

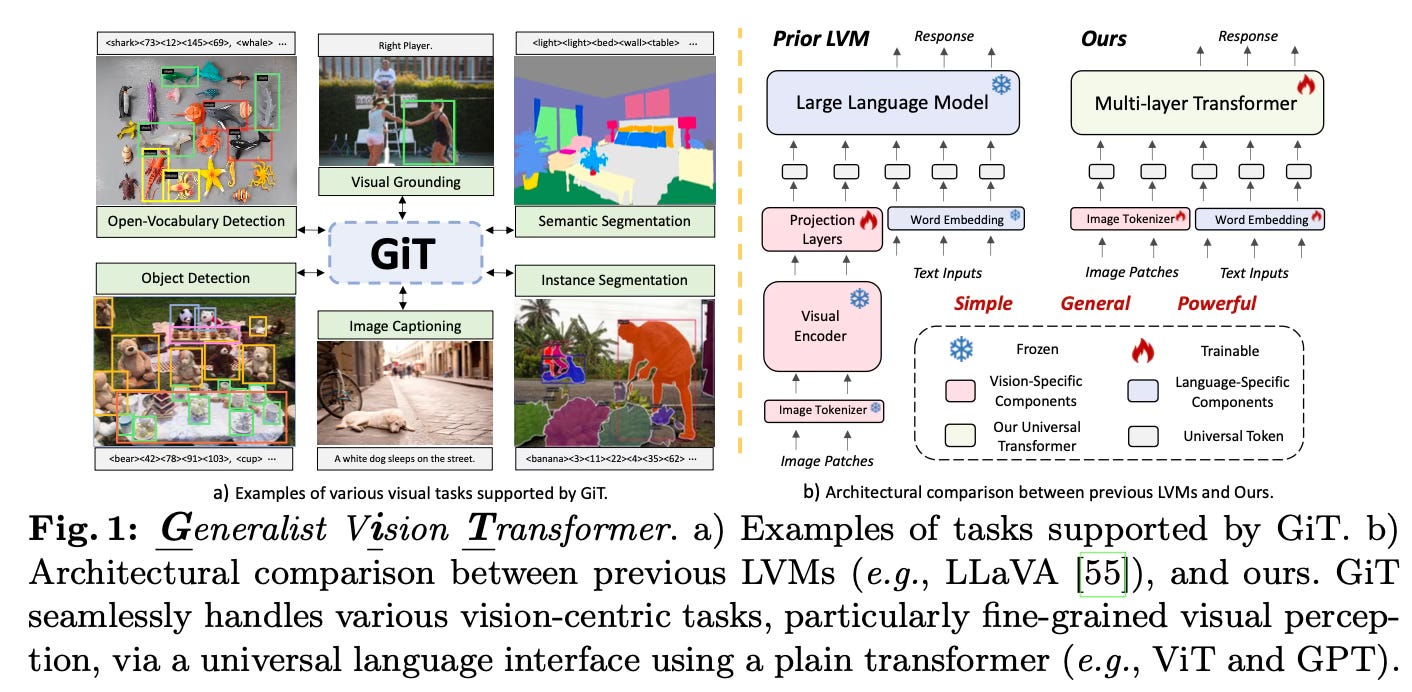
The paper introduces GiT, a Generalist Vision Transformer that can handle various vision tasks, ranging from image-level understanding to object-level and pixel-level tasks, using a simple multi-layer transformer architecture without any task-specific additions. The main idea is to leverage a universal language interface to unify different vision tasks, similar to how large language models operate, enabling multi-task learning and efficient knowledge sharing across diverse visual domains.
