
Avatar Forcing: Real-Time Interactive Head Avatar Generation for Natural Conversation

Today’s paper presents Avatar Forcing, a framework designed to generate real-time interactive head avatars capable of engaging in natural conversation. While existing talking head generation models can create lifelike avatars from static portraits, they typically focus on one-way communication, such as synchronizing lip movements with audio, rather than truly interacting with a user. This lack of responsiveness results in avatars that appear disengaged or emotionally flat during live exchanges. The paper addresses these limitations by proposing a system that models causal interactions, allowing an avatar to process and react to a user’s verbal and non-verbal cues with minimal latency.
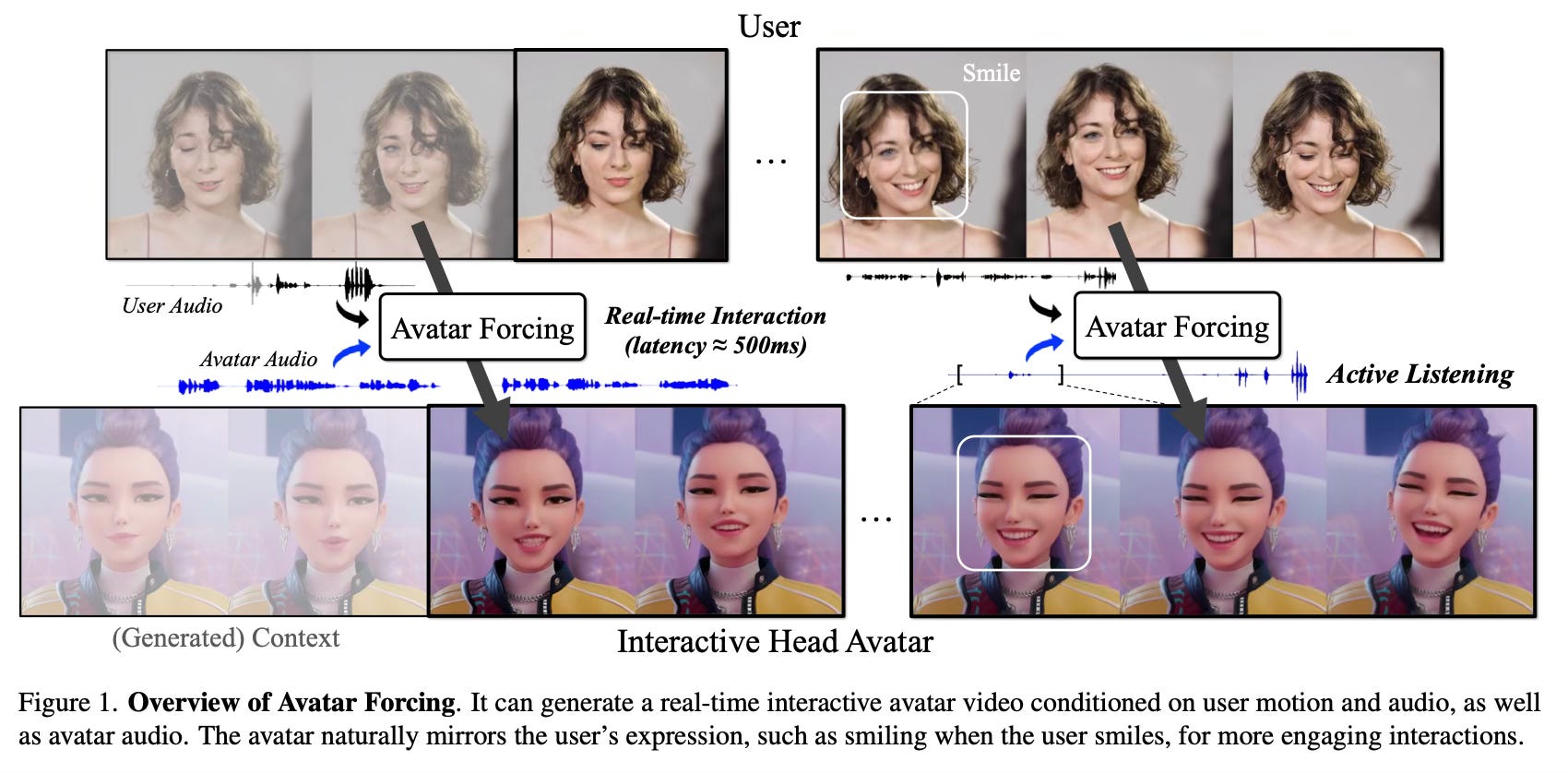
Method Overview
The proposed method functions by creating a digital avatar that listens and watches the user in real-time, generating appropriate reactions immediately. Intuitively, the system works like a conversational partner: it continuously takes in the user’s voice and head movements, along with the avatar’s own intended speech, and produces the corresponding avatar video output. Instead of waiting for a long sentence to finish to decide how to act, the model predicts the avatar’s next movement frame-by-frame based on what has just happened, ensuring the interaction feels spontaneous and fluid.
