
Code2World: A GUI World Model via Renderable Code Generation

Today’s paper addresses the challenge of equipping autonomous GUI agents with the ability to foresee the consequences of their actions. While current agents can perceive interfaces and execute commands, they often lack the “mental sandbox” required to simulate outcomes before acting, which can lead to errors or irreversible mistakes in complex navigation tasks. The paper proposes Code2World, a framework that models the digital world by generating renderable code, allowing agents to predict the next visual state of an interface with high structural and visual fidelity.

Method Overview
The core concept behind this method is treating the simulation of graphical user interfaces (GUIs) as a code generation task rather than an image generation task. Instead of trying to predict the next screenshot pixel-by-pixel—which often results in blurry text or distorted structures—the model predicts the underlying HTML code that represents the interface. Once the code is generated, it is rendered by a browser engine to produce a crisp, deterministic, and structurally accurate image of the future state.
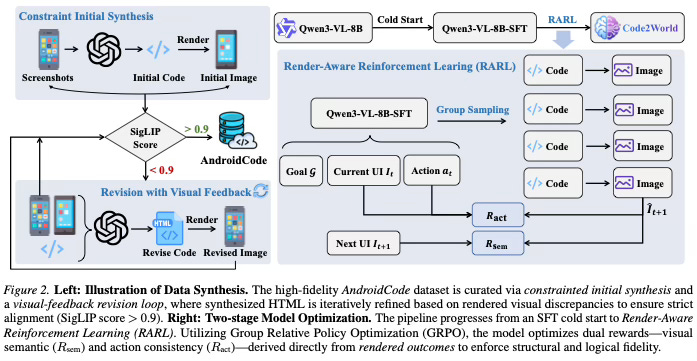
To enable this approach, the paper first constructs a large-scale dataset called AndroidCode. Since existing datasets usually only provide screenshots and actions, the method utilizes a synthesis pipeline to convert raw GUI images into structured HTML. To ensure the quality of this data, a visual-feedback revision mechanism is employed. This process involves rendering the synthesized code back into an image, comparing it with the original screenshot, and iteratively refining the code until the visual alignment meets a high confidence threshold.
