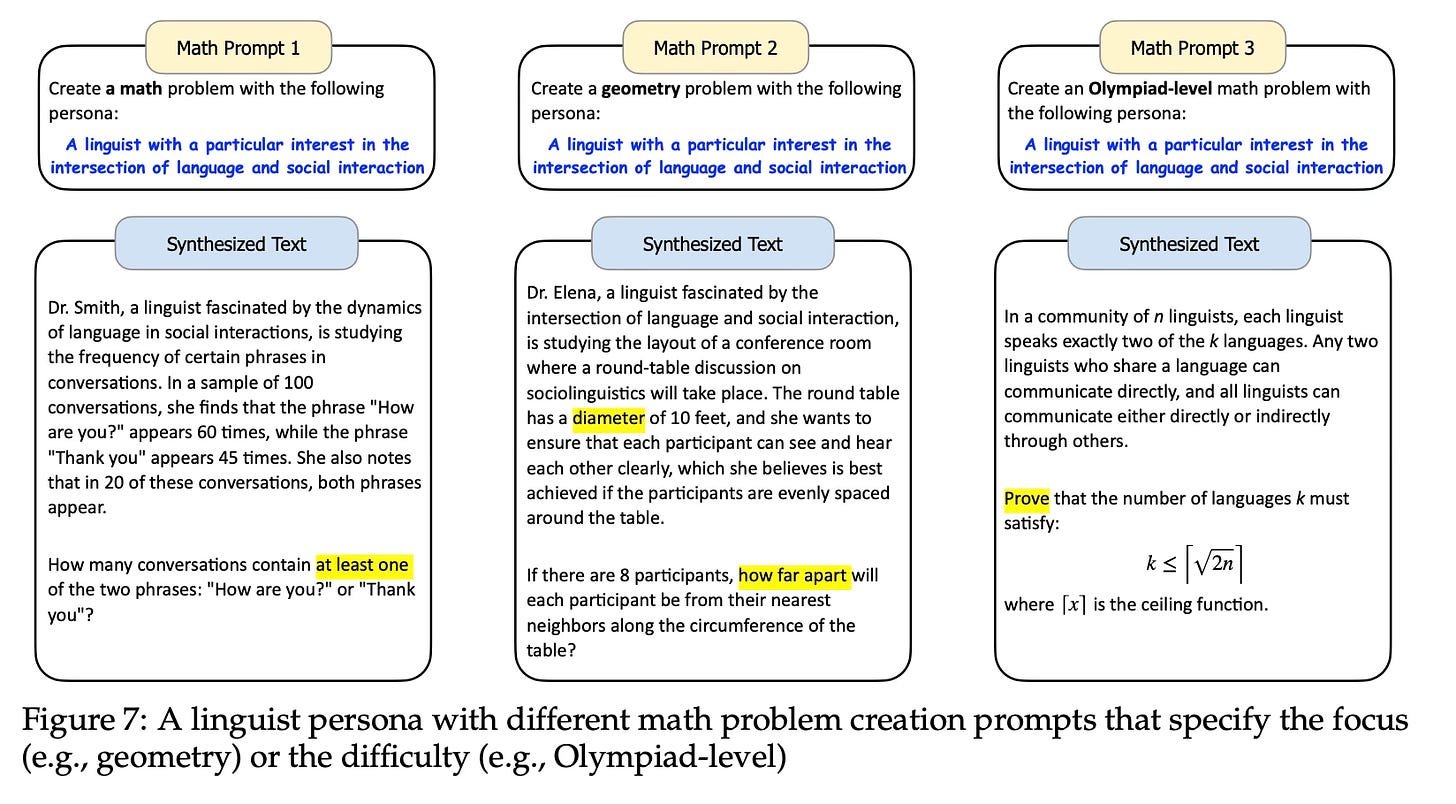
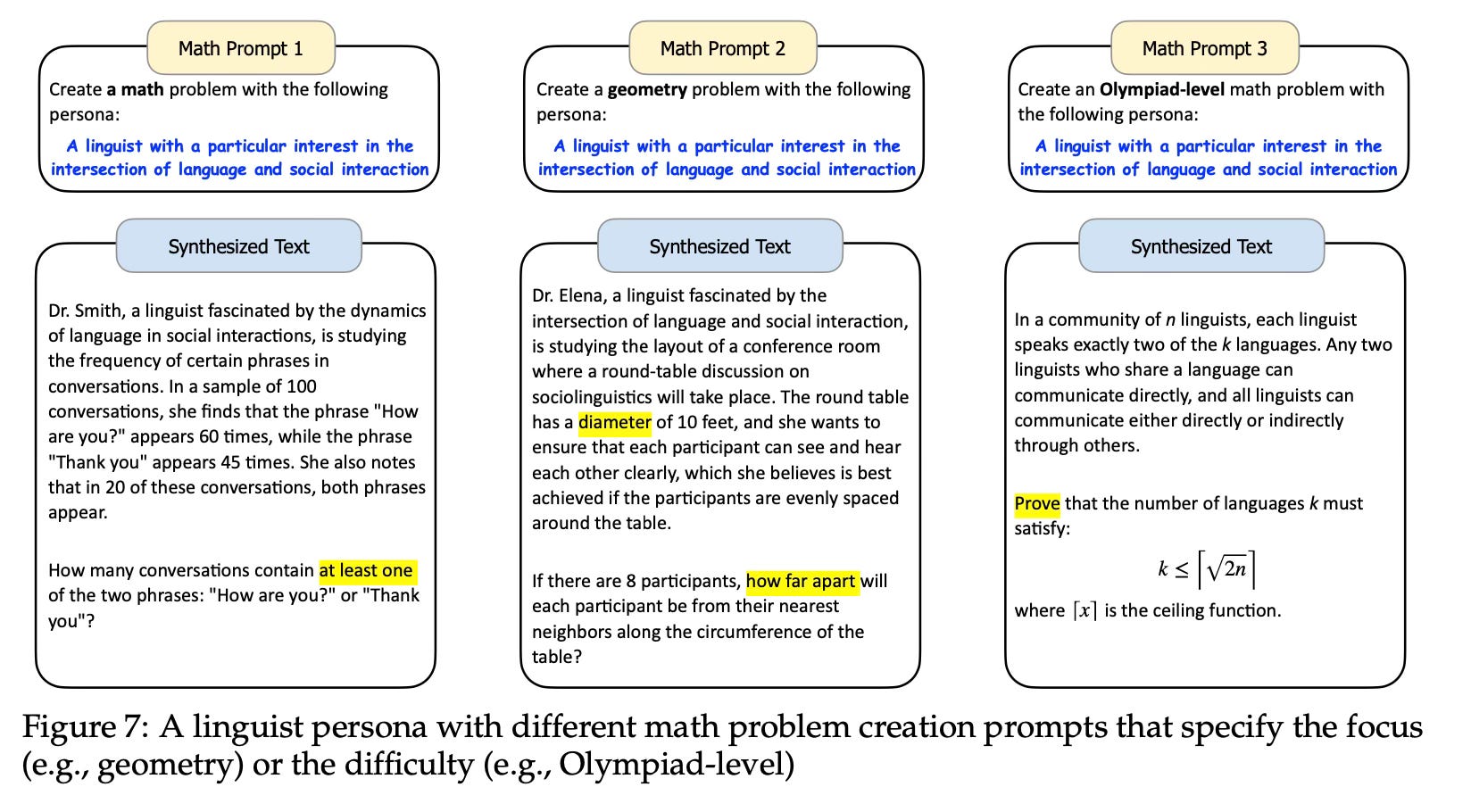
The paper demonstrates the versatility of this approach by showcasing its use in creating various types of synthetic data, including math problems, logical reasoning problems, instructions (user prompts), knowledge-rich texts, game NPCs, and tool (function) development.
Results
The paper presents several key results:
The method successfully created 1.09 million math problems using personas from Persona Hub.
