


EMO: Emote Portrait Alive

Today's paper introduces EMO, a new framework for generating realistic talking head videos from just a single portrait photo and an audio clip. The key innovation lies in EMO's ability to directly translate audio cues like tone and pronunciation into corresponding facial expressions and head movements. By capturing the dynamic link between vocals and motions, EMO can animate portrait photos with a diverse range of lively and natural motions synchronized to the audio.
Method Overview
EMO receives a single reference image that depitcs a portrait of a character and generates a video synchronized with an input audio that preserves the natural head motion and shows vivid face experssions that are in harmony with the audio.
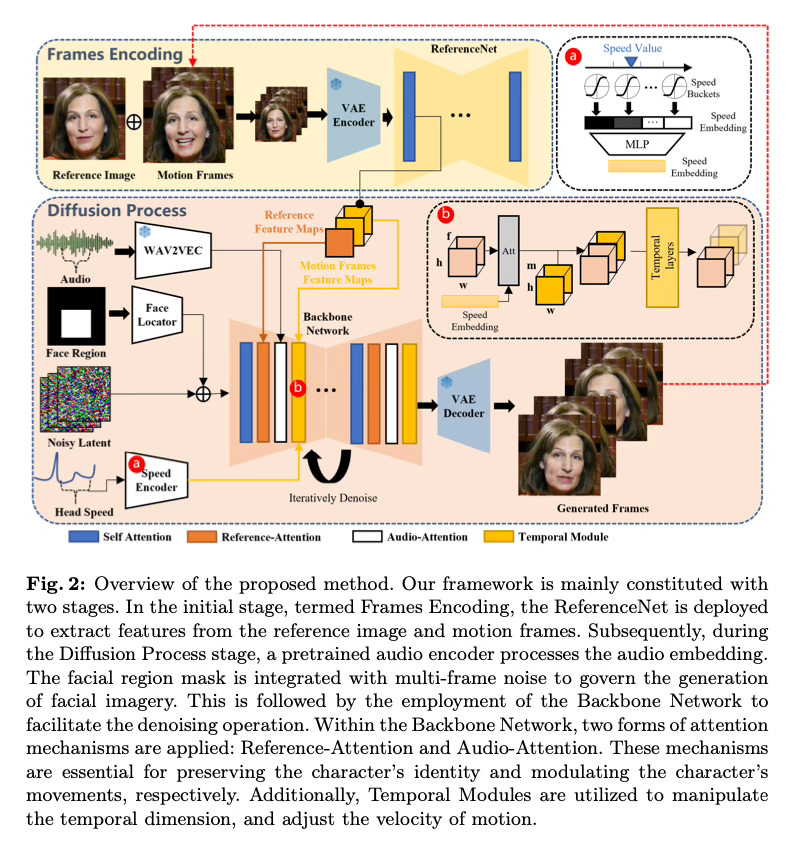
EMO has two stages: in the first stage, a Reference Net is used to extract frame encodings from the reference image and the previous generated frames. In the second stage, a diffusion process is used. It uses a Backbone Network that serves as the video generation engine. It uses two attention mechanisms: Reference Attention to preserve the identity of the person in the input photo and Audio Attention to modulate the facial expressions and head poses based on the embedded audio features.
Unlike other approaches that rely on 3D face models or landmarks as intermediate constraints, EMO directly generates the output video frames. The authors collect a 250 hour video dataset covering diverse facial movements like speeches, conversations, and singing in multiple languages. They combine this data with two existing datasets (HDTF and VFHQ) and then train the model.
Results
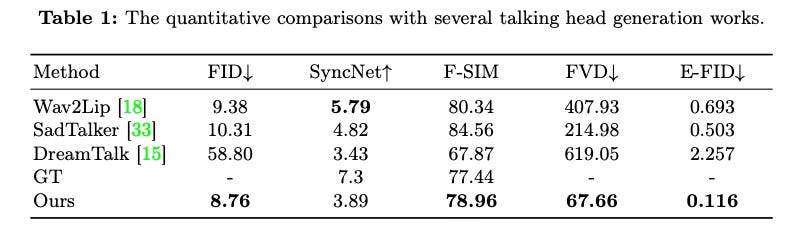
Evaluations demonstrate EMO's ability to produce videos not just with accurate lip sync, but also emotionally varied facial expressions in line with the audio tone achieving good results and surpassing prior works:
Here are some qualitative results:
Conclusion
EMO framework significantly pushes the bar on creating engaging talking head videos from audio, unlocking new levels of realism and faithfulness to the vocal style/content. For more details please consults the full paper or the project page.
Congrats to the authors for their work!
Tian, Linrui et al. “EMO: Emote Portrait Alive - Generating Expressive Portrait Videos with Audio2Video Diffusion Model under Weak Conditions.” (2024).