

Training Language Models to Self-Correct via Reinforcement Learning
Training Language Models to Self-Correct via Reinforcement Learning

Today's paper introduces SCoRe, a new approach for training large language models (LLMs) to self-correct their own mistakes. The method uses multi-turn reinforcement learning to teach LLMs how to revise their initial responses and produce improved final outputs, without relying on external feedback or multiple models. SCoRe achieves state-of-the-art performance in self-correction on math and coding tasks.
Method Overview
SCoRe (Self-Correction via Reinforcement Learning) uses a two-stage approach to train LLMs for self-correction.
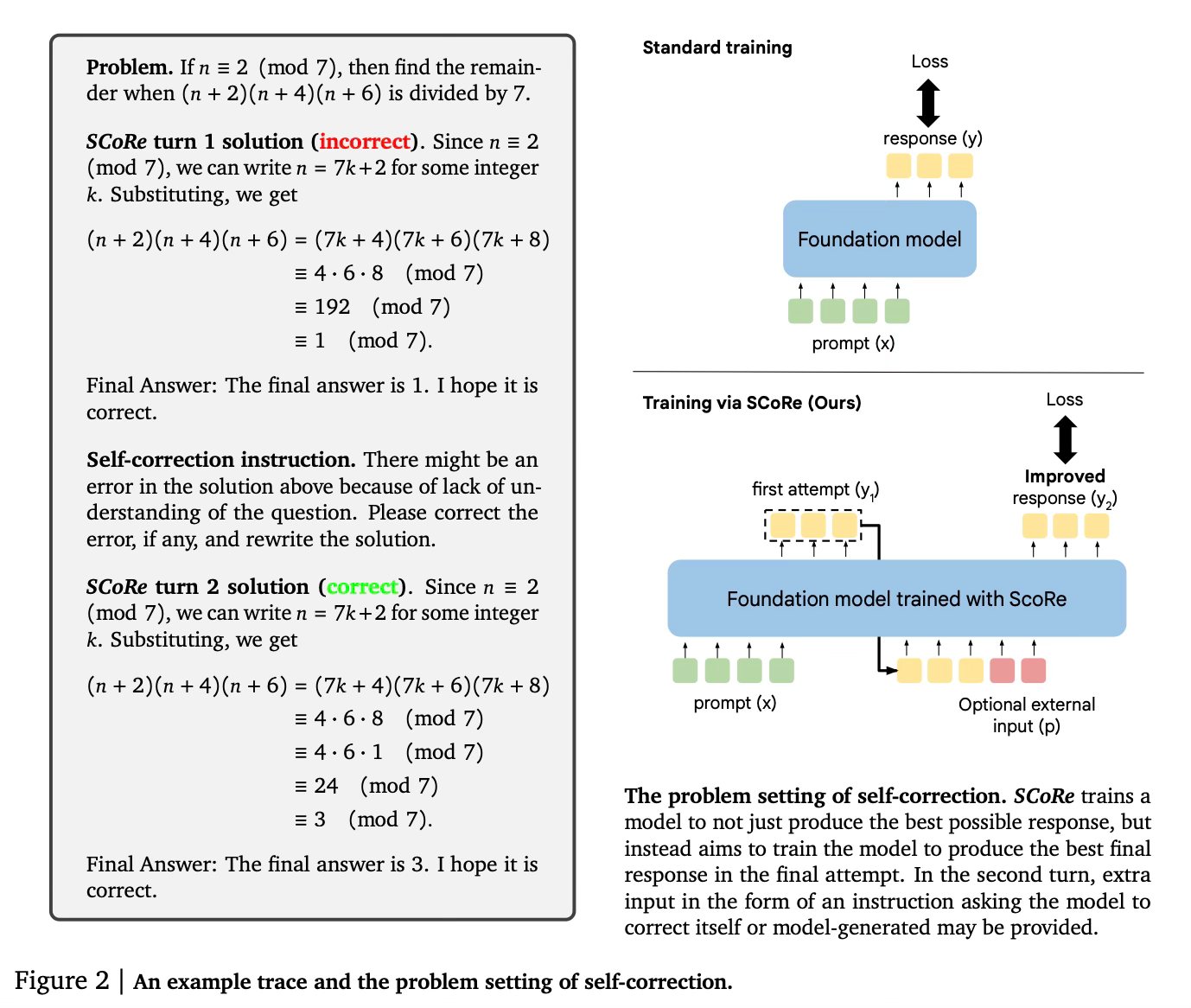
In the first stage, the method trains a model initialization that can produce high-reward revisions in the second attempt, while keeping the first-attempt responses similar to the base model. This helps prevent the model from simply coupling its first and second responses tightly together.
