
Document Haystacks: Vision-Language Reasoning Over Piles of 1000+ Documents

Today's paper introduces DocHaystack and InfoHaystack, two new benchmarks designed to evaluate large multimodal models (LMMs) on their ability to retrieve and reason across extensive document collections. The paper addresses a critical gap in current benchmarks, which typically limit questions to small sets of images, by scaling up to 1,000 documents per question. Additionally, it presents V-RAG, a vision-centric retrieval-augmented generation framework that significantly improves retrieval accuracy and reasoning capabilities across large document collections.

Method Overview
The paper introduces V-RAG, a framework that combines multiple vision encoders with a specialized filtering system to process large document collections efficiently. The method works in three main stages: first, it uses an ensemble of vision encoders (CLIP, SigLIP, and OpenCLIP) to analyze documents and compute similarity scores with the given question. Then, a language model-based filter evaluates the relevance of the top-ranked documents to refine the selection. Finally, the most relevant documents are passed to a large multimodal model for generating the final answer.
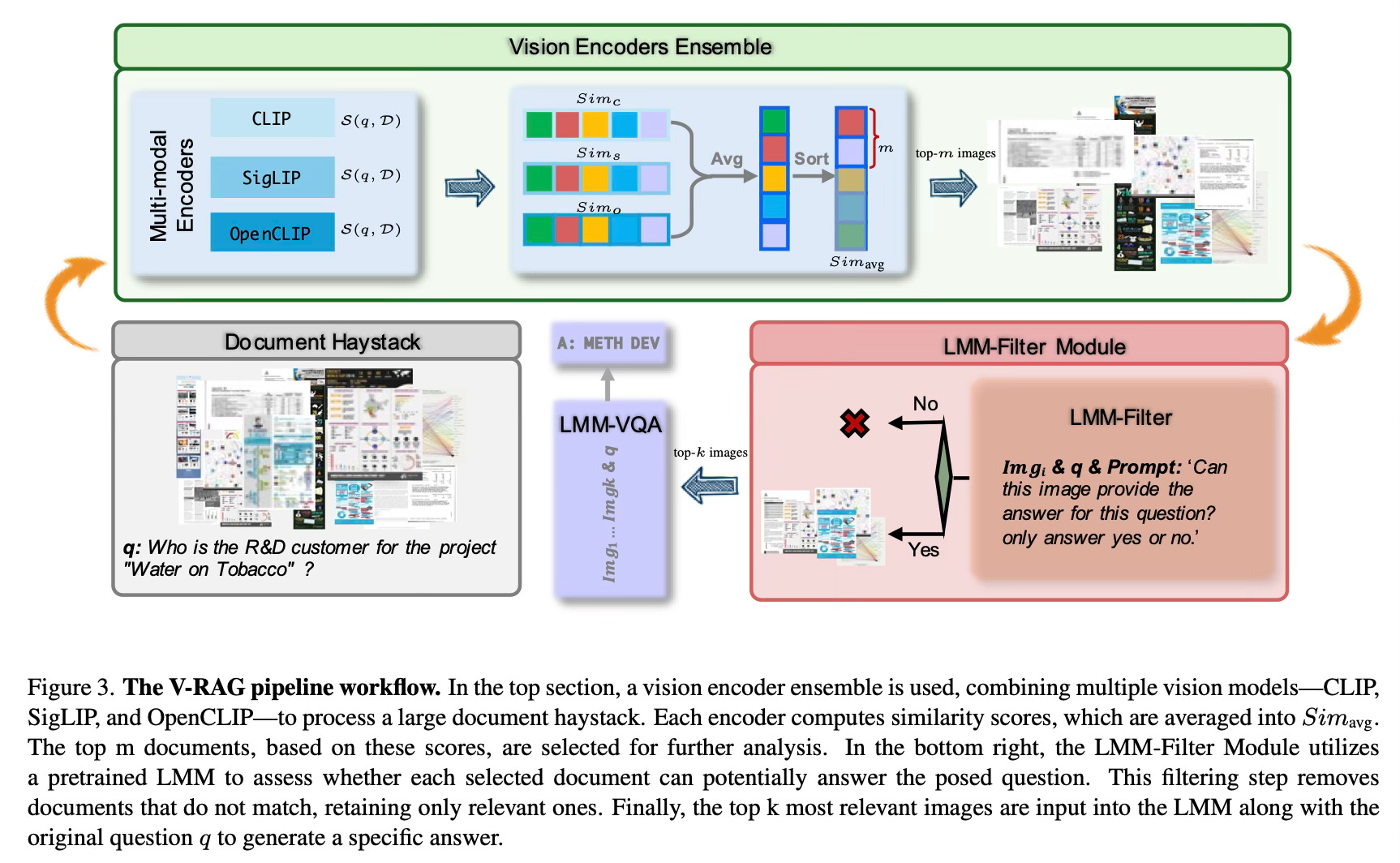
The framework's strength lies in its ability to leverage different vision encoders' unique capabilities while using the language model filter to ensure only truly relevant documents are considered. This two-step filtering process helps manage the complexity of processing large document collections while maintaining accuracy.

