


AnyV2V: A Plug-and-Play Framework For Any Video-to-Video Editing Tasks

The paper introduces AnyV2V, a plug-and-play framework for any video-to-video editing tasks.
The main idea is to disentangle the video editing process into two stages: (1) editing the first frame using an off-the-shelf image editing model, and (2) generating the edited video using an image-to-video generation model with DDIM (Denoising diffusion implicit models) inversion and feature injection.
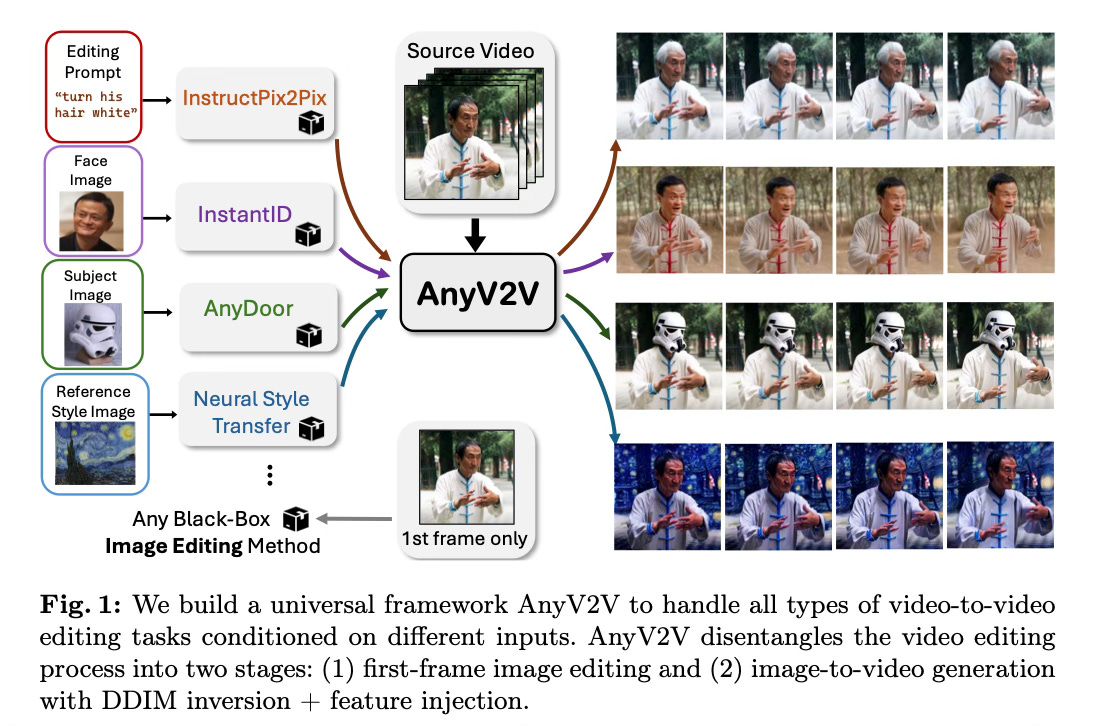
Method Overview
The AnyV2V method disentangles the video editing process into two main stages.
In the first stage, an off-the-shelf image editing model is employed to modify the first frame of the source video according to the desired editing task. The framework is highly flexible, compatible with a wide range of image editing models for prompt-based editing (e.g. InstructPix2Pix), style transfer (e.g. Neural Style Transfer), subject-driven editing (e.g. AnyDoor), and identity manipulation (e.g. InstantID). This allows for precise control over the initial frame edit.
The second stage focuses on generating the full edited video sequence using an image-to-video (I2V) diffusion model like I2VGen-XL, ConsistI2V or SEINE. Structural guidance is provided by performing DDIM inversion on the source video to obtain latent noise representations at each timestep. Furthermore, to guide the motion of the edited video, temporal self-attention queries and keys from the source denoising are also injected.
