
Multimodal OCR: Parse Anything from Documents

Today’s paper tackles the limitations of conventional document parsing systems that primarily focus on text extraction. Currently, most Optical Character Recognition (OCR) systems treat non-textual elements like charts, diagrams, and user interface components simply as cropped images, discarding the valuable structural and semantic information embedded within them. The main idea is to introduce a Multimodal OCR (MOCR) paradigm that jointly parses both text and graphics into unified, structured textual representations, enabling more faithful document reconstruction and better extraction of visual data.
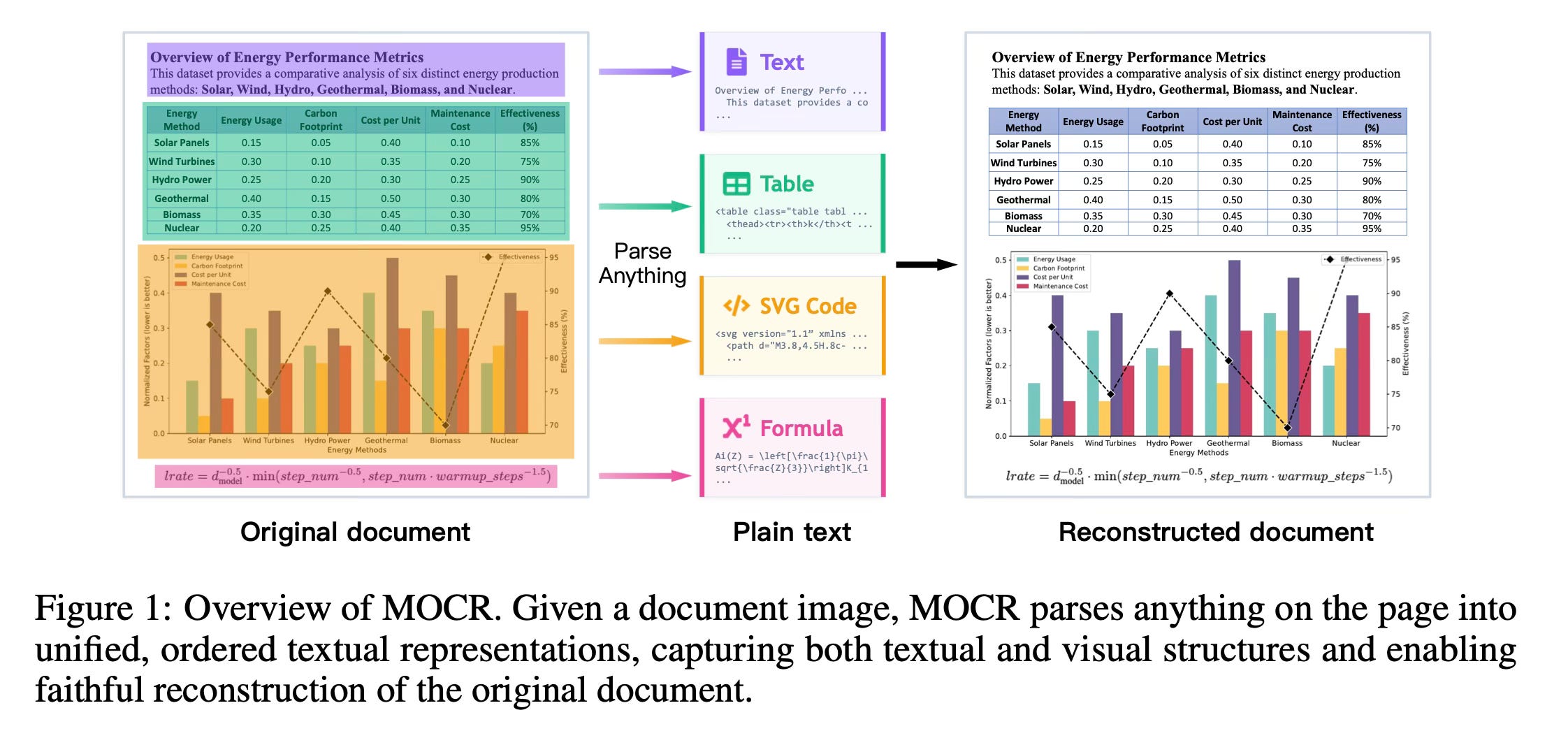
Method Overview
The method has a pipeline that treats visual elements—such as charts, diagrams, tables, and icons—as first-class parsing targets alongside standard text. Instead of extracting a static picture of a chart, the model translates the visual information directly into renderable code, such as Scalable Vector Graphics (SVG). This allows the system to read a document page and output an ordered sequence that reconstructs both the textual content and the geometric details of the graphics in a machine-readable format.