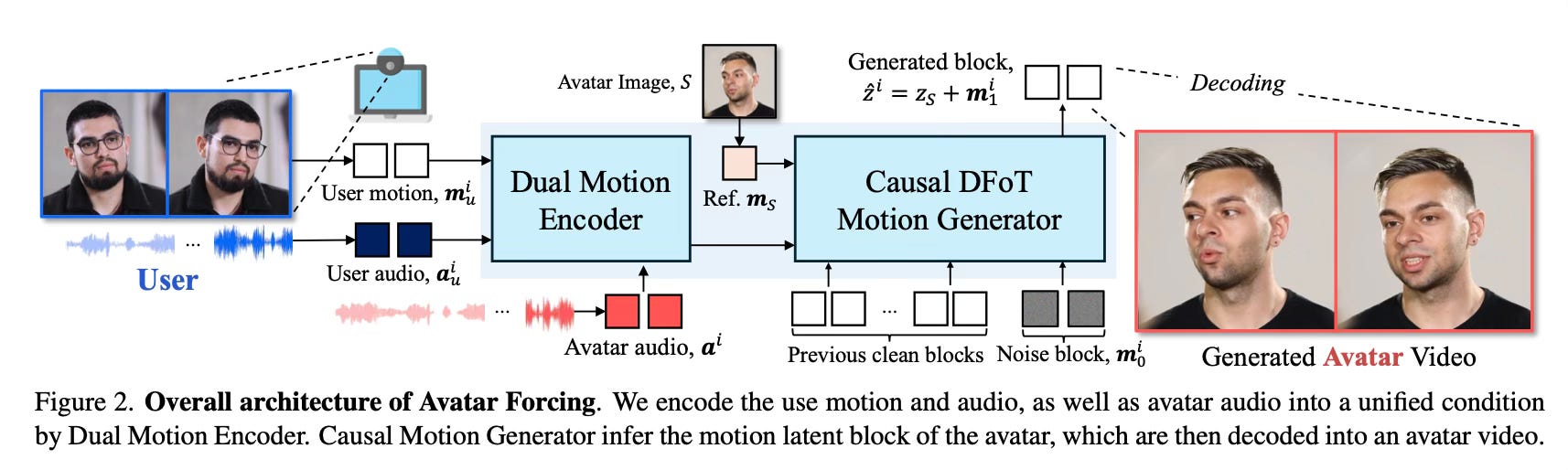
To achieve this, the framework uses causal diffusion forcing within a learned motion latent space. The architecture consists of a Dual Motion Encoder that captures the bidirectional relationship between the user and the avatar. It aligns the user’s multimodal signals (audio and motion) with the avatar’s audio to create a unified condition. A motion generator then predicts the avatar’s movements using a blockwise causal structure. This design allows the system to generate video frames sequentially without needing access to future context, which is the primary factor that reduces latency compared to previous bidirectional approaches.
A significant aspect of the method is how it learns to be expressive without requiring expensive, manually labeled datasets of “good” interactions. The paper introduces a preference optimization strategy that utilizes “synthetic losing samples.” The model is trained to distinguish between a highly reactive motion (conditioned on the user’s input) and a generic, less reactive motion (generated by ignoring the user’s input). by teaching the model to prefer the reactive version, the avatar learns to exhibit active listening behaviors—such as nodding or smiling back—making the conversation significantly more engaging.
Results
The experimental results demonstrate that Avatar Forcing successfully enables real-time interaction with a latency of approximately 500ms, which is sufficient for natural conversation. This represents a significant speedup compared to baseline models that require seconds of context to generate motion. In terms of visual quality and responsiveness, the method produces avatars that are notably more reactive and expressive.