Method Overview
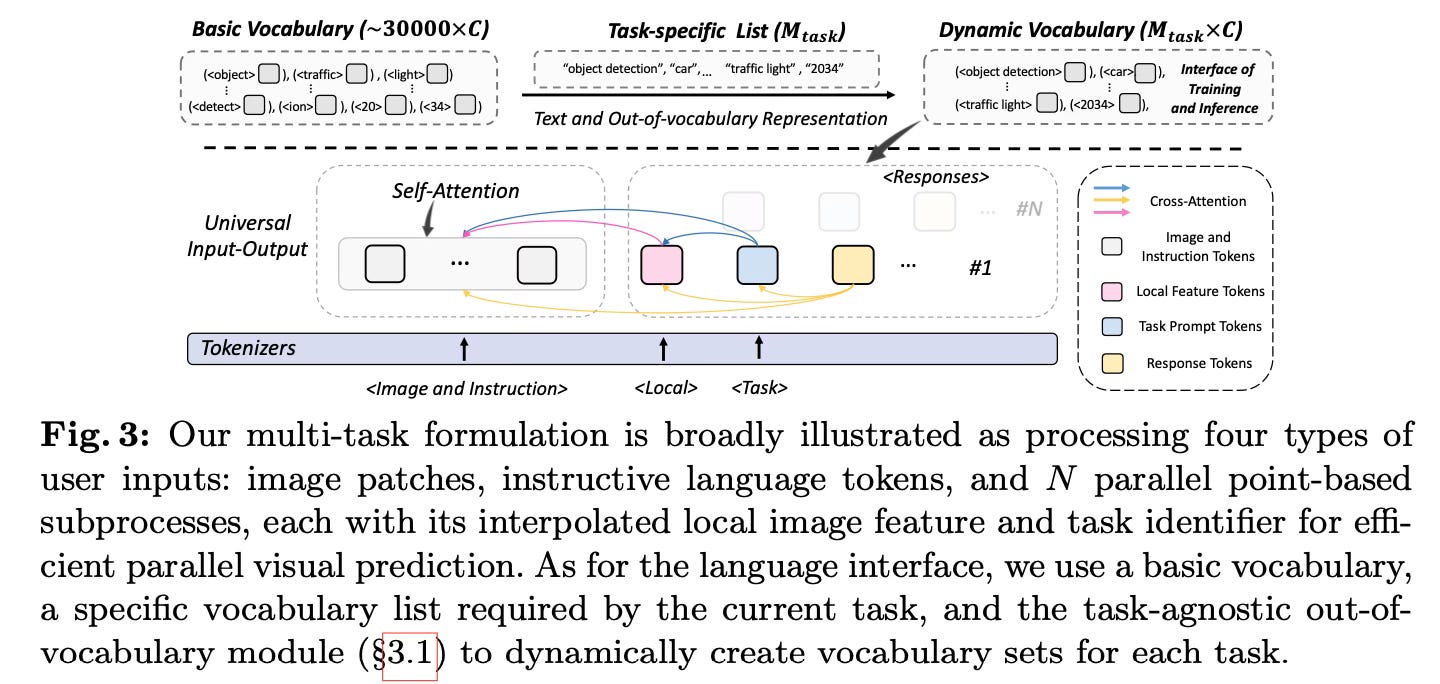
The core idea is to represent all inputs (images, text, bounding boxes, masks) and outputs (captions, object detections, segmentations) using a unified token-based format based on a standard vocabulary. This allows leveraging the multi-layer transformer architecture that has been successful in large language models.
The method introduces a universal language interface that converts different input/output modalities into token sequences. Images are tokenized into patch embeddings, text is tokenized using WordPiece, and