
Iterative Reasoning Preference Optimization

Today’s paper explores critical design decisions when building vision-language models (VLMs) that are often not well justified in the literature. The authors argue this impedes progress in identifying what choices actually improve model performance. Leveraging the findings they introduce Idefics2, an efficient 8B parameter foundational VLM.
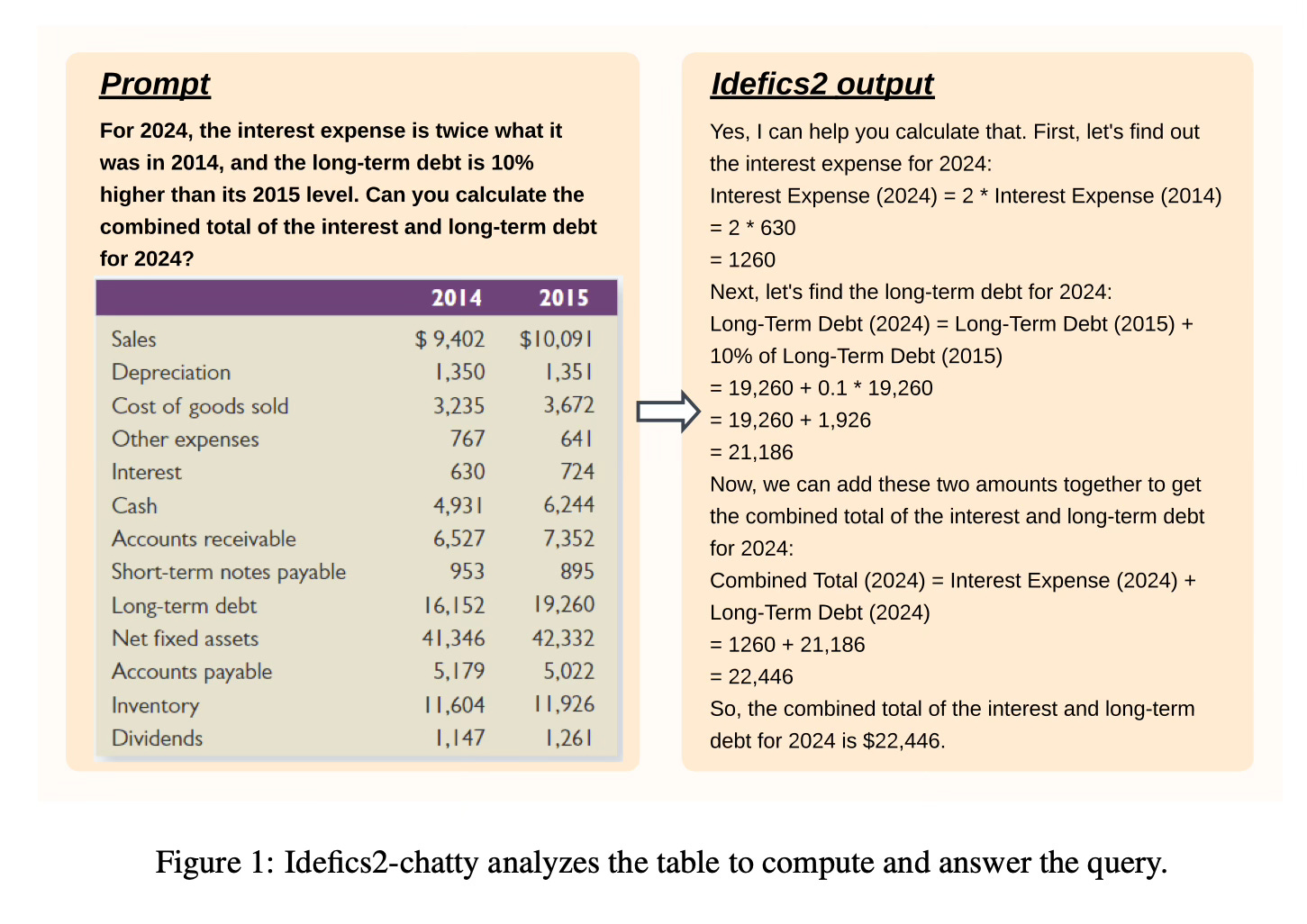
Method Overview
