
Judging What We Cannot Solve: A Consequence-Based Approach for Oracle-Free Evaluation of Research-Level Math

Today’s paper addresses the significant challenge of verifying complex mathematical solutions generated by Large Language Models (LLMs). As models increasingly demonstrate the ability to attempt research-level mathematics, the validation of these attempts remains a bottleneck, often requiring scarce expert time or relying on automated judges that can be biased and unreliable. The paper introduces a novel, oracle-free evaluation framework designed to distinguish correct solutions from plausible-sounding incorrect ones without needing access to ground-truth answers.
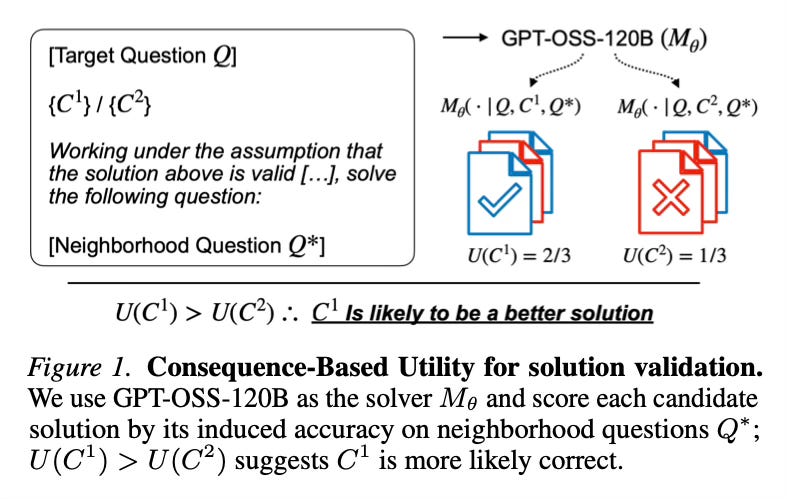
Method Overview
The core concept relies on the hypothesis that a correct mathematical solution contains useful method-level information that can be generalized. Instead of asking an evaluator to simply look at a solution text and guess its validity based on appearance or surface-level logic, the method tests the “utility” of the solution’s reasoning. It essentially asks: if this solution is used as a guide, does it help solve other, similar problems?

To implement this, the system takes a research-level question and a candidate solution generated by a model. It utilizes a set of “neighborhood” questions—closely related problems that are verifiable (meaning the answer is known or easily checked). The solver is then prompted to solve these neighborhood questions using the original candidate solution as an in-context exemplar. The system scores the candidate based on how much it improves the solver’s accuracy on these related tasks.
If the candidate solution provides valid reasoning that helps the model solve the neighborhood questions accurately, it receives a high utility score, indicating it is likely correct. Conversely, hallucinated or flawed solutions tend to provide poor guidance, resulting in lower performance on the related tasks. This approach effectively shifts evaluation from direct textual inspection to the empirical testing of consequences.
Results
The paper evaluates the approach on a newly curated dataset called EXPERTMATH, which consists of expert-written research-level problems and LLM-generated questions. The analysis demonstrates that the proposed Consequence-Based Utility consistently outperforms standard oracle-free baselines, including reward models, generative reward models, and direct LLM judges.