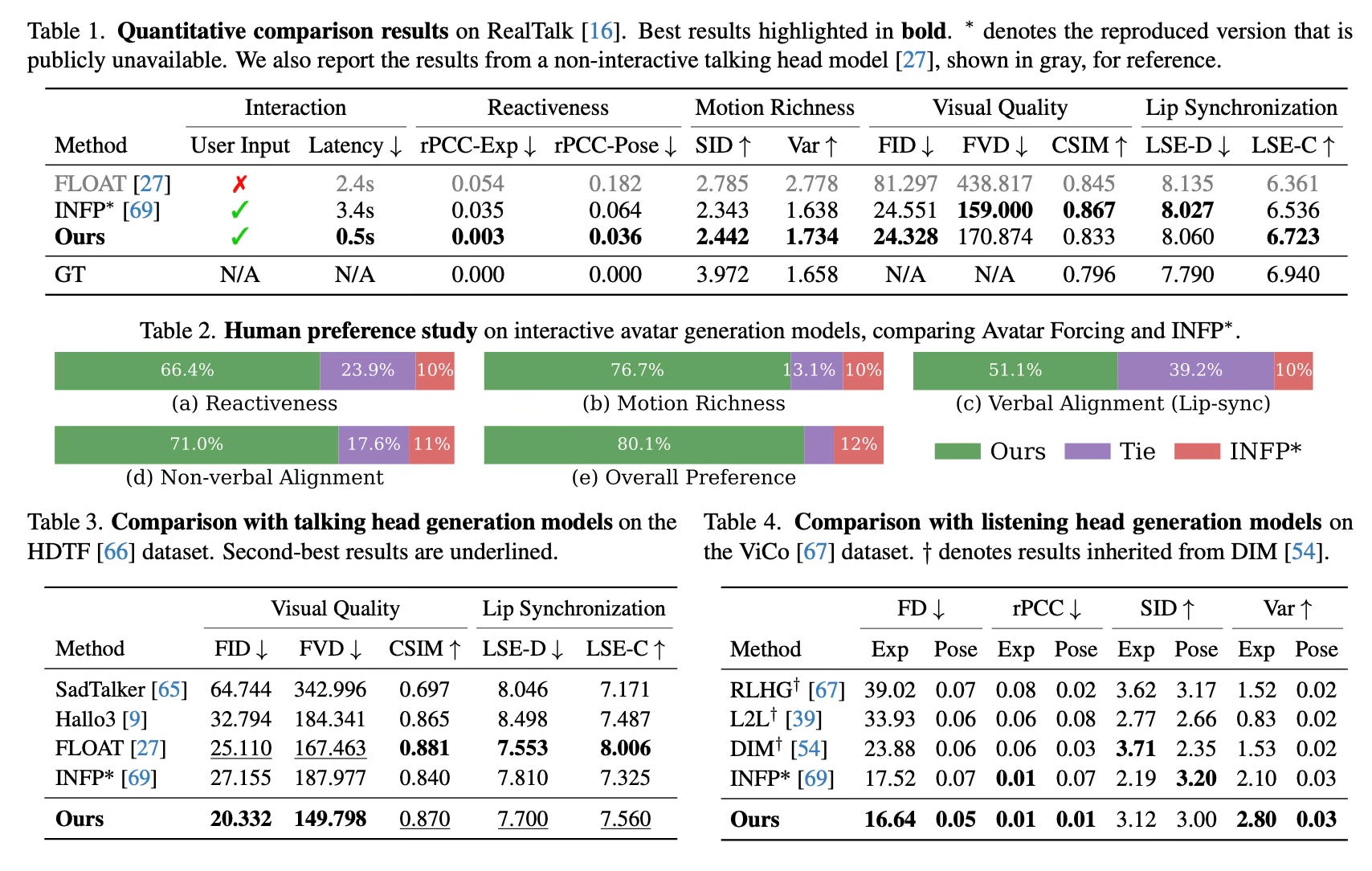
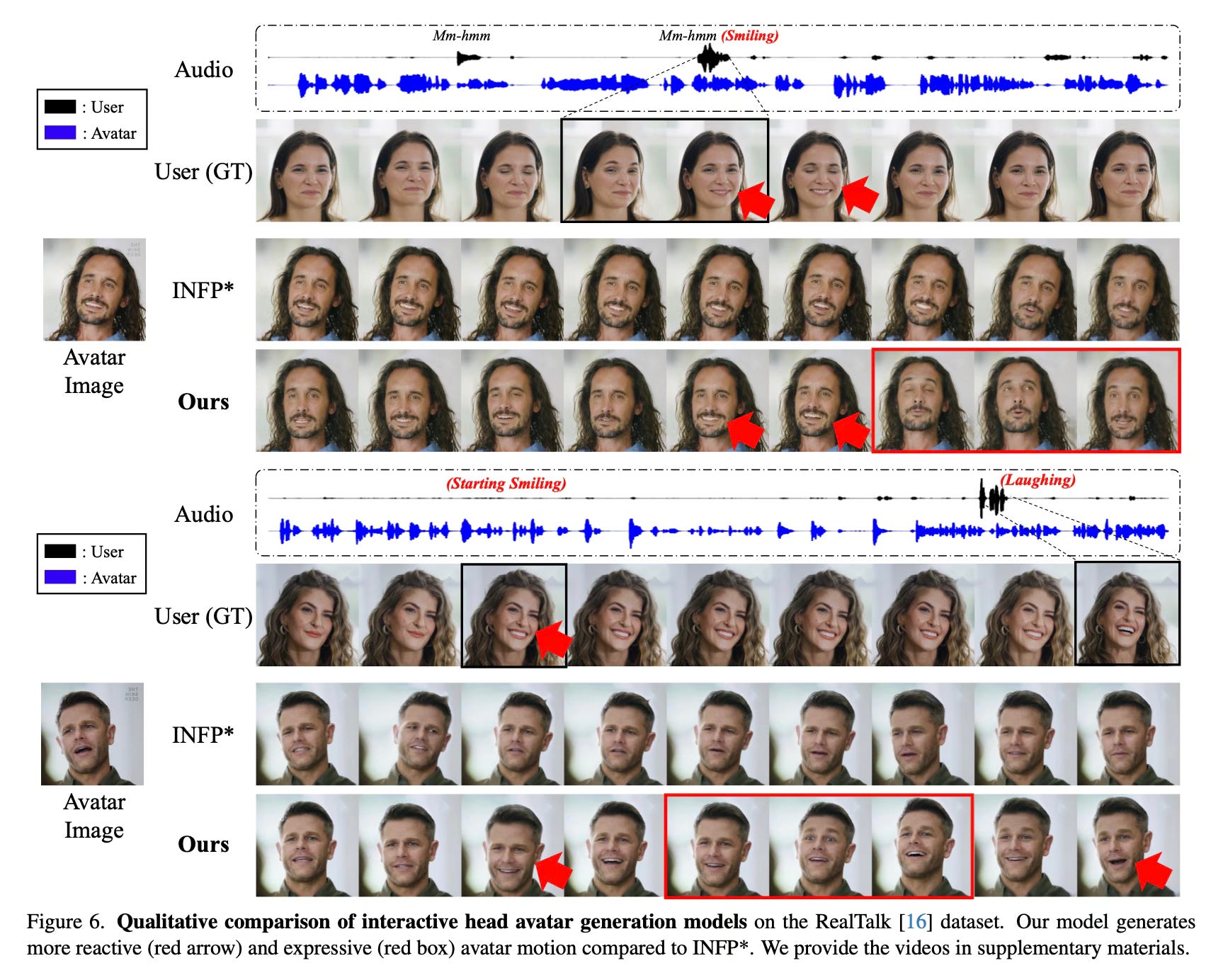
Quantitative evaluations on dyadic conversation datasets show that the method outperforms existing baselines in metrics measuring reactiveness (synchronization with user expressions) and motion richness. Furthermore, human preference studies reveal that the generated avatars are preferred over 80% of the time against strong baselines, with participants citing improved naturalness and better non-verbal alignment, such as smiling when the user smiles or focusing when the user speaks.
Conclusion
Avatar Forcing introduces a robust framework for creating interactive head avatars that can respond to users in real-time. By leveraging causal diffusion forcing and a novel preference optimization method, the system overcomes the latency and expressiveness bottlenecks found in prior work. The resulting avatars demonstrate the ability to engage in bidirectional communication, exhibiting active listening and emotional responses that mirror the user’s behavior, thereby facilitating more realistic human-AI interactions.
For more information please consult the full paper.
Congrats to the authors for their work!
Ki, Taekyung, et al. “Avatar Forcing: Real-Time Interactive Head Avatar Generation for Natural Conversation.” arXiv preprint arXiv:2601.00664 (2026).