The model training follows a two-stage process. Initially, it undergoes Supervised Fine-Tuning (SFT) to learn the syntax and formatting required to generate valid HTML layouts. Following this, the method applies a Render-Aware Reinforcement Learning strategy. Unlike traditional text training, this stage uses the rendered visual outcome as the signal for learning. It optimizes for two specific rewards: visual semantic fidelity, ensuring the layout looks correct, and action consistency, ensuring the transition logically reflects the user’s executed action. This allows the model to align its textual code generation with visual reality.
Results
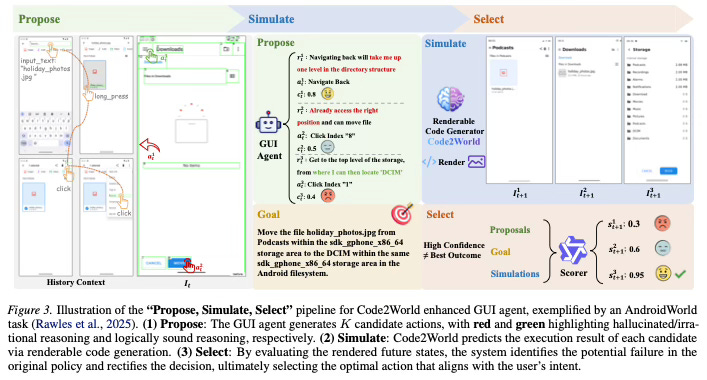
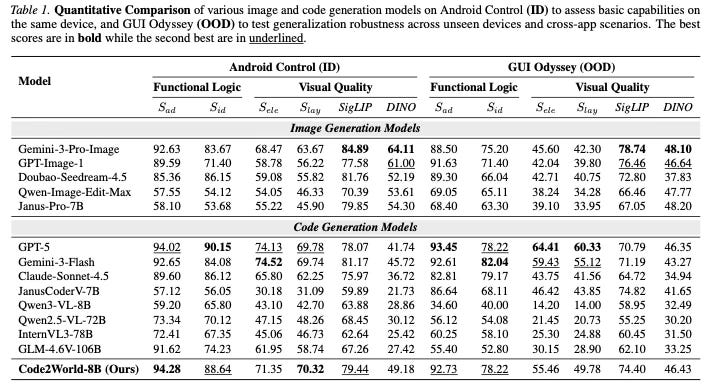
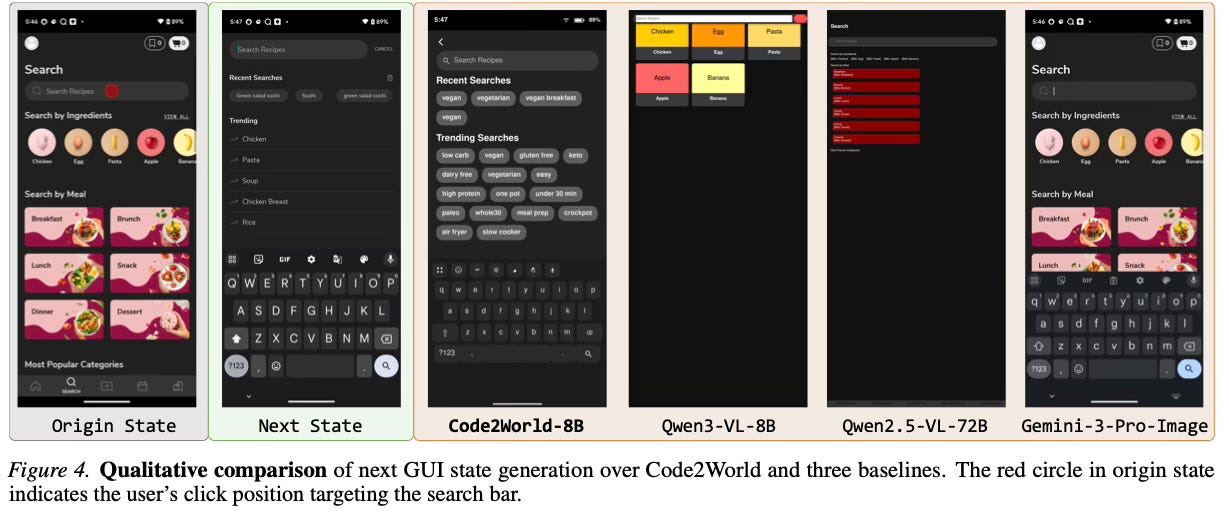
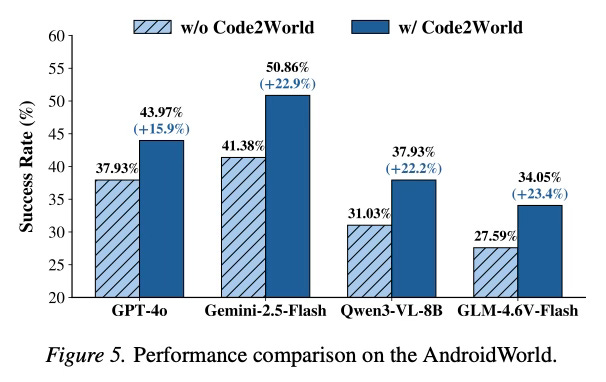
Code2World demonstrates strong performance in predicting the next state of user interfaces. Despite being a smaller 8B parameter model, it achieves prediction quality that rivals large proprietary models such as GPT-5 and Gemini-3-Pro-Image. In practical applications, the model serves as a plug-and-play simulator that significantly enhances the planning capabilities of other GUI agents. When integrated with Gemini-2.5-Flash, Code2World improved the agent’s navigation success rate on the AndroidWorld benchmark by +9.5%. Furthermore, the method shows robust generalization capabilities when tested on unseen applications and diverse UI styles.
Conclusion
This paper presents a shift in GUI world modeling by moving from pixel-based to code-based generation. By leveraging the structural nature of HTML and employing a render-aware training strategy, Code2World provides a high-fidelity virtual sandbox. This capability enables autonomous agents to simulate actions and refine their strategies, leading to more reliable and effective navigation in digital environments.
For more information please consult the full paper.
Congrats to the authors for their work!
Zheng, Yuhao, et al. “Code2World: A GUI World Model via Renderable Code Generation.” arXiv preprint arXiv:2602.09856, 2026.