

Vibe-Eval: A hard evaluation suite for measuring progress of multimodal language models
Vibe-Eval: A hard evaluation suite for measuring progress of multimodal language models

Today’s paper introduces Vibe-Eval, a challenging new benchmark for evaluating the capabilities of multimodal language models on open-ended visual understanding tasks.

Overview
Vibe-Eval consists of 269 image-text prompts, each with a corresponding human-written reference response. The prompts are divided into a "normal" set of 169 prompts representing day-to-day tasks, and a "hard" set of 100 prompts that the current state-of-the-art model Reka Core cannot solve.

The prompts require open-ended reasoning about the provided image. Many of the hard prompts involve multiple reasoning steps to arrive at the final answer. The reference responses often include the step-by-step reasoning process, allowing evaluators to assign partial credit.

For the official evaluation protocol, the multimodal Reka Core model is used as an automated evaluator. Given the prompt, a model's generated response, and the reference response, Reka Core provides a rating from 1-5 indicating how well the generation matches the reference. A high rating indicates the model fully solved the task, while lower ratings are given for partial solutions or incorrect responses.

Results
The paper reports Vibe-Eval scores for 13 multimodal language models using the automated Reka Core evaluator. Overall, Gemini Pro 1.5 performed best, followed by GPT-4V and Reka Core itself. Open-source models like LLaVA and Idefics tended to score lower.
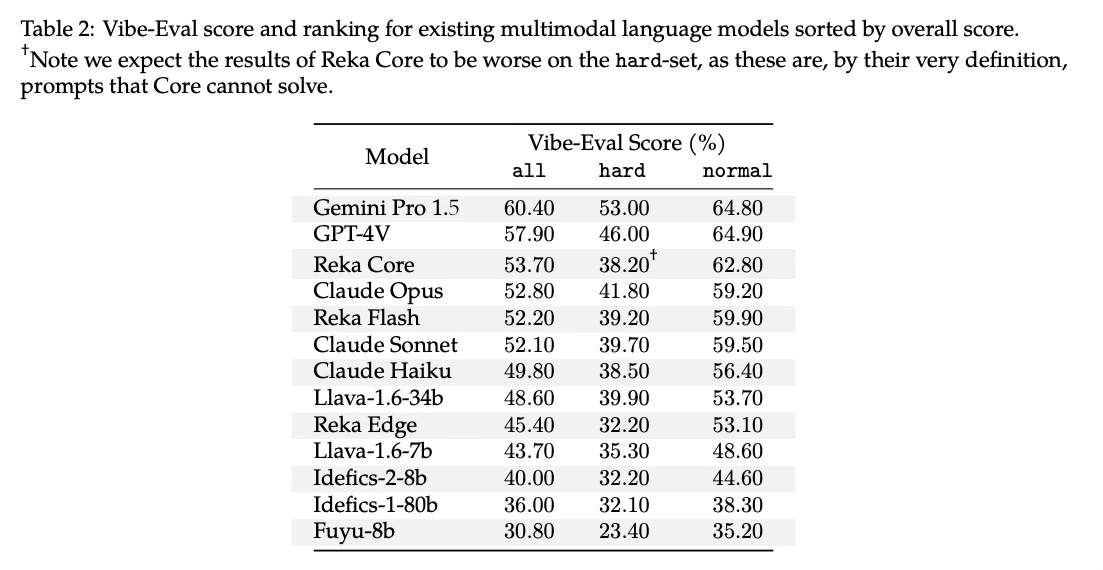
On the hard subset specifically, Gemini Pro 1.5 and GPT-4V remained the top performers, with the Claude models outperforming Reka Core. The 34B LLaVA model also did relatively well on this hard subset.
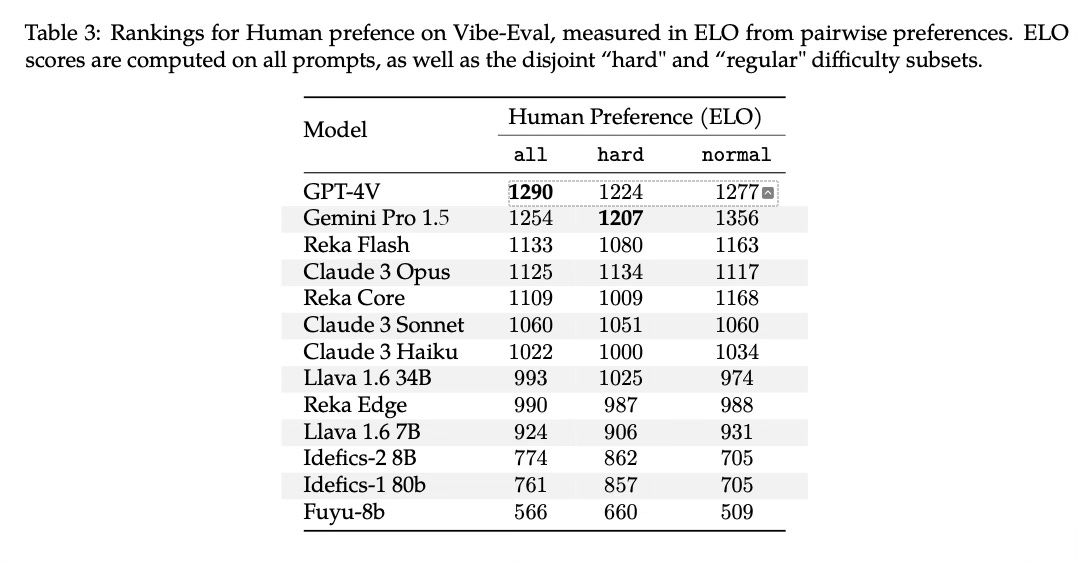
The paper also includes results from a human evaluation study, which showed broadly similar rankings, with GPT-4V slightly outperforming Gemini Pro 1.5 overall based on human preferences.

Conclusion
Vibe-Eval is a challenging multimodal benchmark containing many prompts unsolvable by current models, allowing it to probe the limits of frontier models' capabilities. The authors plan to periodically extend it with even harder examples. For more information please consult the full paper.
Code: https://github.com/reka-ai/reka-vibe-eval
Congrats to the authors for their work!
Reka Team, "Vibe-Eval: A Hard Evaluation Suite for Measuring Progress of Multimodal Language Models." arXiv, 2024.