
How Well Does GPT-4o Understand Vision? Evaluating Multimodal Foundation Models on Standard Computer Vision Tasks

Today's paper evaluates how well popular multimodal foundation models like GPT-4o understand vision by testing them on standard computer vision tasks. The authors develop a prompt chaining framework that translates traditional vision tasks into text-based queries that can be processed through API calls. This enables direct comparison between multimodal models and specialized vision models on established benchmarks.

Method Overview
A prompt chaining framework breaks down complex vision tasks into multiple simpler sub-tasks that can be solved through text-based prompting. The approach leverages the observation that most MFMs perform relatively well at image classification, so each vision task is decomposed into a series of classification problems.

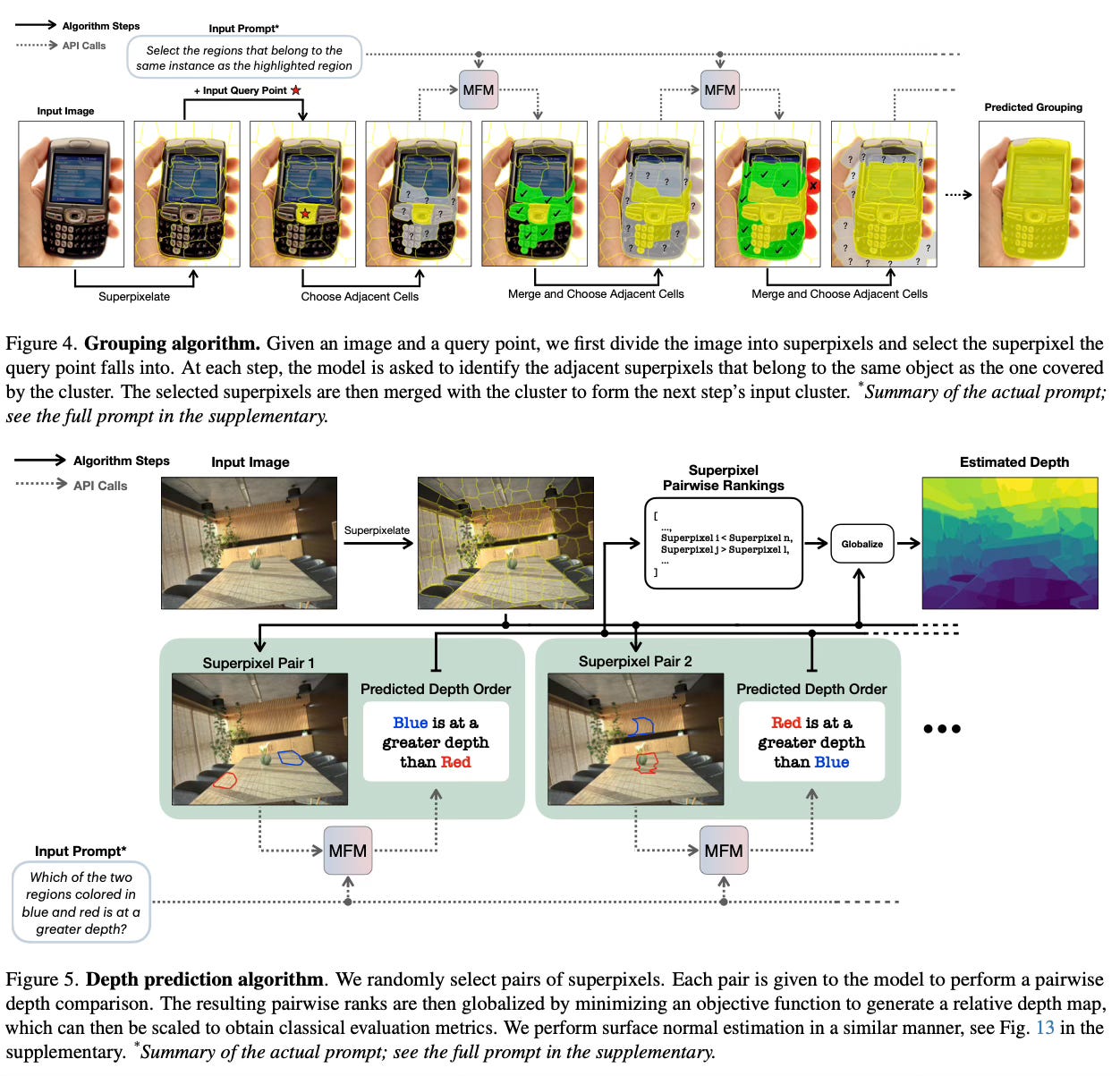
For object detection, the method uses recursive zooming where the image is divided into grid cells, and the model identifies which cells contain the target object. This process repeats with progressively finer grids until the object is precisely localized. For semantic segmentation, the image is first divided into superpixels using unsupervised clustering, then each superpixel is classified at multiple scales to provide context. The grouping task uses a graph-based approach where superpixels are nodes, and the model determines which adjacent superpixels belong to the same object as a query point.