The method also includes a careful data curation process that ensures questions in the benchmark can only be answered by specific documents, eliminating ambiguity and making evaluation more meaningful.
Results
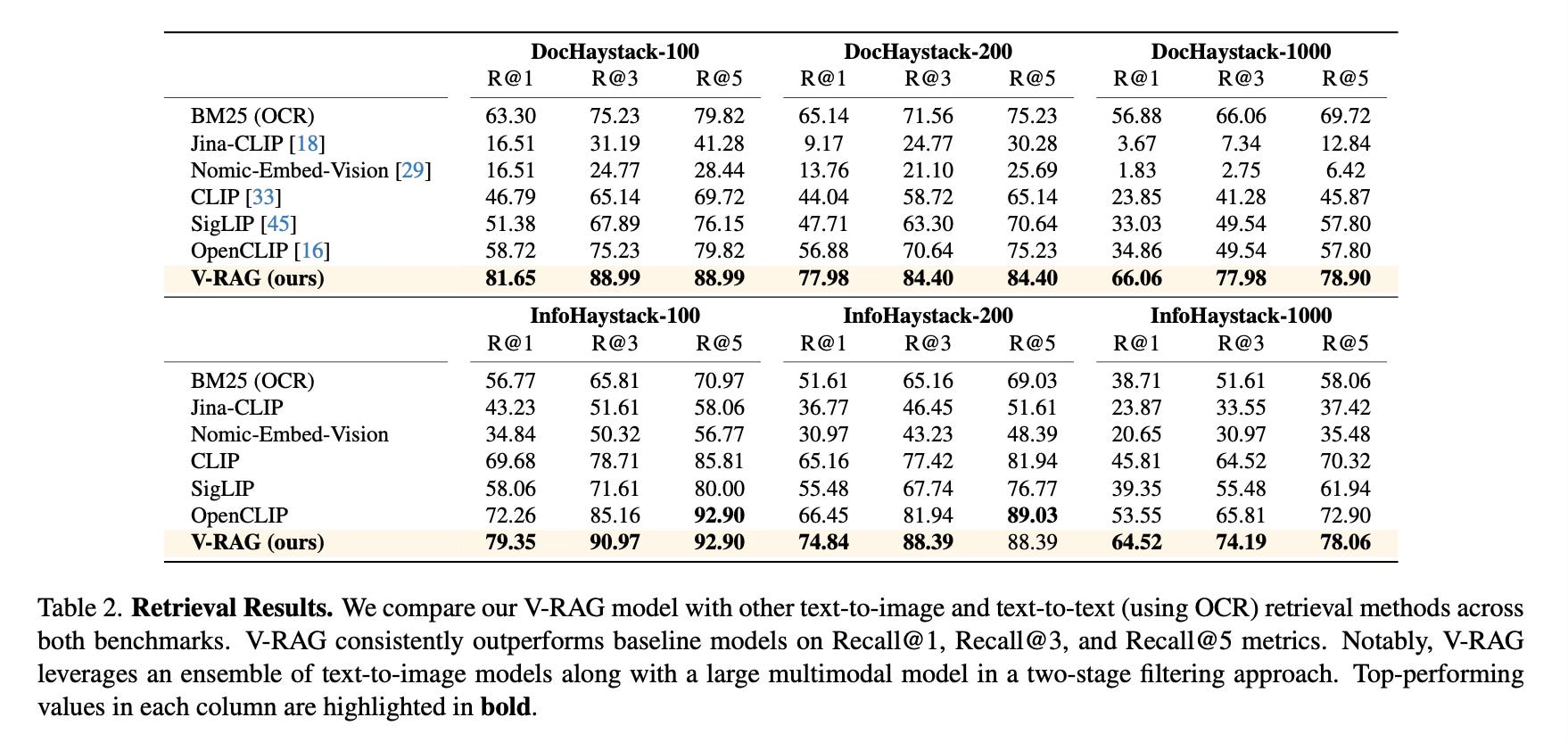
The V-RAG framework demonstrated significant improvements over existing methods:
Achieved 9% and 11% improvement in Recall@1 on DocHaystack-1000 and InfoHaystack-1000 respectively
When integrated with GPT-4o, showed over 55% accuracy improvement on DocHaystack-200 and 34% on InfoHaystack-200
Consistently outperformed baseline models across different document collection sizes
Maintained robust performance even when scaling up to 1,000 documents
Conclusion
The paper successfully addresses the challenge of large-scale document retrieval and understanding through two key contributions: comprehensive benchmarks that better reflect real-world scenarios, and an effective framework for handling large document collections. The V-RAG framework shows that combining multiple vision encoders with strategic filtering can significantly improve performance on complex document retrieval and understanding tasks. For more information please consult the full paper.
Congrats to the authors for their work!
Chen, Jun, et al. "Document Haystacks: Vision-Language Reasoning Over Piles of 1000+ Documents." arXiv preprint arXiv:2411.16740 (2024).