The second stage uses multi-turn reinforcement learning to jointly optimize both the first and second attempts. Importantly, it uses reward shaping to incentivize the model to learn a true self-correction strategy rather than just optimizing for the best first response. The reward bonus encourages the model to improve its second response compared to the first.
A key insight is that the method needs to make it more attractive for the model to learn the nuanced self-correction strategy rather than collapsing to simpler but less generalizable behaviors. By training on self-generated online data, SCoRe also avoids issues with distribution shift that can occur when training on fixed offline datasets.
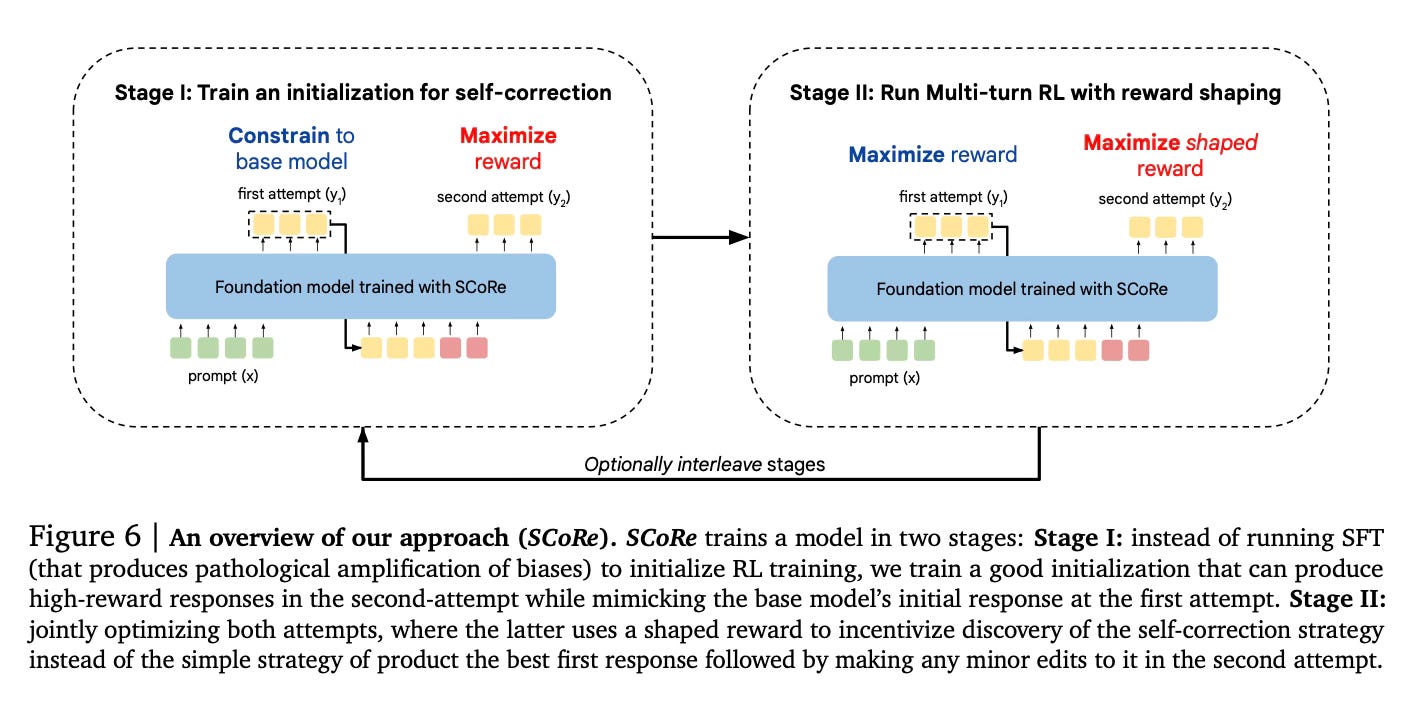
The two-stage approach, reward shaping, and online training all work together to guide the model towards learning effective self-correction abilities that generalize to new problems at test time.