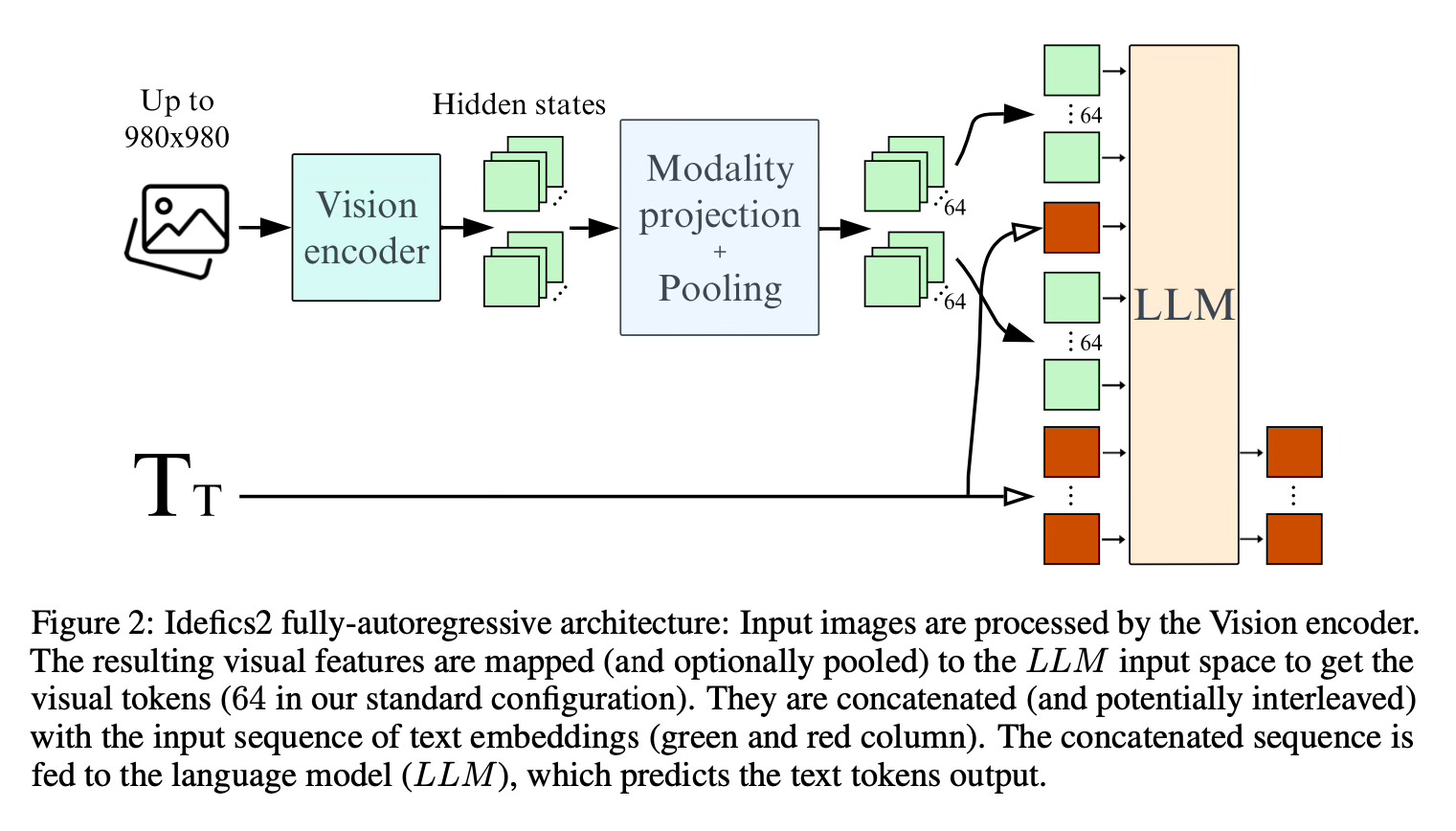
The authors conduct extensive experiments around pre-trained models, architecture choice, data, and training methods for VLMs. They compare the fully autoregressive architecture, where the vision encoder output is concatenated with the text embeddings and fed into the language model, vs the cross-attention architecture that injects image information via cross-attention at different layers of the language model.
