
Qwen3-Coder-Next Technical Report

Today’s paper introduces Qwen3-Coder-Next, an open-weight language model designed specifically for coding agents and local development. The paper addresses the challenge of enabling models to reason over long horizons, interact with real execution environments, and autonomously recover from errors during complex software development tasks. Instead of relying solely on static code data, the approach focuses on scaling agentic training through verifiable tasks and direct environment feedback to push the capability limits of efficient models.
Method Overview
The method functions by training a large language model using a specialized process that mimics real-world software engineering workflows. Instead of merely processing static text, the model learns by actively interacting with executable computer environments. It practices tasks such as fixing bugs, running tests, and interpreting feedback from the system to see if the code works. This approach allows the model to develop skills in navigating complex coding scenarios and recovering from mistakes, rather than just learning code syntax.
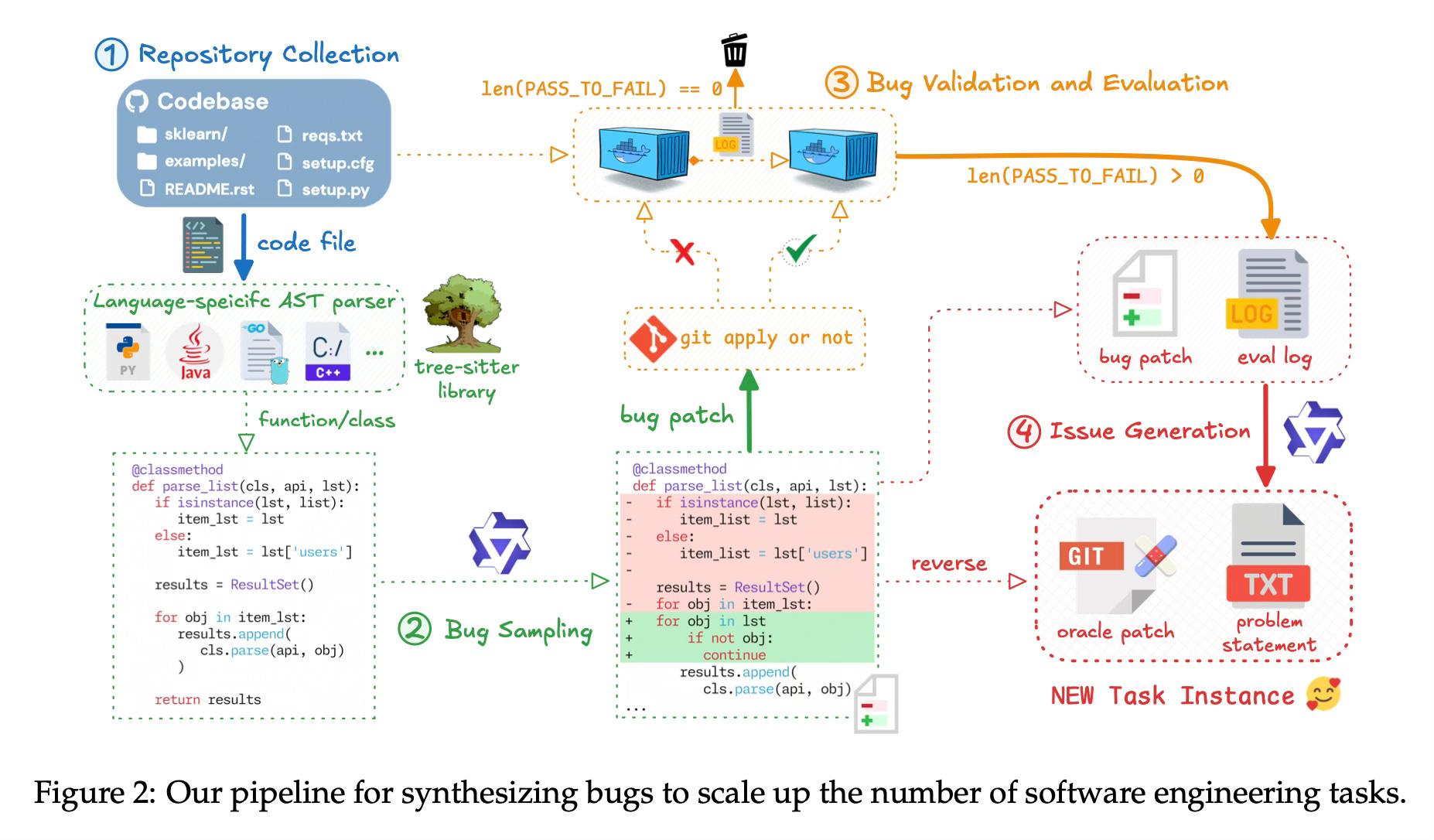
To support this learning process, the paper establishes a large-scale pipeline for synthesizing training tasks. This involves two main strategies: mining real-world issues from GitHub pull requests and systematically injecting bugs into existing codebases. Each generated task is paired with a fully executable environment, such as a Docker container, which includes the necessary dependencies and test suites. This infrastructure allows the system to run the generated code and verify the output, providing a feedback loop that is essential for training reliable agents.