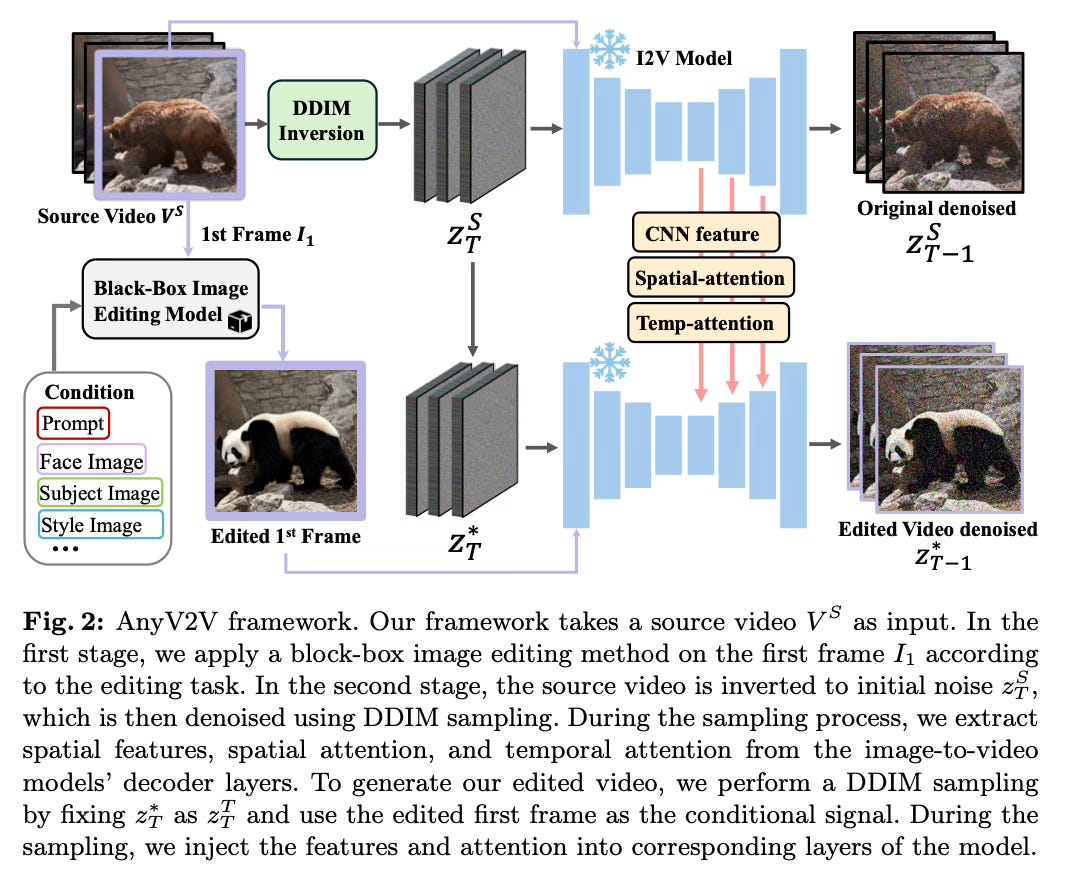
Finally, using the edited first frame, editing conditions (e.g. prompt, style reference), DDIM inverted noise, and injected spatial/temporal features as input, the I2V model samples the final edited video sequence. The spatial/temporal injection and DDIM inversion enable tuning-free adaptation of off-the-shelf I2V models for high-quality video editing while maintaining appearance and motion consistency with the source video.