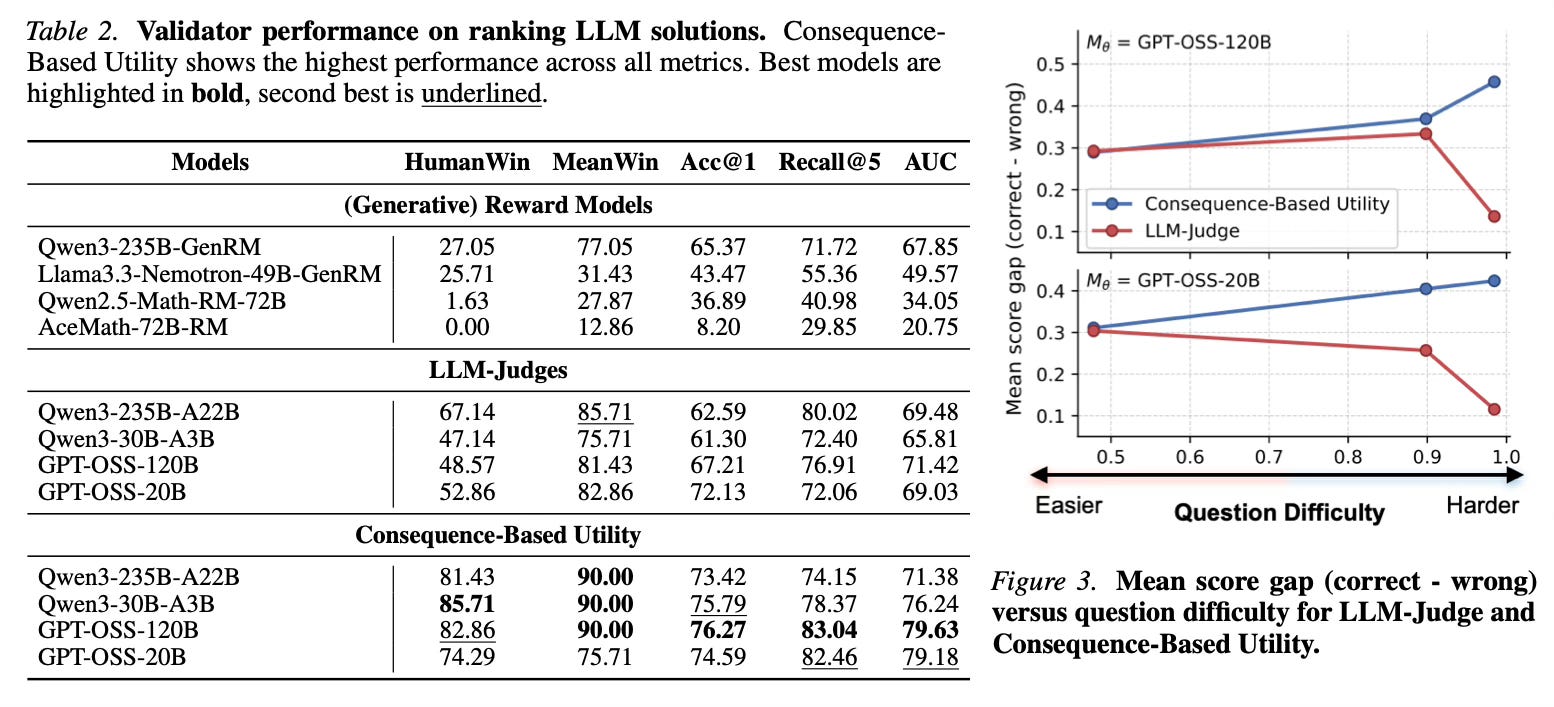
Notably, when applied to the GPT-OSS-120B model, the method improved the accuracy (Acc@1) from 67.2% to 76.3% and the AUC from 71.4 to 79.6 compared to using the model as a standard judge. Additionally, the approach exhibits a larger “solver–evaluator gap,” meaning it maintains a strong separation between correct and incorrect solutions even on difficult instances where the underlying model often fails to solve the problem itself. Error analysis reveals that the method is less sensitive to stylistic cues and authoritative tones that often mislead standard LLM judges, reliably penalizing solutions with incorrect reasoning or unjustified steps.
Conclusion
This work presents a scalable framework for validating mathematical reasoning by measuring the downstream utility of a solution on related problems. By identifying correct solutions based on their ability to assist in solving neighborhood questions, the paper offers a robust alternative to direct judging. The release of the EXPERTMATH dataset and the demonstrated efficacy of consequence-based scoring provide a pathway for more reliable automated evaluation in scientific domains.
For more information please consult the full paper.
Congrats to the authors for their work!
Son, Guijin, et al. “Judging What We Cannot Solve: A Consequence-Based Approach for Oracle-Free Evaluation of Research-Level Math.” arXiv preprint arXiv:2602.06291 (2026).