targets like bounding boxes, masks, and captions are tokenized based on their representation (e.g. bounding boxes as 4 coordinate tokens). It uses a unified template for different tasks as shown below:
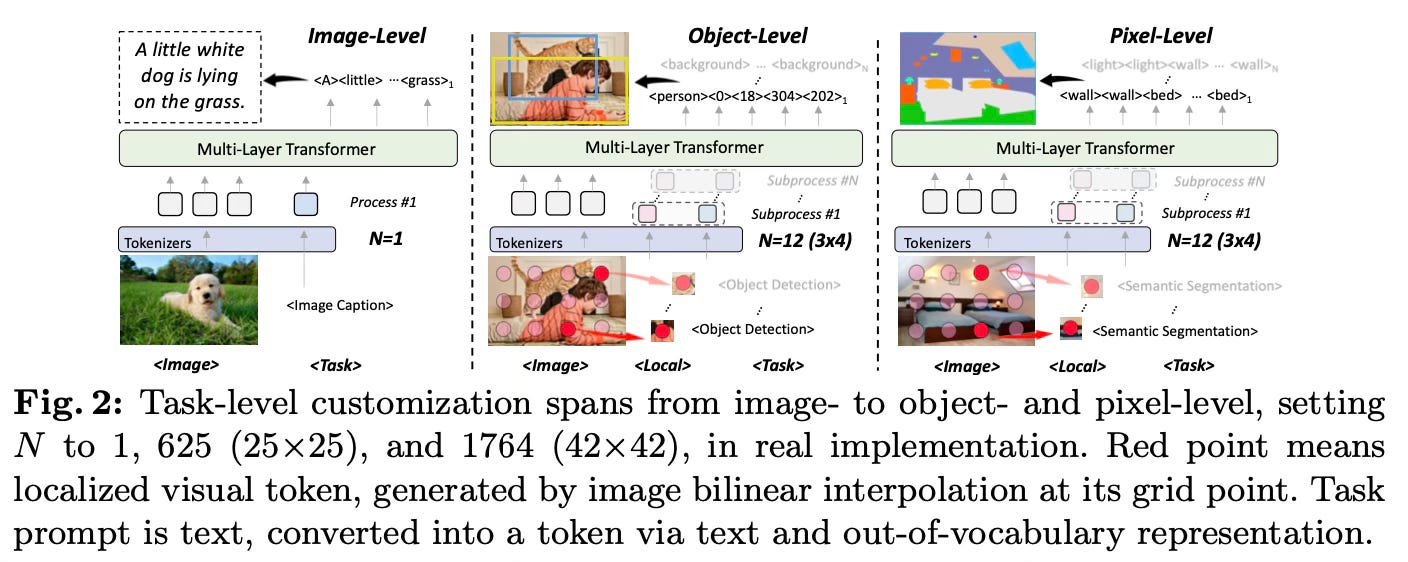
The entire model consists solely of a standard multi-layer transformer inspired by ViTs, without any task-specific add-ons except lightweight input tokenizers and task-specific vocabularies. It is trained end-to-end using a single autoregressive language modeling objective across multiple vision datasets in a multi-task manner.