The underlying architecture utilizes a Mixture-of-Experts (MoE) design, which contains 80 billion parameters in total but activates only 3 billion during inference. This ensures high efficiency and low latency. The training pipeline is staged: it begins with a pretrained base model, followed by mid-training that shifts focus toward repository-level code and synthetic data. Finally, the method employs supervised fine-tuning where multiple expert models—specialized in areas like web development or quality assurance—are distilled into a single, unified model capable of handling diverse agentic tasks.

Results
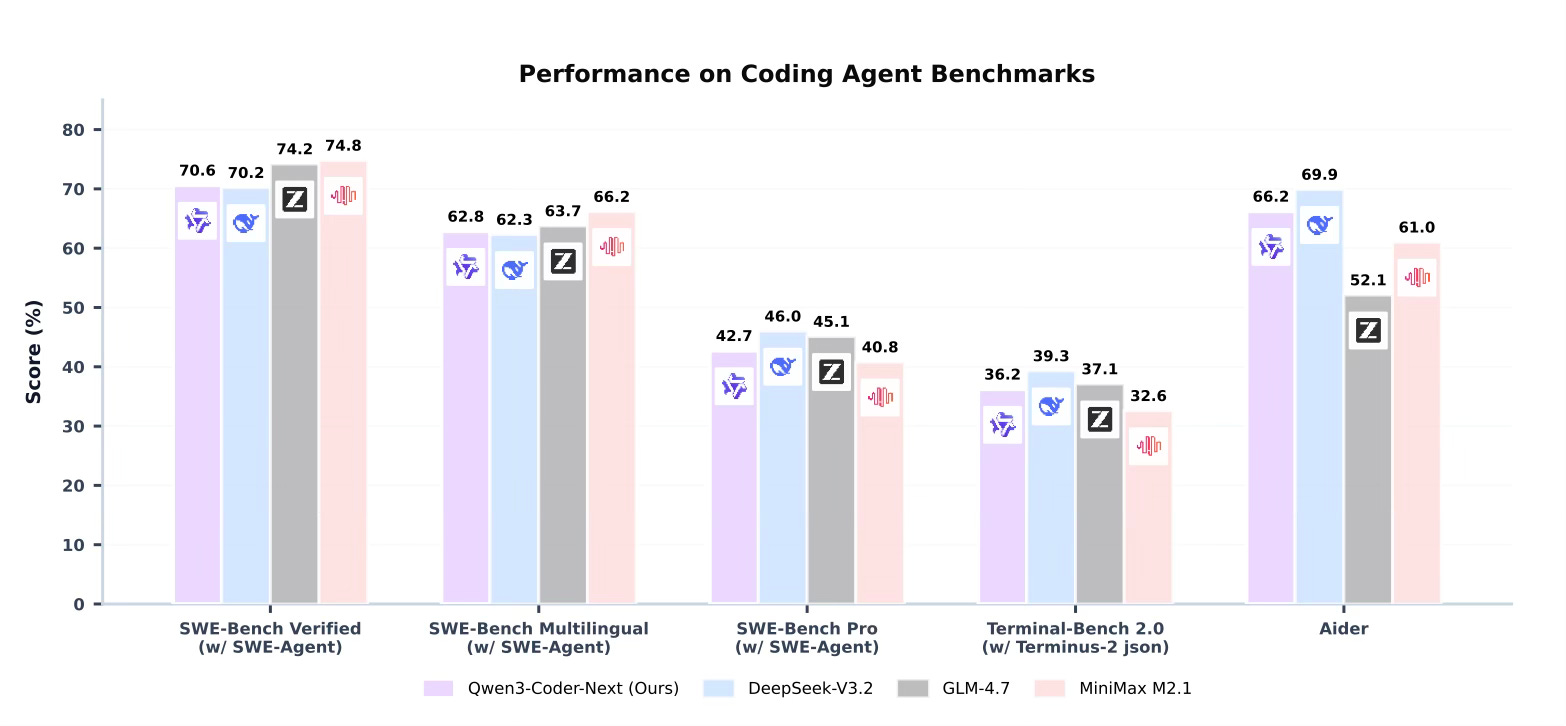
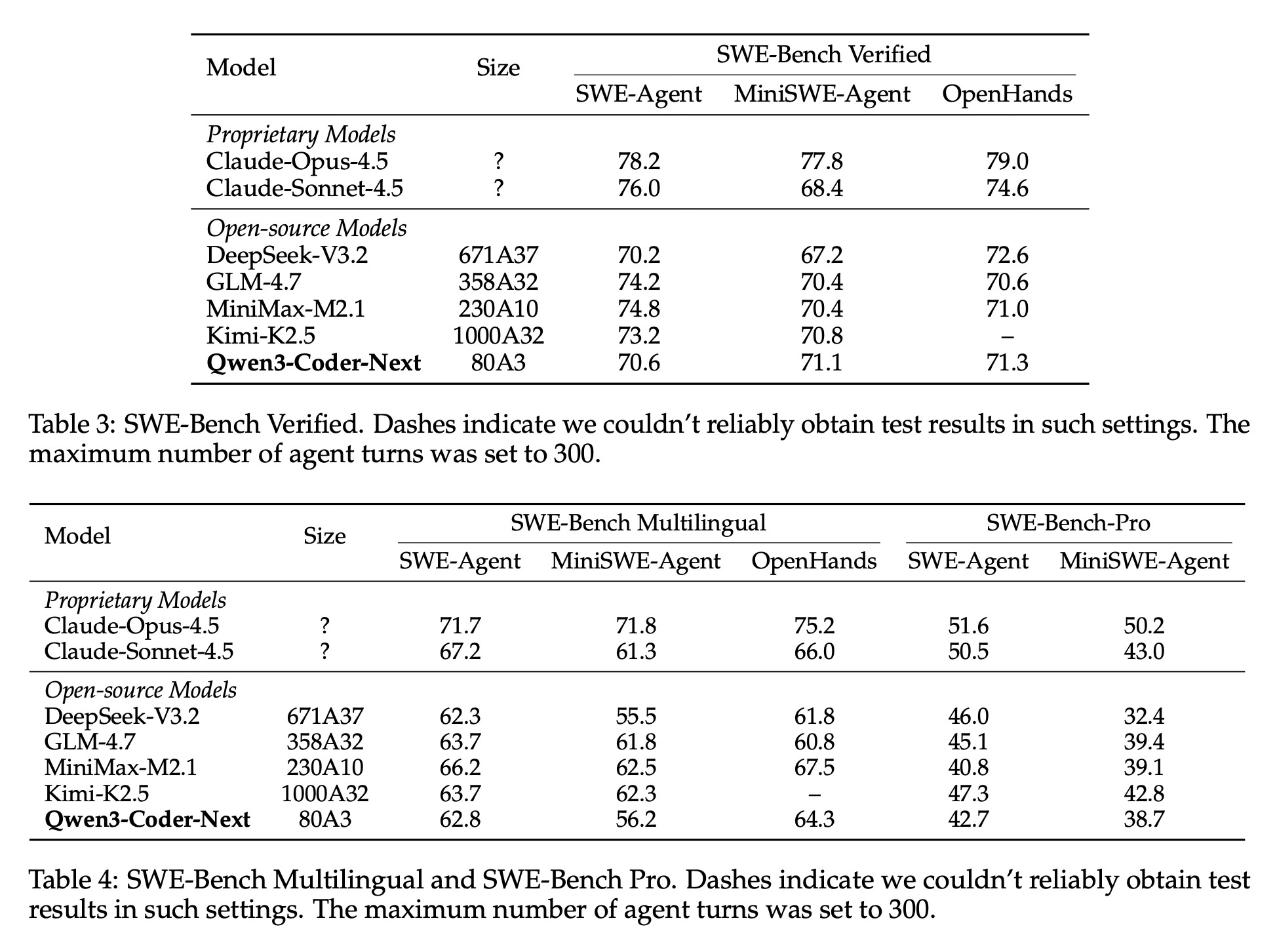