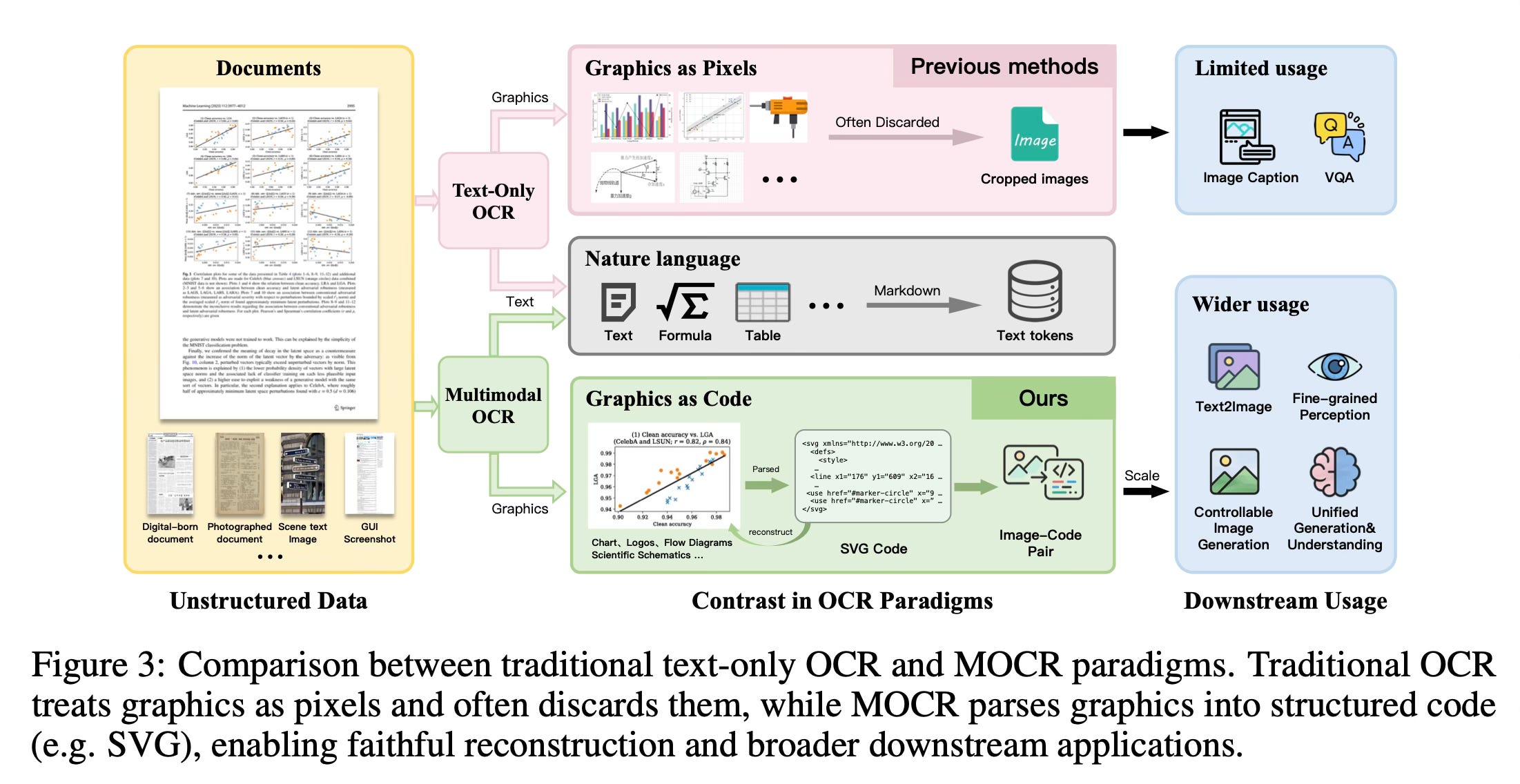
To support this, the system, termed dots.mocr, relies on a three-part architecture: a high-resolution vision encoder built from scratch, a lightweight connector, and an autoregressive language model decoder. The high-resolution input ensures the system can preserve fine details in dense layouts and precisely locate graphic primitives like chart markers or diagram strokes. The decoder then processes these visual features to generate long, highly structured text outputs representing the entire document page.
Training this model requires a comprehensive data engine that collects information from PDFs, rendered webpages, and native SVG graphics. The training process follows a staged recipe, starting with general vision-language alignment, moving to broad document parsing, and finally focusing on the specific task of converting complex graphics into structured code. By normalizing the target codes and enforcing quality control during training, the model successfully learns to handle the challenge of converting visually identical graphics into standardized underlying code.
