

CodecLM: Aligning Language Models with Tailored Synthetic Data
CodecLM: Aligning Language Models with Tailored Synthetic Data

This paper introduces CodecLM, a framework for generating high-quality synthetic data to align large language models (LLMs) for different downstream instruction-following tasks. CodecLM eliminates the need for costly human annotation by adaptively generating tailored data.
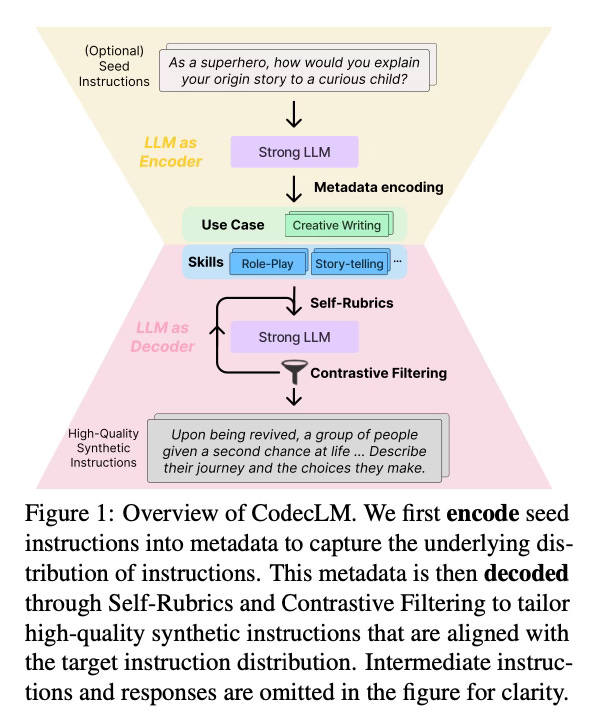
Method Overview
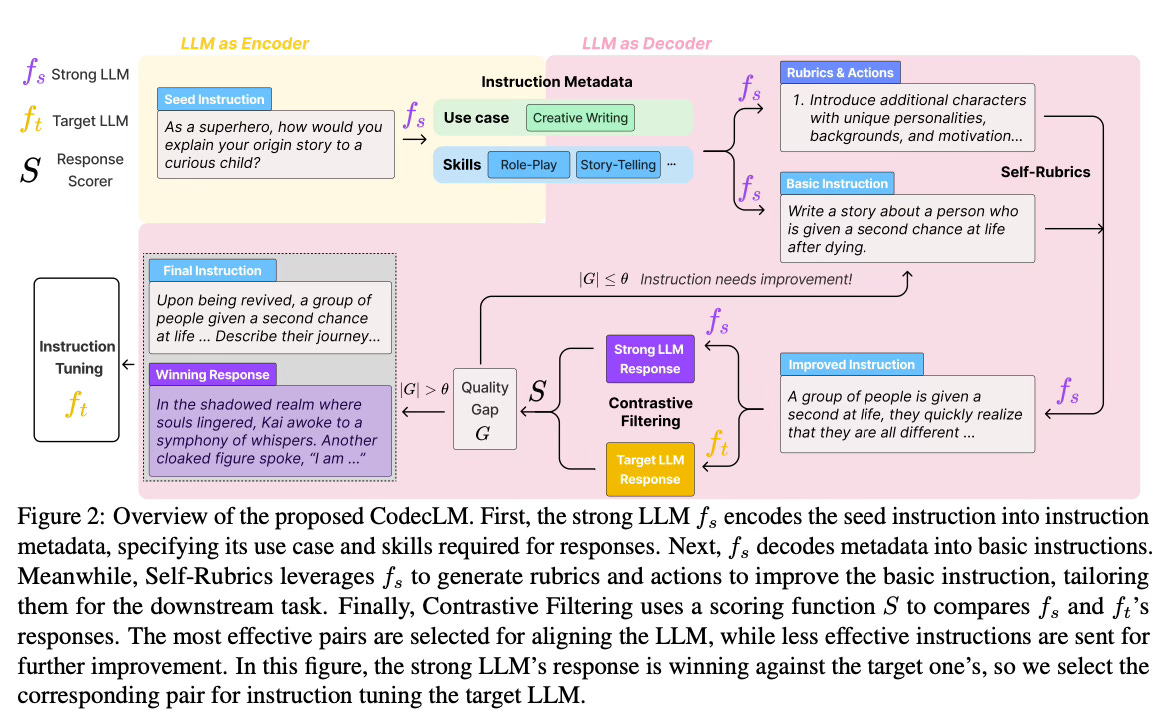
CodecLM uses a strong LLM as a codec to "encode" seed instructions into instruction metadata that captures the target instruction distribution, and then "decode" the metadata into tailored synthetic instructions. The prompt template for this step is shown below:

The metadata includes the use case (intended task) and skills (knowledge required to respond) for each instruction. Then, CodecLM prompts the strong LLM with the metadata to generate basic instructions. The prompt template for this step is shown below:

It also generates rubrics and actions that are used to improve the basic instructions. So, it uses the so called Self-Rubrics, to make the instructions more complex and tailored to the metadata. Self-Rubrics generates rubrics to assess instruction complexity based on the metadata, and then generates corresponding actions to enhance the complexity along with improved instructions in an iterative process.


Finally, Contrastive Filtering selects the most effective instruction-response pairs by comparing the responses from the target LLM and strong LLM. It identifies instructions the target LLM struggles with to focus on areas for improvement that are stored as the fine-tuning data, as well as instructions it performs well that are fed back in the Self-Rubrics for further improvement.

Results
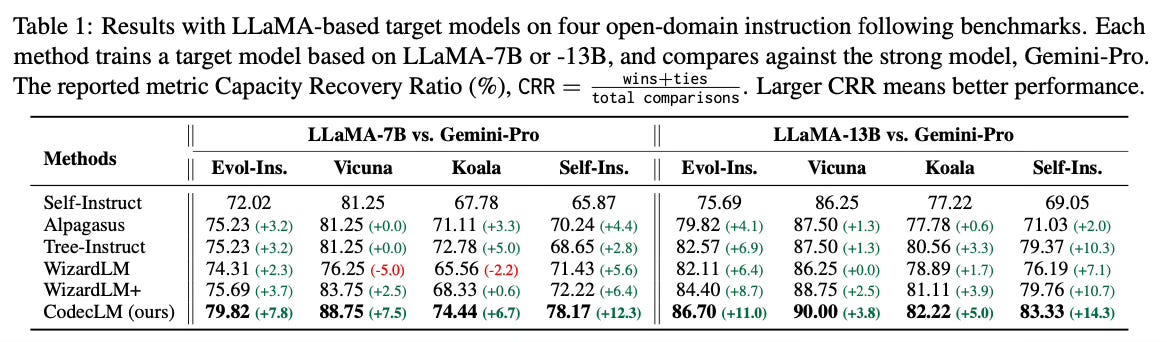
Experiments on four open-domain instruction-following benchmarks demonstrate that CodecLM outperforms state-of-the-art data generation methods for LLM alignment. It shows effectiveness with different LLM choices and instruction distributions.
Conclusion
CodecLM provides an effective solution for tailoring synthetic data to align LLMs for customized downstream tasks, without requiring human annotation. For more information please consult the full paper.
Congrats to the authors for their work!
Wang, Zifeng, et al. "CodecLM: Aligning Language Models with Tailored Synthetic Data." arXiv preprint arXiv:2404.05875 (2023).