Results
GiT achieves competitive performance on various vision benchmarks, outperforming previous generalist models like VisionLLM while using significantly fewer parameters and a simpler architecture.
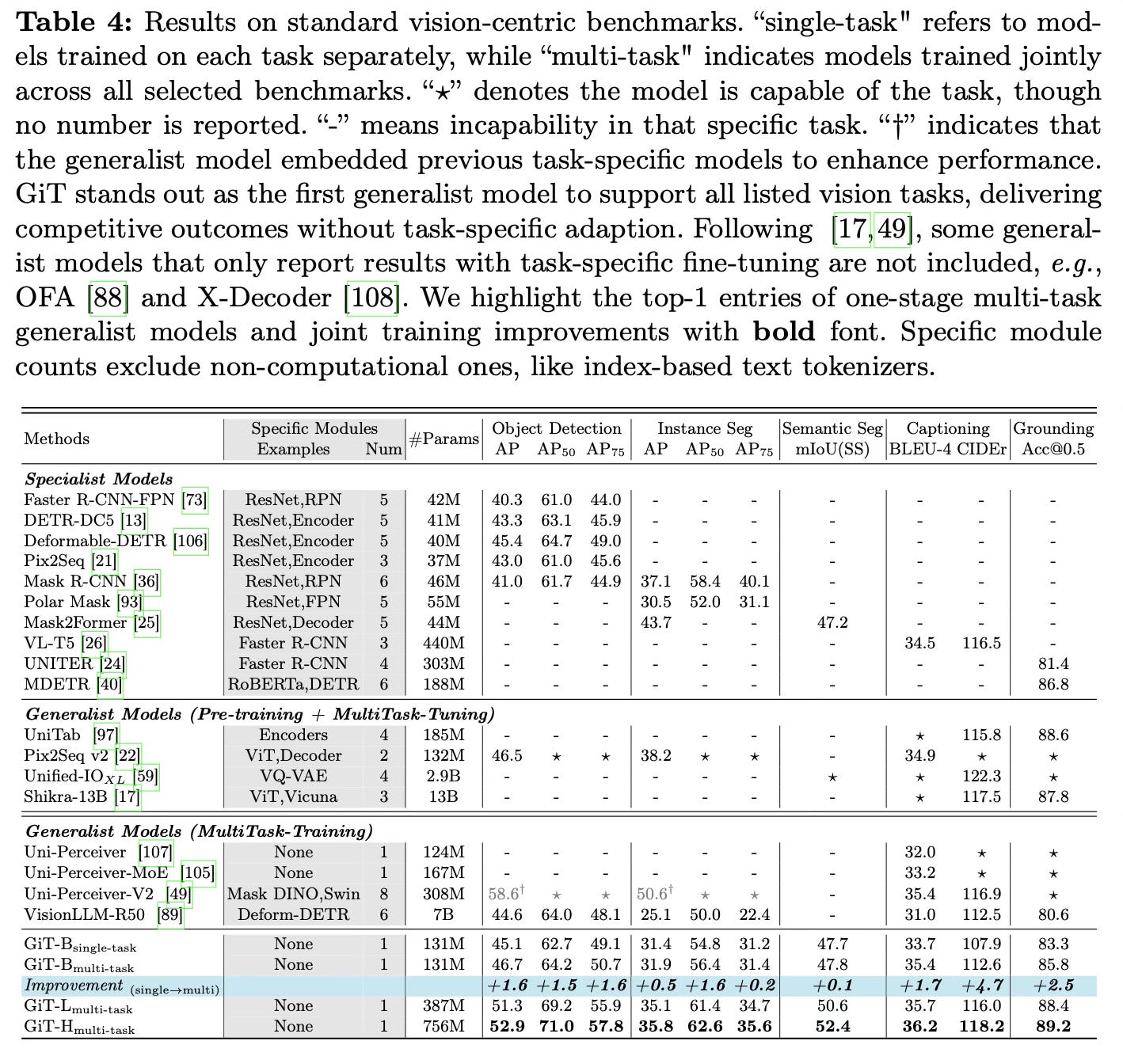
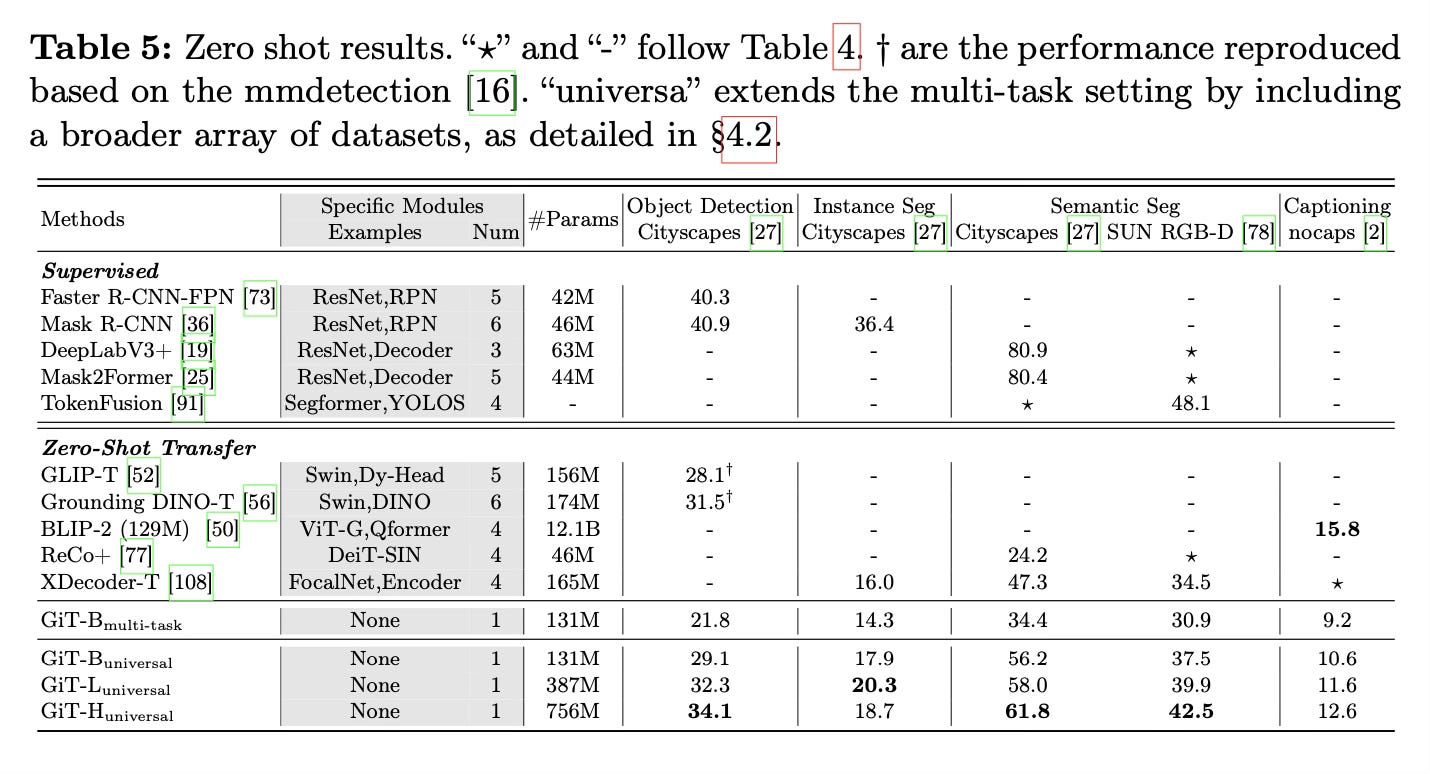
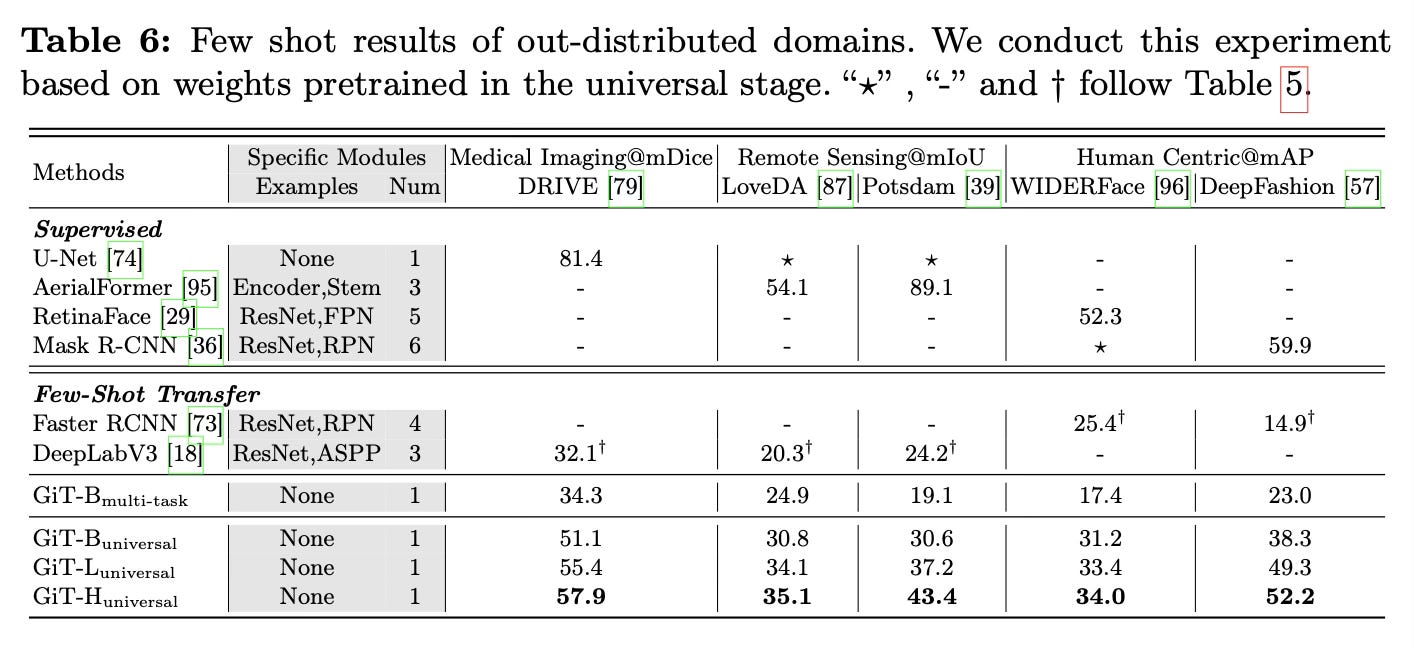
When scaled to larger models and trained on 27 diverse datasets, GiT becomes the first generalist model to demonstrate strong zero-shot and few-shot transfer abilities across various out-of-distribution domains and tasks.
Conclusion
The paper presents GiT, a simple yet powerful vision foundation model that utilizes a vanilla multi-layer transformer to unify diverse vision tasks through a universal language interface. GiT achieves competitive generalist performance, showcasing the multi-task capabilities of language models in the vision domain. For more details please consult the full paper.
Congrats to the authors for their work!
Code: https://github.com/Haiyang-W/GiT
Wang, Haiyang, et al. "GiT: Towards Generalist Vision Transformer through Universal Language Interface." ArXiv, 14 Mar. 2024, arxiv.org/abs/2403.09394v1.