Results
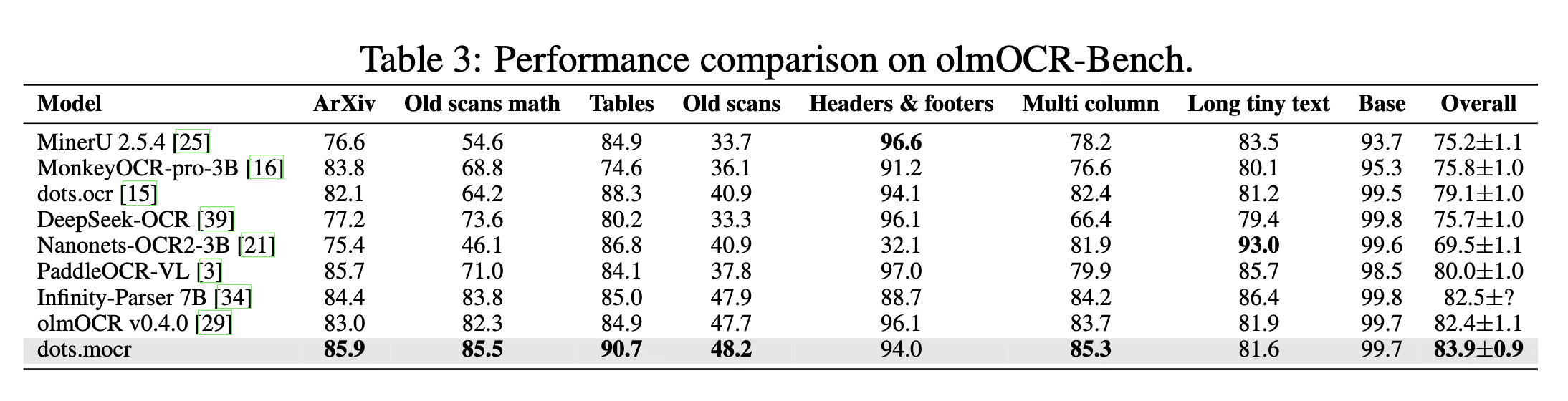
The paper highlights strong performance across both standard document parsing and structured graphics reconstruction. On standard document parsing benchmarks, the dots.mocr model achieves a new state-of-the-art score of 83.9 on the olmOCR-Bench and consistently surpasses existing open-source systems. To evaluate the results more holistically, the paper introduces an automated evaluation framework called OCR Arena, which uses a large language model to calculate an Elo rating based on pairwise comparisons. In this arena, the model ranks second only to the proprietary Gemini 3 Pro. Furthermore, in structured graphics parsing tasks, a specialized version of the model achieves higher reconstruction quality than Gemini 3 Pro across various benchmarks, including charts, UI layouts, scientific figures, and chemical diagrams.