The make the following findings:
Finding 1. “For a fixed number of parameters, the quality of the language model backbone has a higher impact on the performance of the final VLM than the quality of the vision backbone.”
Finding 2. “The cross-attention architecture performs better than the fully autoregressive one when unimodal pre-trained backbones are kept frozen. However, when training the unimodal backbones, the fully autoregressive architecture outperforms the cross-attention one, even though the latter has more parameters.”
Finding 3. “Unfreezing the pre-trained backbones under the fully autoregressive architecture can lead to training divergences. Leveraging LoRA still adds expressivity to the training and stabilizes it.”
Finding 4. “Reducing the number of visual tokens with learned pooling significantly improves compute efficiency at training and inference while improving performance on downstream tasks.”
Finding 5. “Adapting a vision encoder pre-trained on fixed-size square images to preserve images’ original aspect ratio and resolution does not degrade performance while speeding up training and inference and reducing memory.”
Finding 6. “Splitting images into sub-images during training allow trading compute efficiency for more performance during inference. The increase in performance is particularly noticeable in tasks involving reading text in an image.”
Leveraging the insights from their experiments, the authors train Idefics2, an efficient 8B parameter foundational VLM.
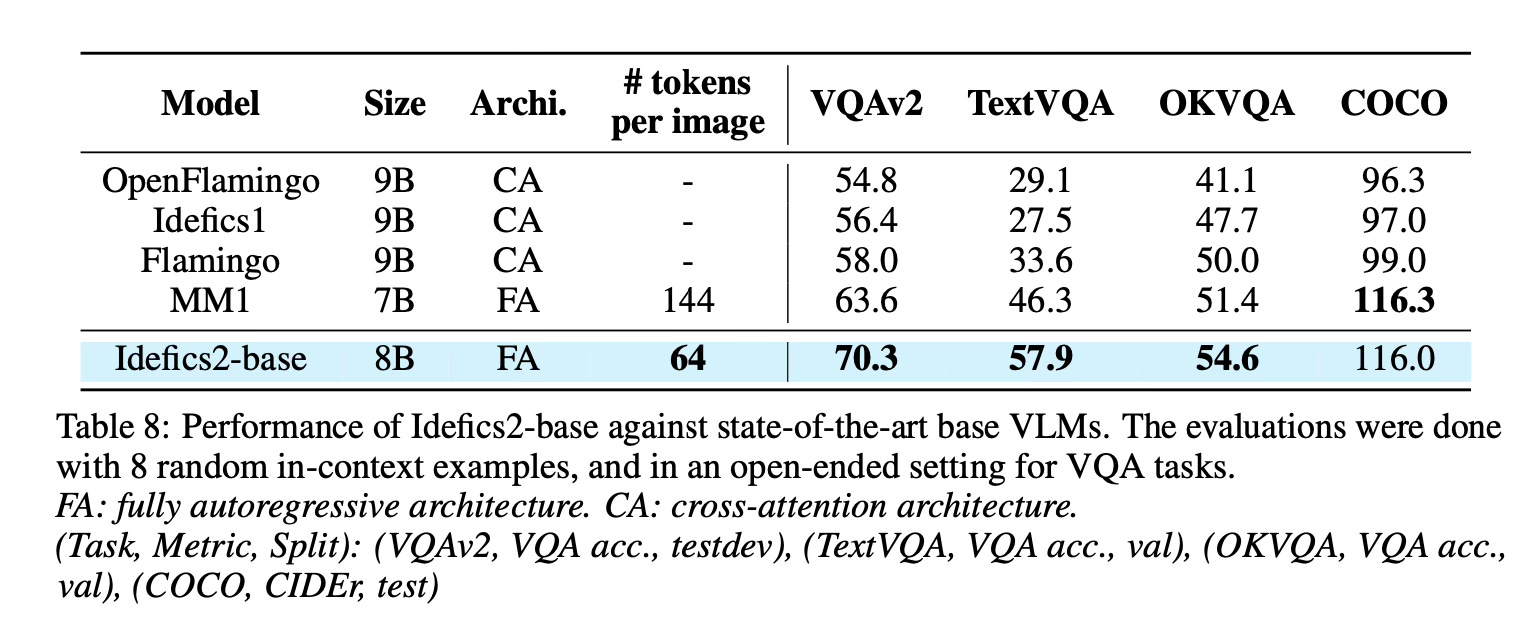
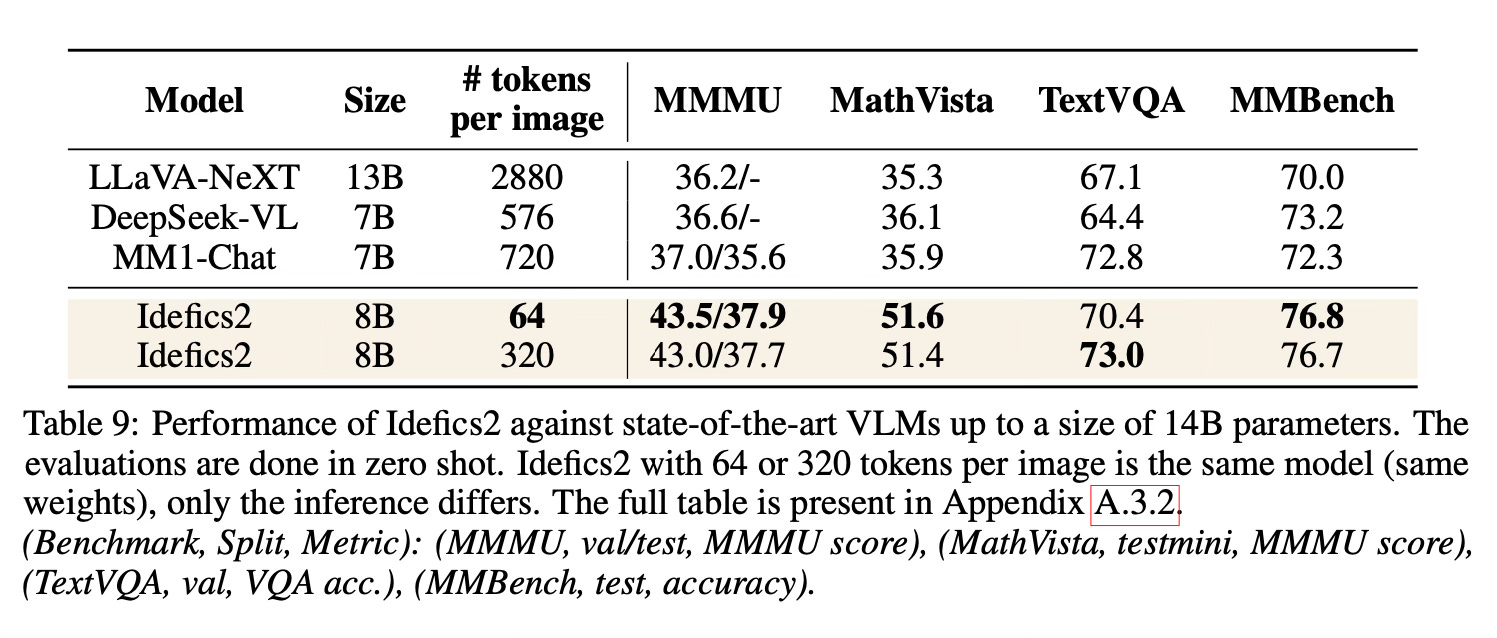
Results
Idefics2 achieves state-of-the-art performance in its size category across various multimodal benchmarks, often matching models 4x its size.

Conclusion
The paper provides useful insights into architecture choices, training methods, and efficiency optimizations for vision-language models. The authors open-source the Idefics2 model in base, instructed, and chat versions along with the datasets used to train it as a resource for the community. For more information please consult the full paper.
Code and data: https://huggingface.co/collections/HuggingFaceM4/idefics2-661d1971b7c50831dd3ce0fe
Congrats to the authors for their work!
Laurençon, Hugo, et al. "What matters when building vision-language models?" arXiv preprint arXiv:2405.02246 (2024).