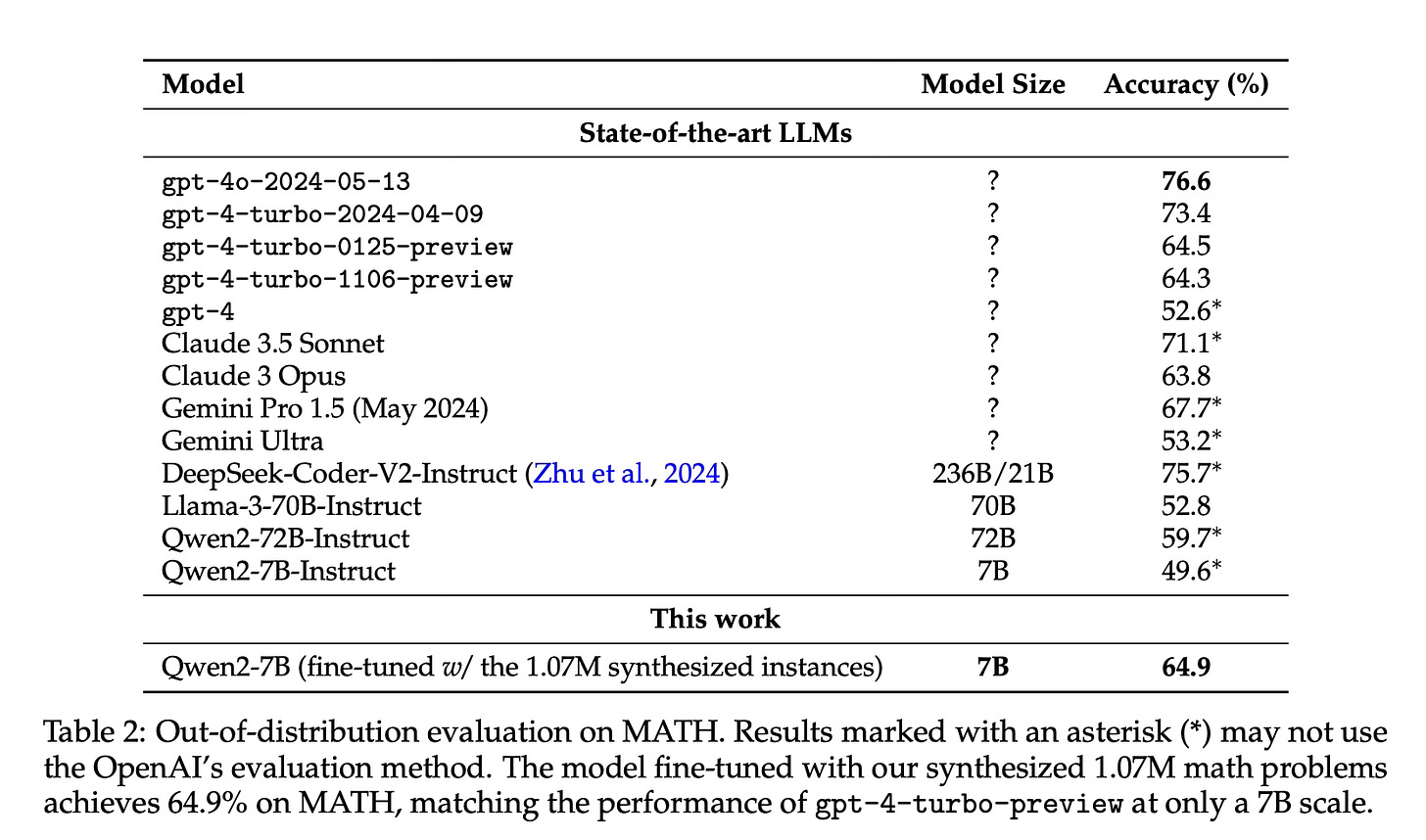
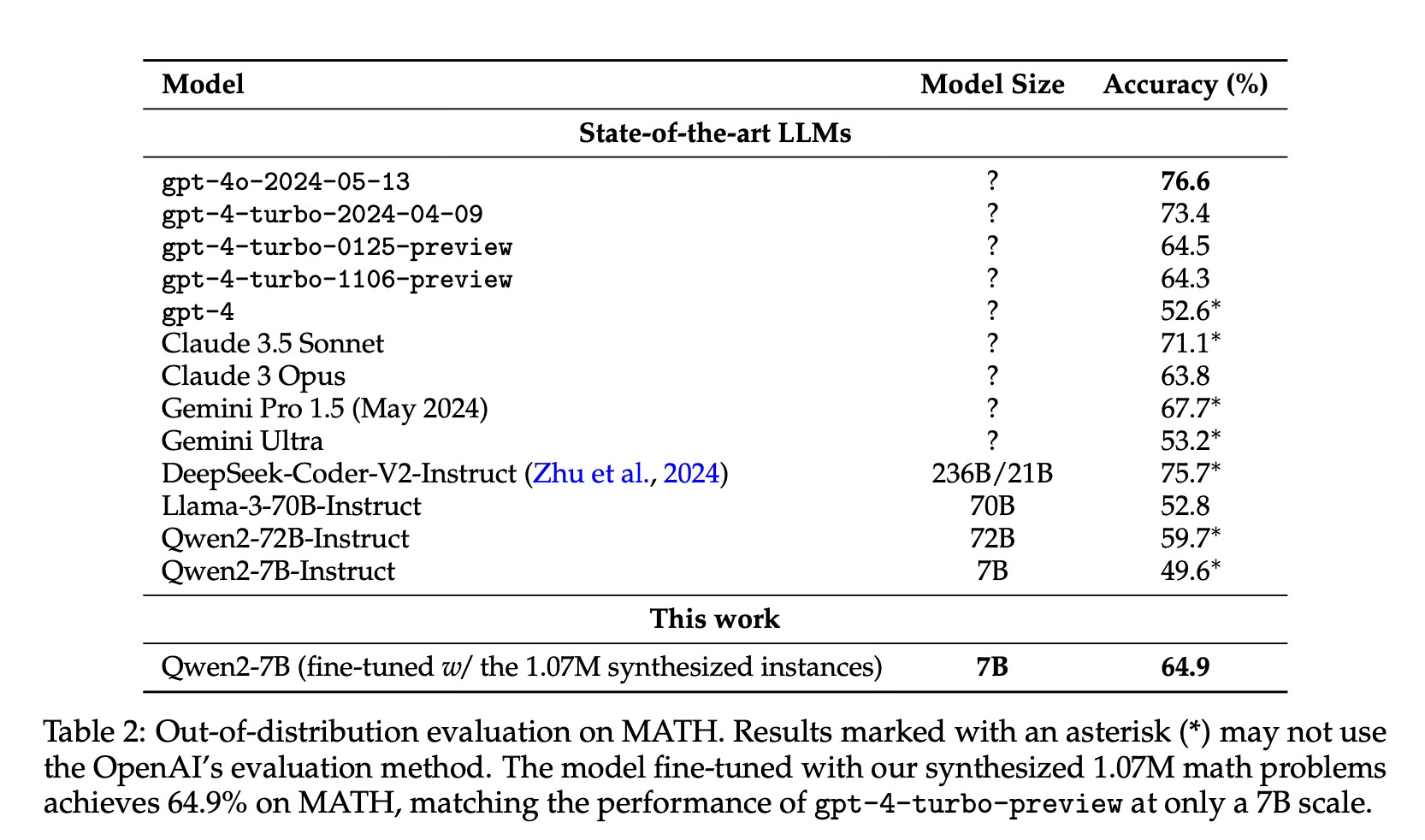
A 7B parameter model fine-tuned on the synthetic math problems achieved 64.9% accuracy on the MATH benchmark, matching the performance of GPT-4-turbo-preview.
The approach demonstrated effectiveness in creating diverse synthetic data for various scenarios, including logical reasoning problems, instructions, knowledge-rich texts, game NPCs, and tool development.
Conclusion
The paper introduces a new persona-driven data synthesis methodology and Persona Hub. This approach offers a scalable and flexible solution for creating diverse synthetic data across various scenarios. For more information please consult the full paper.
Congrats to the authors for their work!
Chan, Xin, et al. "Scaling Synthetic Data Creation with 1,000,000,000 Personas." arXiv preprint arXiv:2406.20094 (2024).