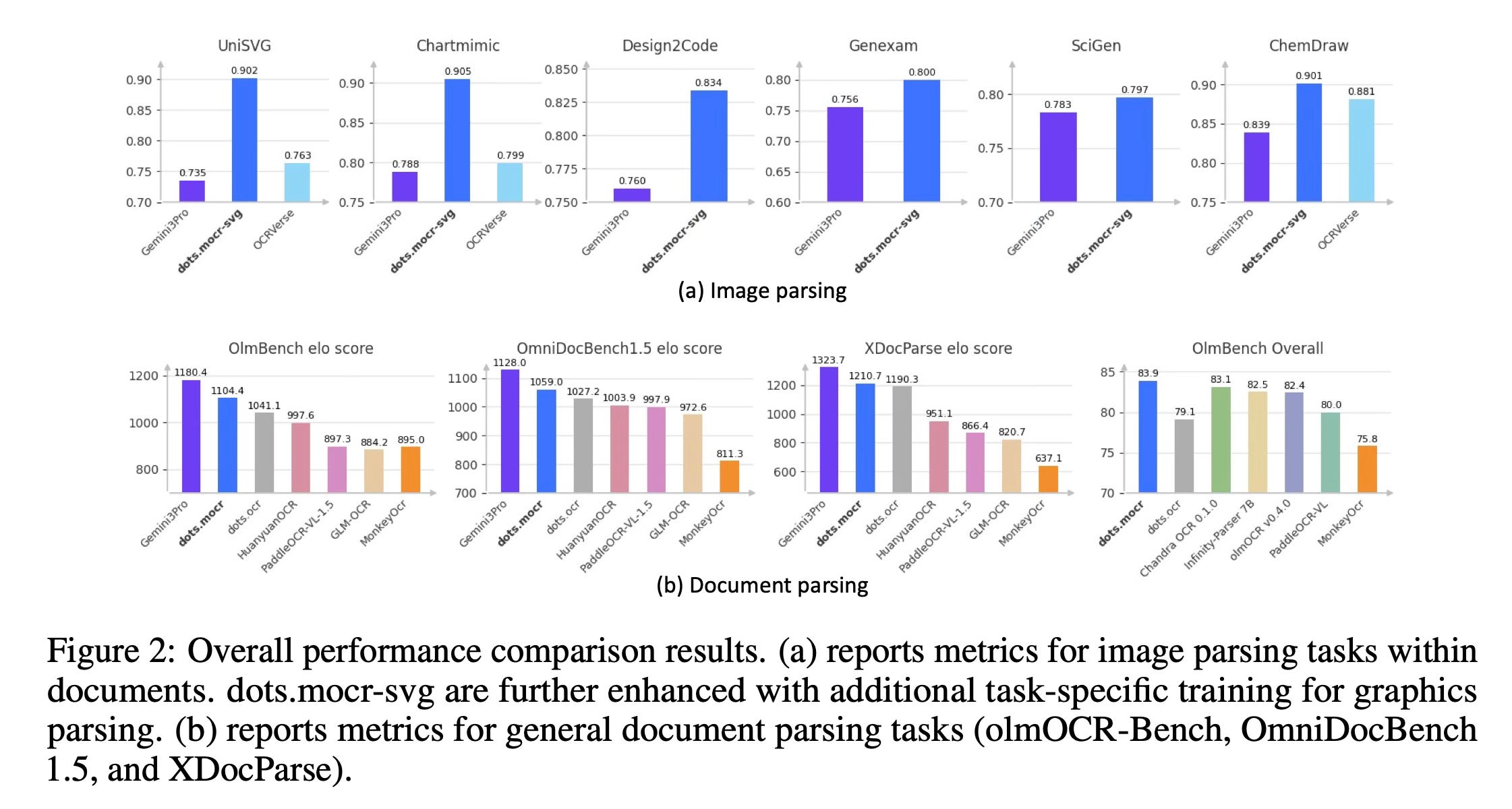
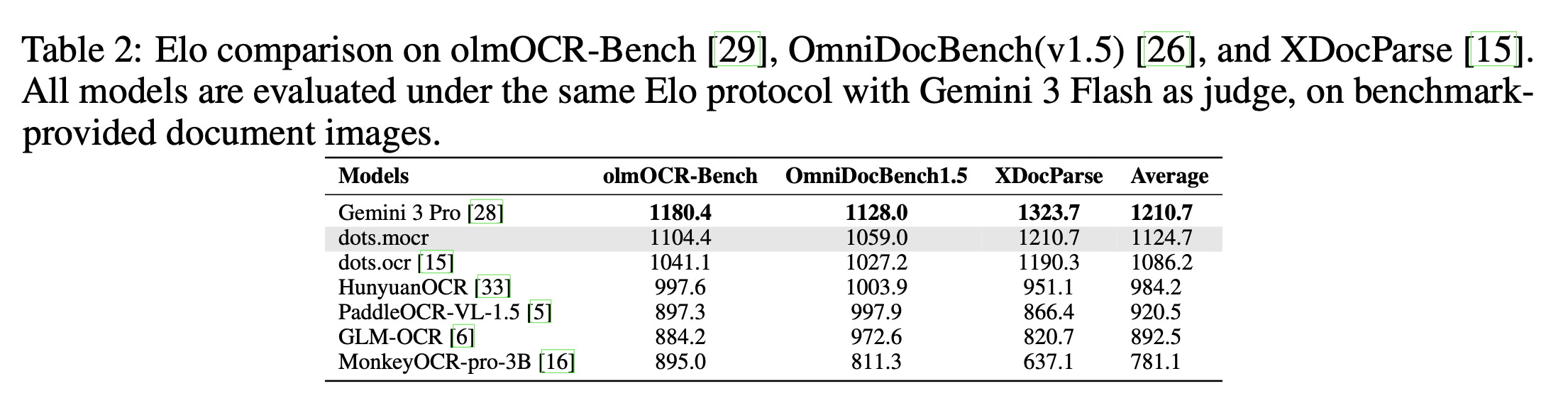

Conclusion
In summary, the paper presents a unified paradigm for parsing both text and graphical elements within documents into structured, reusable code. By treating graphics as code-level parsing targets rather than pixel crops, the method unlocks a massive new source of supervision from existing documents. The resulting model demonstrates highly competitive performance across a wide range of parsing tasks while maintaining a compact parameter size.
For more information please consult the full paper.
Congrats to the authors for their work!
Zheng, Handong, et al. “Multimodal OCR: Parse Anything from Documents.” arXiv preprint arXiv:2603.13032 (2026).