Results
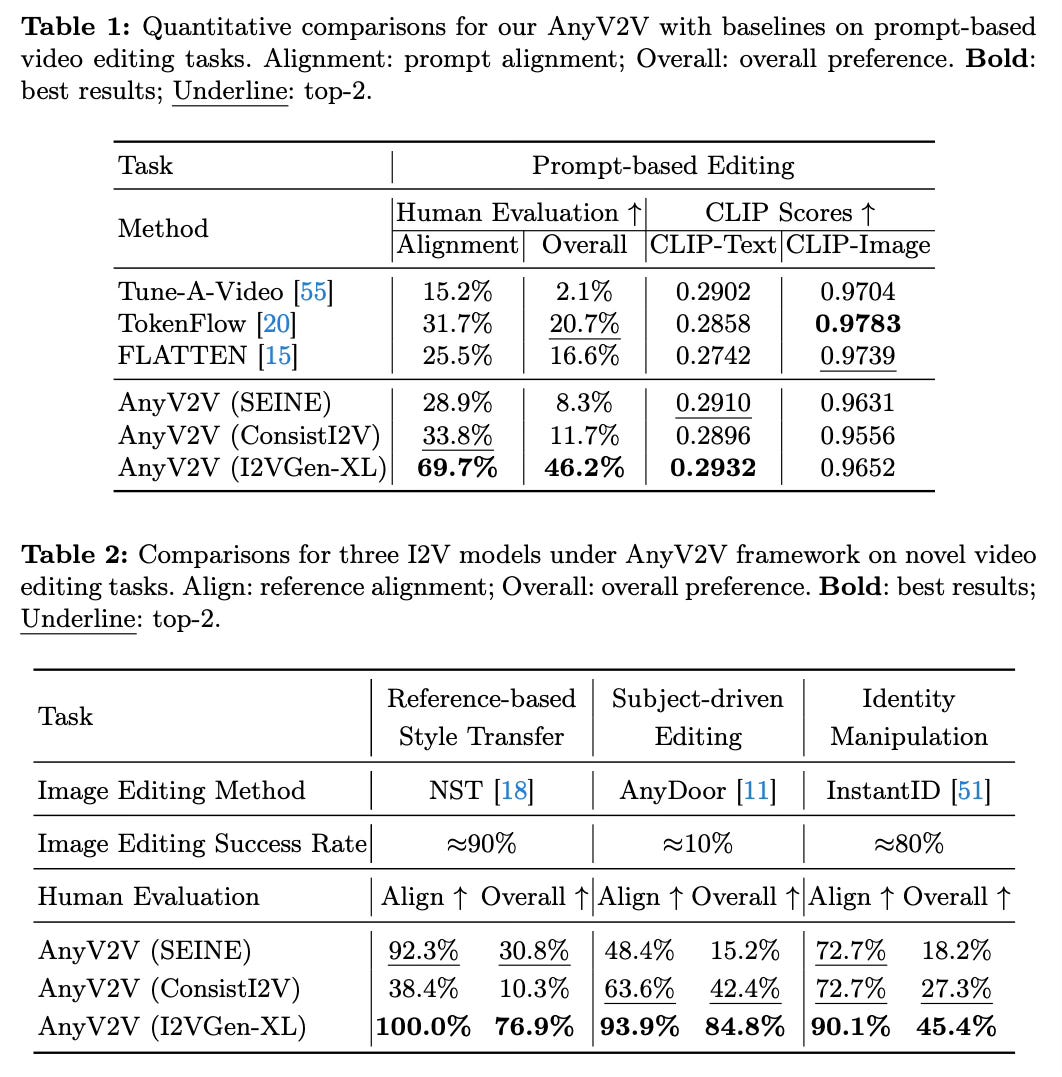
Quantitative and qualitative results show that AnyV2V outperforms state-of-the-art baselines on prompt-based editing tasks, achieving higher prompt alignment and human preference scores.