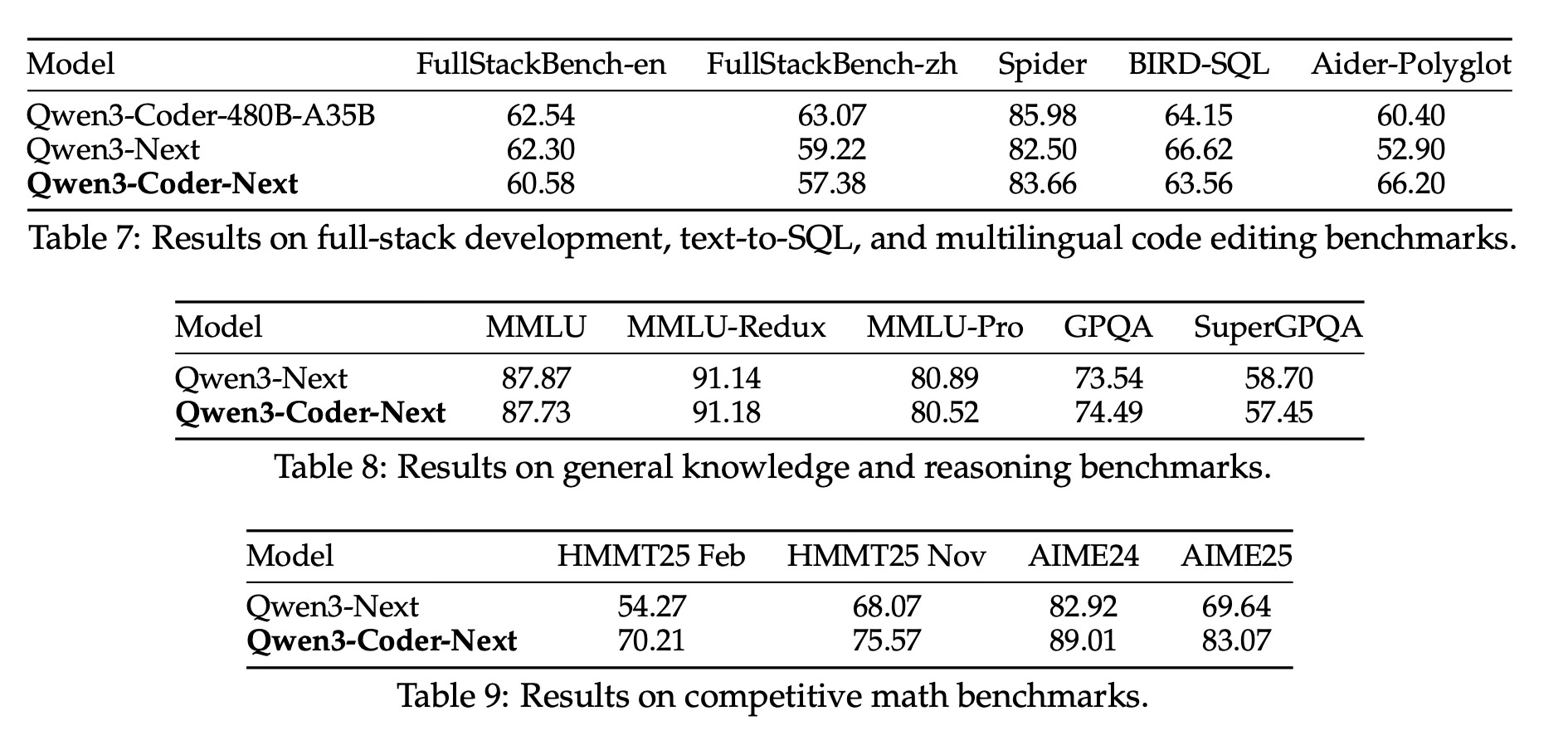
The paper reports that Qwen3-Coder-Next achieves competitive performance across various agent-centric benchmarks, including SWE-Bench Verified, SWE-Bench Pro, and Terminal-Bench. Despite having a relatively small active parameter footprint of 3 billion, the model matches or outperforms several other models that require significantly more active compute. The evaluation demonstrates that the model is particularly effective at resolving real-world software engineering issues and handling multi-step coding workflows. These findings suggest that scaling agentic training and environment interaction is a primary driver for advancing coding agent capabilities, proving more impactful than simply increasing model size alone.
Conclusion
In summary, this paper presents a comprehensive methodology for developing efficient coding agents by prioritizing verifiable, executable tasks and environment feedback. By combining a large-scale synthesis pipeline with a hybrid Mixture-of-Experts architecture, Qwen3-Coder-Next offers a powerful solution for automated software development that balances high performance with deployment efficiency.
For more information please consult the full paper.
Congrats to the authors for their work!
Qwen Team. “Qwen3-Coder-Next Technical Report.” arXiv preprint arXiv:2603.00729, 2026, https://huggingface.co/papers/2603.00729.