

VideoGuide: Improving Video Diffusion Models without Training Through a Teacher's Guide
VideoGuide: Improving Video Diffusion Models without Training Through a Teacher's Guide

Today's paper introduces VideoGuide, a new framework for improving the temporal consistency of pretrained text-to-video diffusion models without additional training. The method leverages any pretrained video diffusion model as a guide during the early stages of inference, significantly enhancing temporal quality while preserving imaging quality and motion smoothness. This approach allows for combining the strengths of various video diffusion models in a plug-and-play fashion.

Method Overview
VideoGuide works by incorporating a guiding process into the early stages of the video generation pipeline. The method starts with any pretrained video diffusion model as the base sampling model. During the initial steps of the reverse diffusion process, it introduces a second "guiding" video diffusion model.
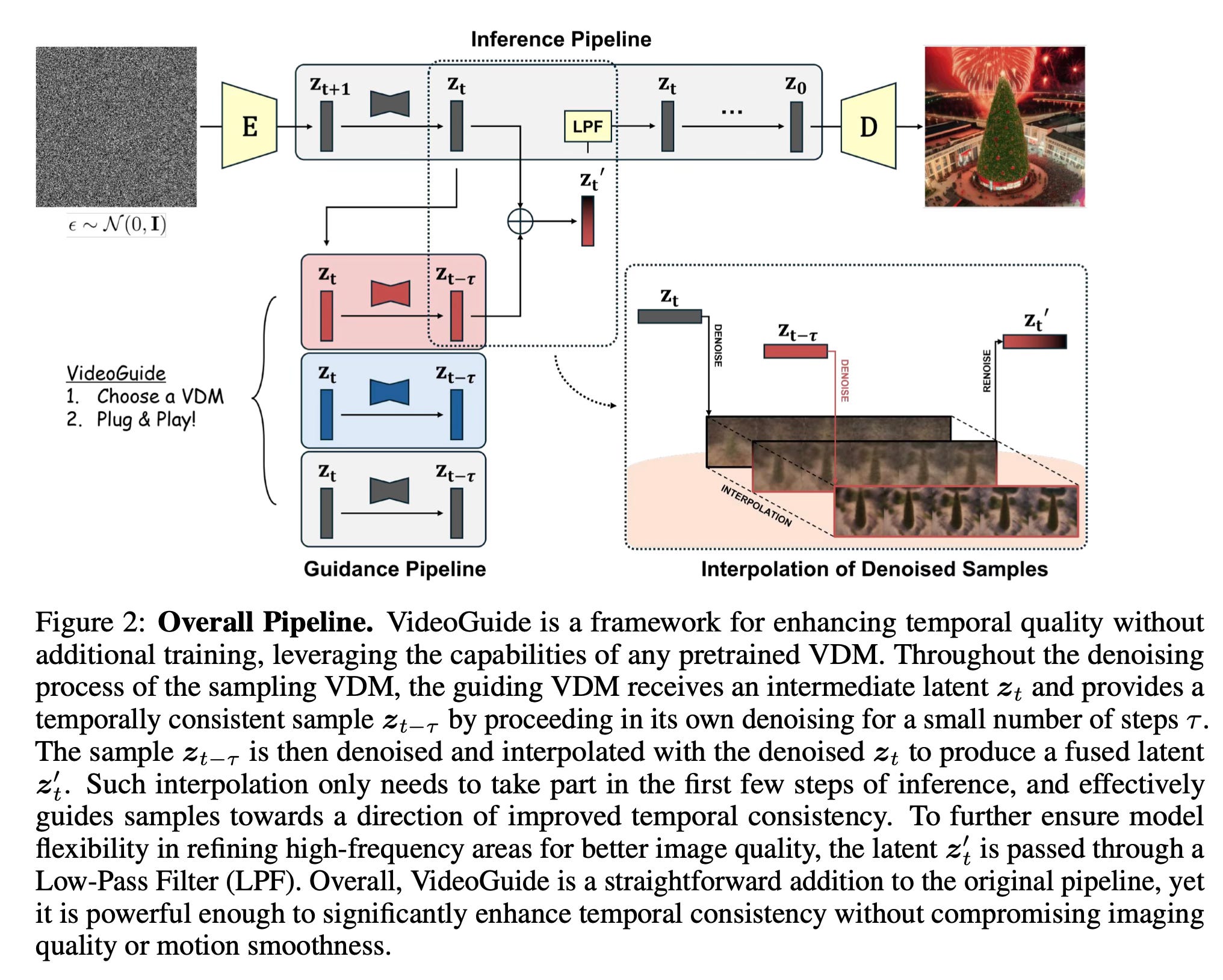
The guiding model receives the intermediate latent representation from the sampling model and processes it for a small number of denoising steps. This produces a more temporally consistent sample. The method then interpolates between this guided sample and the original sample from the base model. This interpolated result is used to continue the denoising process in the base model.
Importantly, this guidance and interpolation only occurs during the early timesteps of the generation process. This allows the method to steer the overall trajectory towards better temporal consistency while still preserving the unique capabilities of the base model in later stages.
