

Depth Anything: Unleashing the Power of Large-Scale Unlabelled Data
Depth Anything: Unleashing the Power of Large-Scale Unlabelled Data

Depth Anything offers a practical approach to depth estimation, specifically monocular depth estimation where depth is estimated from a single image. This has far-reaching applications in fields like self-driving cars and virtual reality. Instead of relying on hard-to-obtain labeled images, Depth Anything leverages a large dataset of 62 million regular images for training. This allows it to predict depths accurately across a wider range of situations.

Architecture
The main strategy behind Depth Anything is to make the most of unlabelled images. It uses a two-part "teacher-student" approach. First, a 'teacher' model learns from a smaller set of images that do have depth labels. Then, this teacher model helps generate approximate depth labels for a much larger set of unlabeled images. This expanded dataset trains the 'student' model.
However, there's a twist: Challenging the Student
To ensure the student truly learns from the extra images new information, the process gets more complex. The unlabeled images get heavily altered – think extreme color changes and distortions. This forces the student model to find stable patterns and better understanding visual cues.
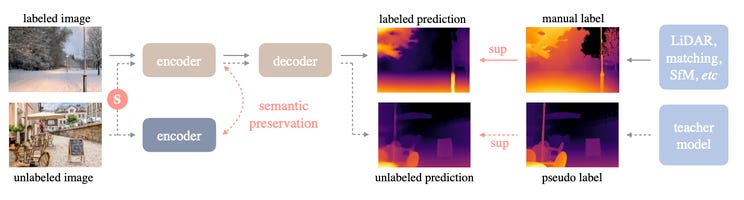
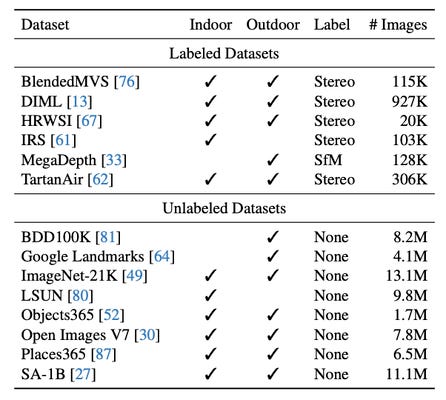
In total, Depth Anything is trained on 1.5M labeled images and 65M unlabelled images:
Results
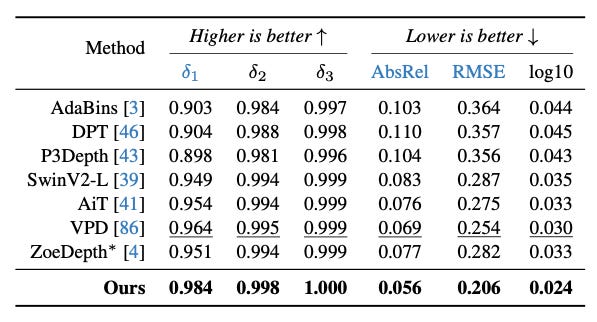
Depth Anything achieves very good results on multiple benchmarks showcasing the power of using unlabelled data.

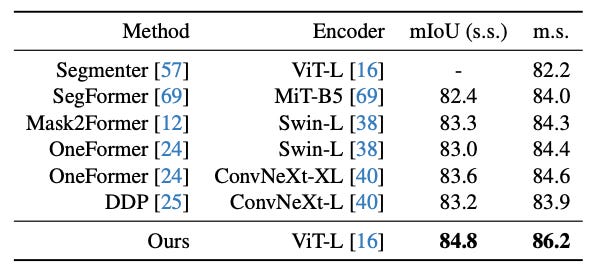
The method can also be fine-tuned on downstream tasks such as metric depth estimation or semantic segmentation.
Conclusion
Depth Anything demonstrates the power of leveraging large-scale unlabeled data. For more detailed information, please consult the full paper https://huggingface.co/papers/2401.10891 or the project page: https://depth-anything.github.io.
Congratulations to the authors for their great work!
GitHub: https://github.com/LiheYoung/Depth-Anything
Yang, Lihe, et al. "Depth anything: Unleashing the power of large-scale unlabeled data." arXiv preprint arXiv:2401.10891(2024).