Results
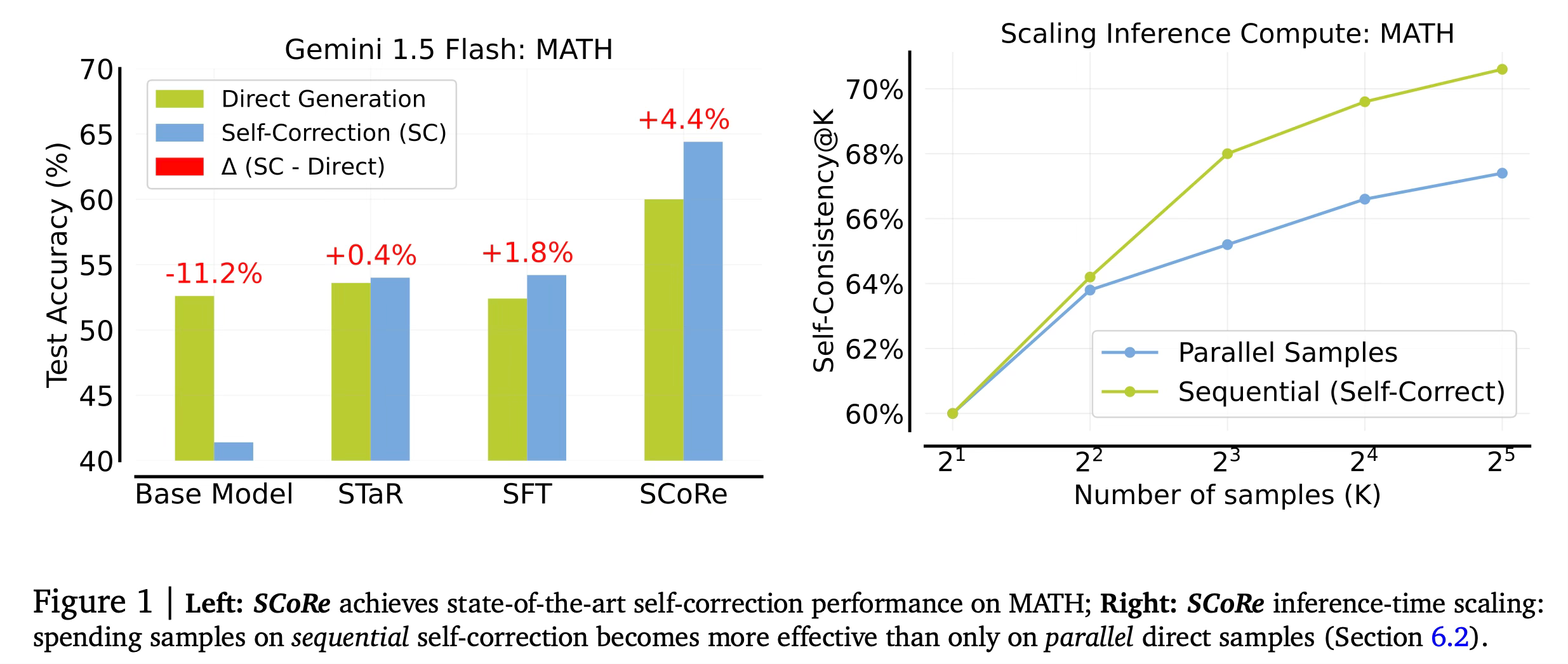
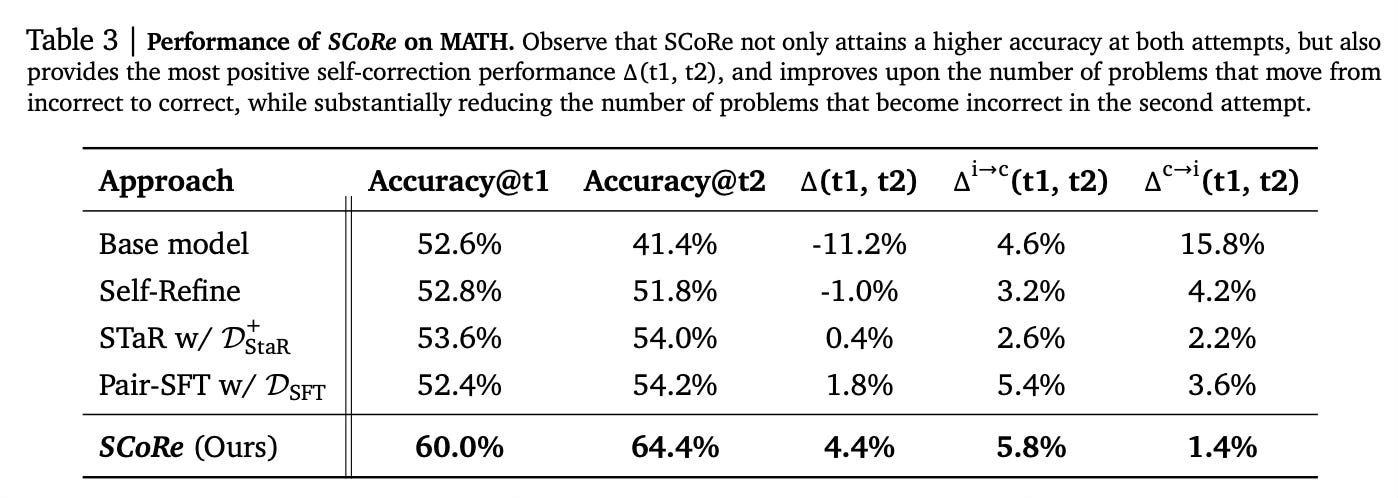
SCoRe achieved state-of-the-art self-correction performance on math and coding benchmarks:
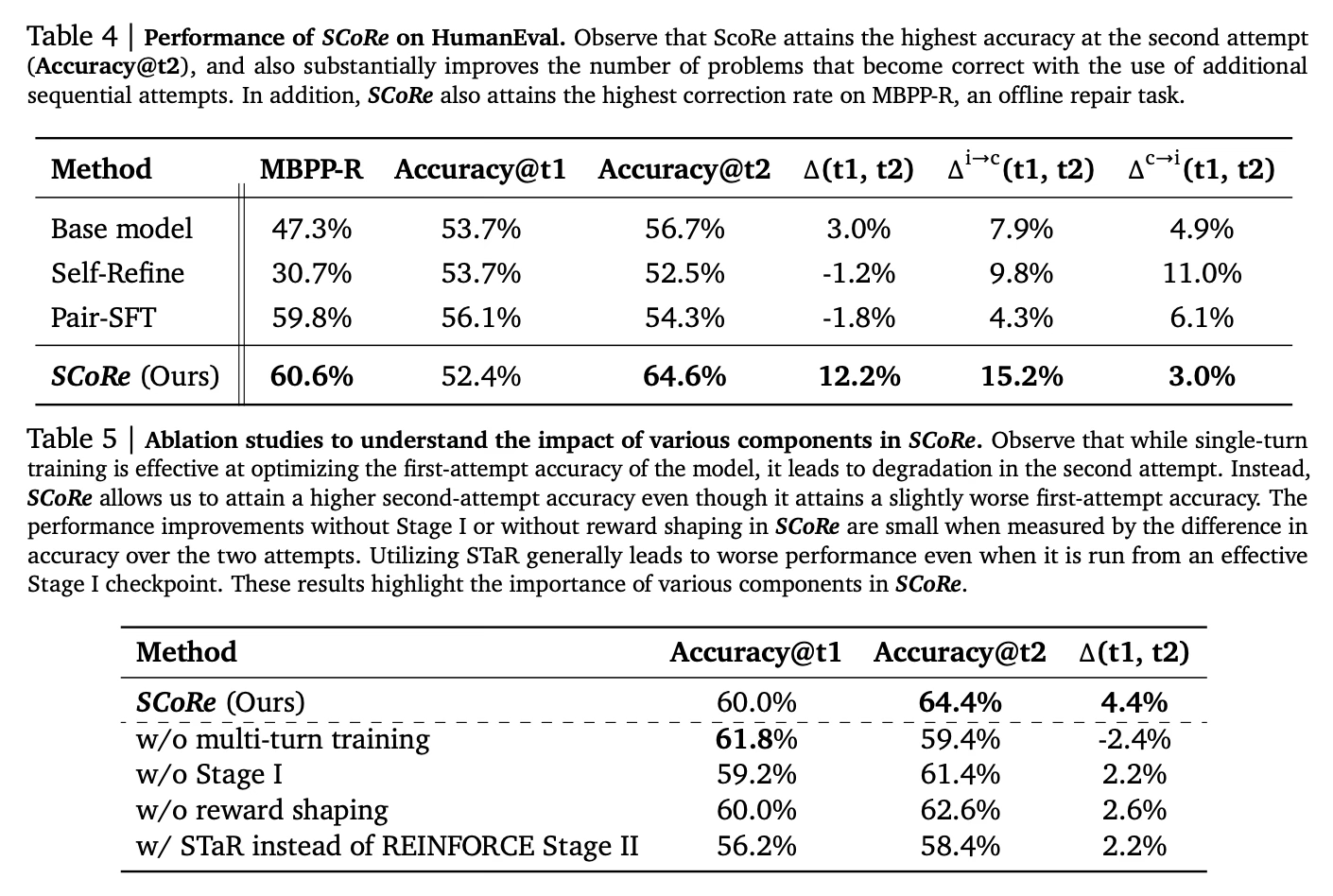
On the MATH dataset, it improved the base model's self-correction by 15.6% absolute.
On HumanEval coding tasks, it improved self-correction by 9.1% absolute over the base model.
SCoRe was the first method to achieve significantly positive intrinsic self-correction, meaning the second attempt was consistently better than the first.
It also improved offline code repair performance on MBPP-R by over 13% compared to the base model.
Conclusion
This paper introduces SCoRe, a novel multi-turn reinforcement learning approach for teaching LLMs to effectively self-correct their own mistakes. By carefully designing the training process to incentivize true self-correction strategies, SCoRe achieves state-of-the-art performance on math and coding tasks without relying on external feedback or multiple models. For more information please consult the full paper.
Congrats to the authors for their work!
Kumar, Aviral, et al. "Training Language Models to Self-Correct via Reinforcement Learning." arXiv preprint arXiv:2409.12917 (2024).