The paper also introduces a regularization term specifically designed to enhance temporal consistency. It formulates the denoising process as an optimization problem that balances fidelity to the original sample with consistency to a temporally coherent reference.
VideoGuide can use the same model for both sampling and guidance (self-guided case) or leverage an external, potentially more advanced model as the guide (external-guided case). This flexibility allows for combining the strengths of different models - for example, using a model with strong temporal consistency to guide one with unique personalization capabilities.
Results
VideoGuide significantly improves temporal consistency across multiple base models and text prompts. Quantitative evaluations show improvements in metrics for subject consistency, background consistency, and motion smoothness. Importantly, these gains come without sacrificing image quality, unlike some previous approaches.
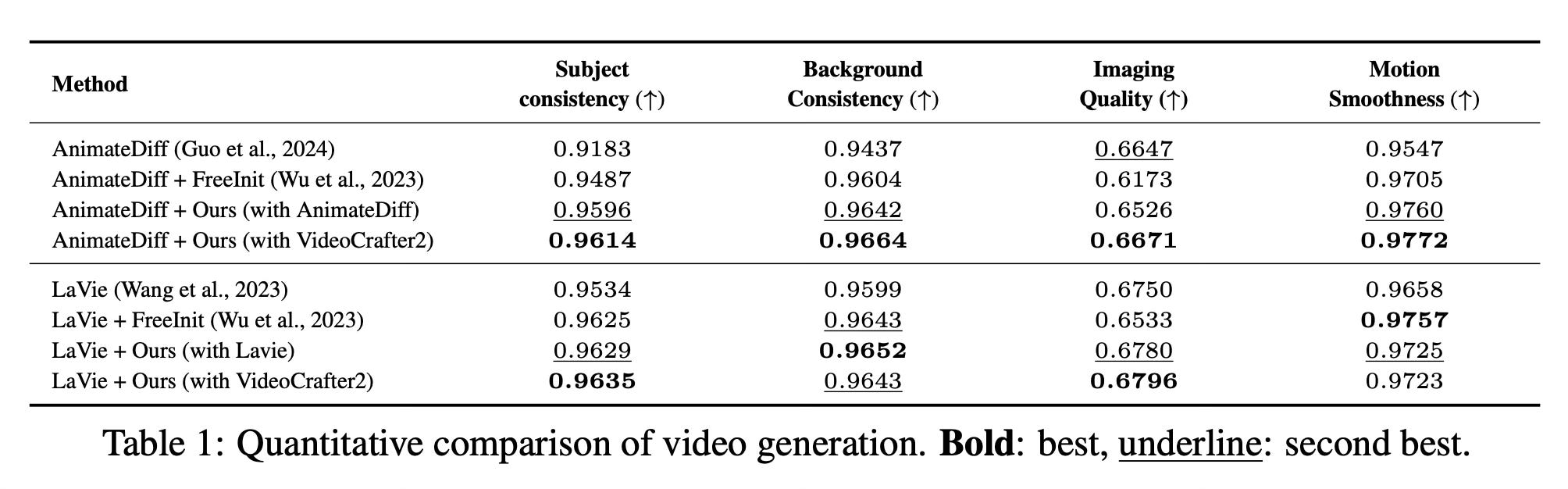
The method also proves computationally efficient, offering 1.8 to 3.1 times faster inference compared to iterative refinement techniques. Additionally, VideoGuide exhibits a "prior distillation" effect, allowing models to leverage the superior data distributions of guiding models to improve text coherence and generate more diverse content.

Conclusion
VideoGuide offers a versatile, training-free approach to enhance the temporal quality of text-to-video diffusion models. By leveraging guidance from pretrained models during early inference stages, it achieves significant improvements in consistency and smoothness while preserving image quality and unique model capabilities. For more information please consult the full paper or the project page.
Congrats to the authors for their work!
Lee, Dohun, et al. "Video Guide: Improving Video Diffusion Models Without Training Through a Teacher's Guide." arXiv preprint arXiv:2410.04364 (2023).