For geometric tasks like depth and surface normal prediction, the method employs pairwise ranking. Random pairs of superpixels are presented to the model, which ranks them according to relative depth or surface orientation. These pairwise comparisons are then globalized using optimization techniques to produce complete depth maps or surface normal predictions. Throughout all tasks, the framework includes control baselines that apply the same algorithmic constraints to specialist vision models, ensuring fair comparisons.

Results
The evaluation reveals several key findings across seven major multimodal models. GPT-4o performs best among non-reasoning models, securing top position in 4 out of 6 tasks, followed by Gemini 2.0 Flash and other models. However, all MFMs lag significantly behind specialized vision models on every task, even when specialists are evaluated under the same prompt chaining constraints.
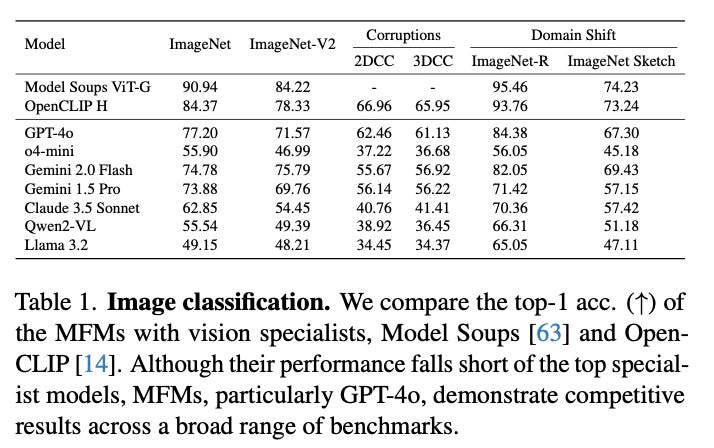
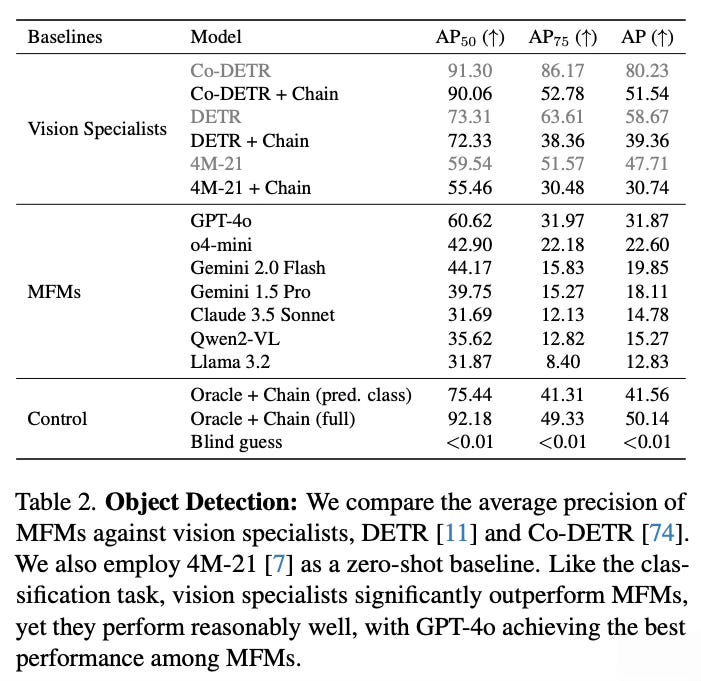
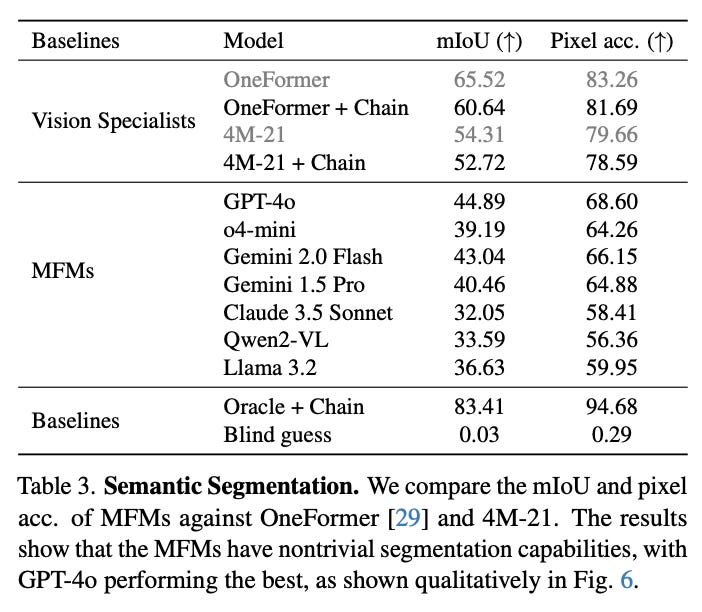
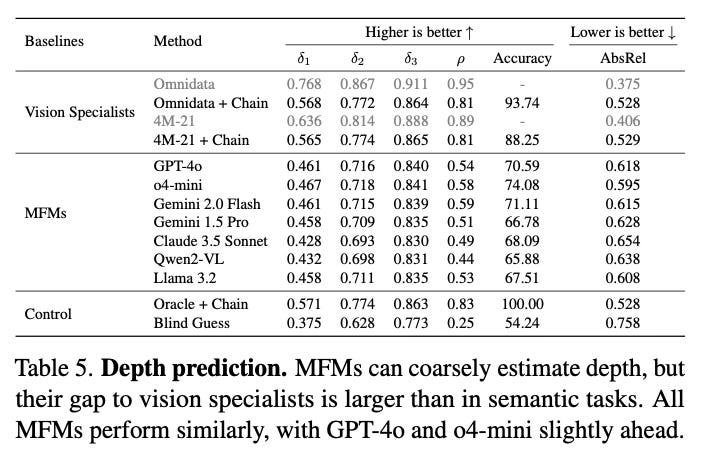
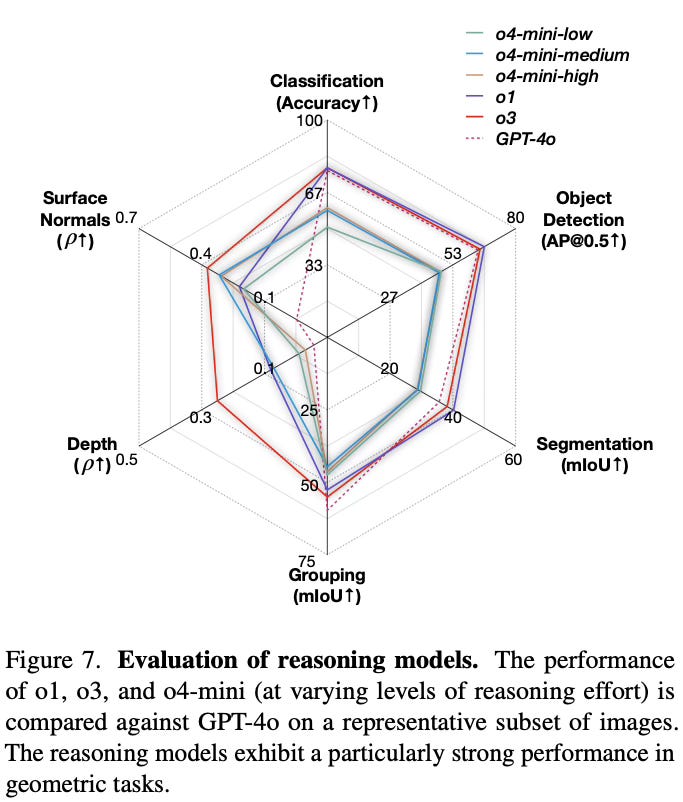
The models show notably better performance on semantic tasks (classification, detection, segmentation) compared to geometric tasks (depth, surface normals). Reasoning models like o1, o3, and o4-mini demonstrate particular improvements on geometric tasks, suggesting enhanced 3D understanding capabilities. The paper also finds that better-performing models exhibit less sensitivity to prompt variations, and that prompt chaining consistently outperforms direct prompting approaches.
Conclusion
This paper provides the first comprehensive benchmark for evaluating multimodal foundation models on standard computer vision tasks through a novel prompt chaining framework. While current MFMs demonstrate respectable performance as generalists, they still fall short of specialized vision models across all evaluated tasks. For more information please consult the full paper.
Congrats to the authors for their work!
Ramachandran, Rahul, et al. "How Well Does GPT-4o Understand Vision? Evaluating Multimodal Foundation Models on Standard Computer Vision Tasks." arXiv preprint arXiv:2507.01955, 2025.