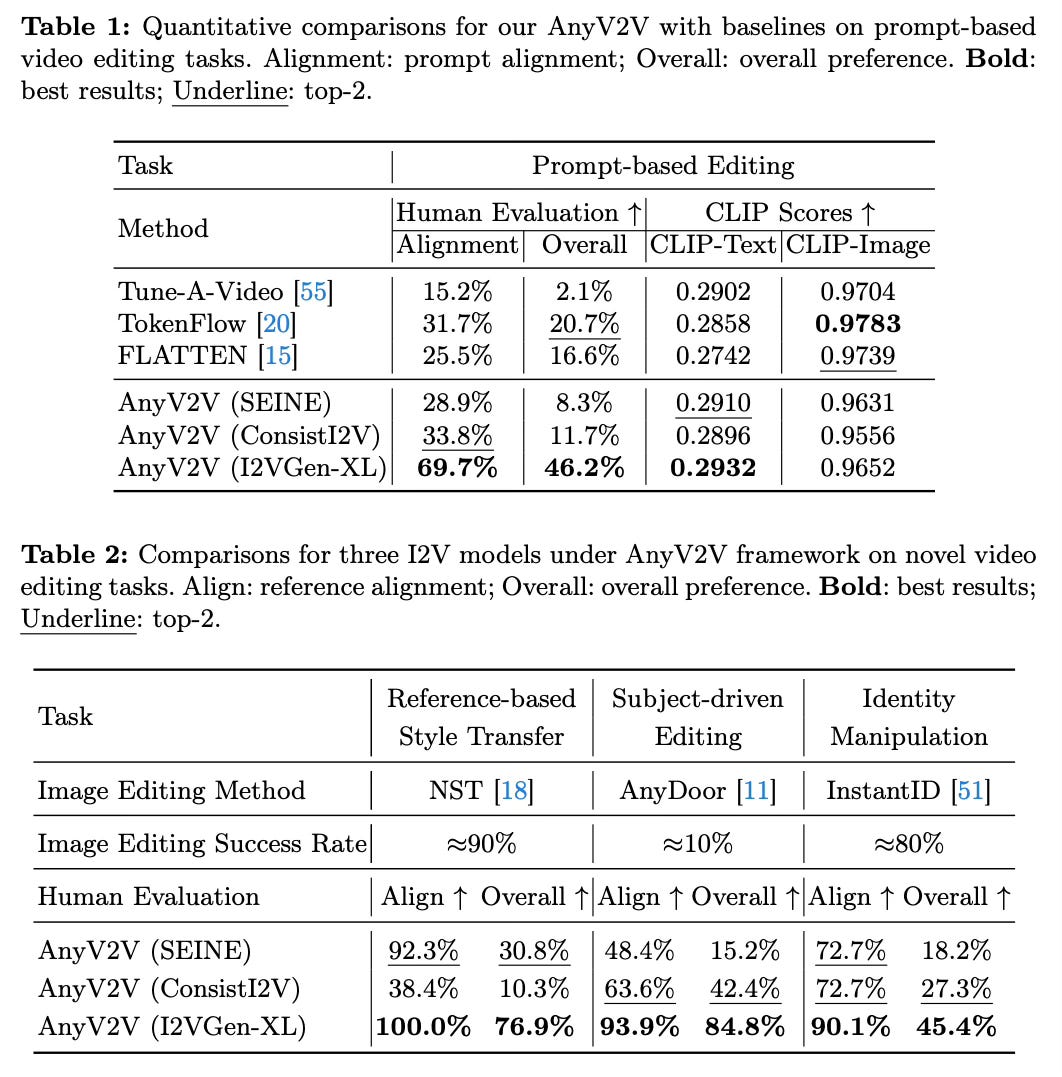
AnyV2V is among the first methods to successfully tackles tasks such as reference-based style transfer, subject-driven editing, and identity manipulation.
Conclusion
AnyV2V is a unified, training-free framework that can handle a diverse range of video-to-video editing tasks by leveraging off-the-shelf image editing models and pre-trained image-to-video generation models. Its plug-and-play design allows for easy integration of new image editing techniques, enabling increased versatility and controllability in video editing. For more details please consult the full paper or the project page.
Congrats to the authors for their work!
Ku, Max, et al. "AnyV2V: A Plug-and-Play Framework For Any Video-to-Video Editing Tasks." ArXiv, 22 Mar. 2024