
Reverse Thinking Makes LLMs Stronger Reasoners

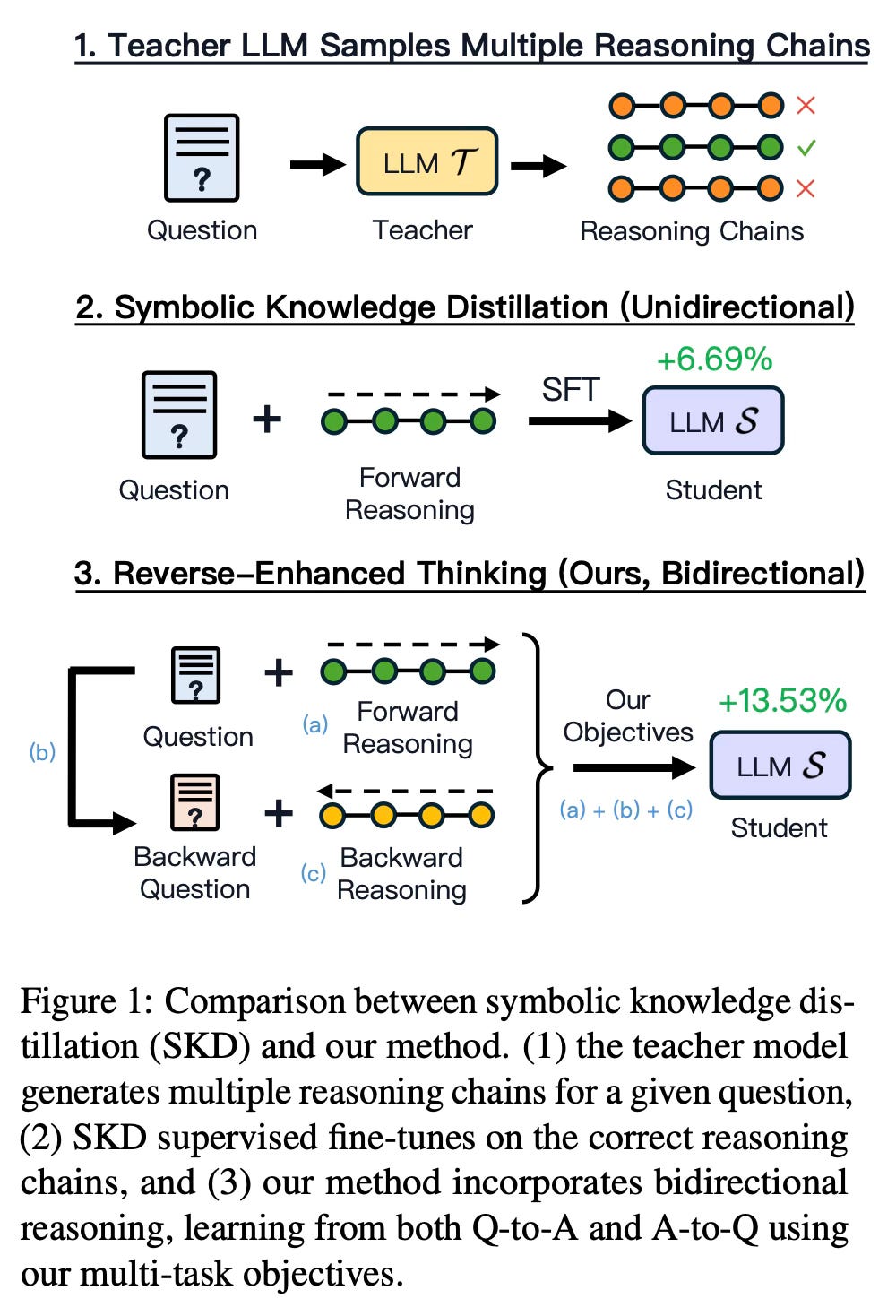
Today's paper introduces REVTHINK, a framework that enhances language models' reasoning capabilities by teaching them to think both forward and backward. The approach is inspired by how humans solve problems - not just reasoning from question to answer, but also verifying solutions by working backward from the answer to the original question. This bidirectional thinking approach leads to improved reasoning performance across various tasks.
Method Overview
REVTHINK has two main stages: data augmentation and student model training. In the first stage, a teacher model (a larger language model) generates three components for each training example: forward reasoning, a backward question, and backward reasoning. The backward question essentially reverses the original problem - for example, if the original question asks "John has 3 apples and Emma has 2, how many do they have total?", the backward question would be "John and Emma have 5 apples total. If Emma has 2, how many does John have?"
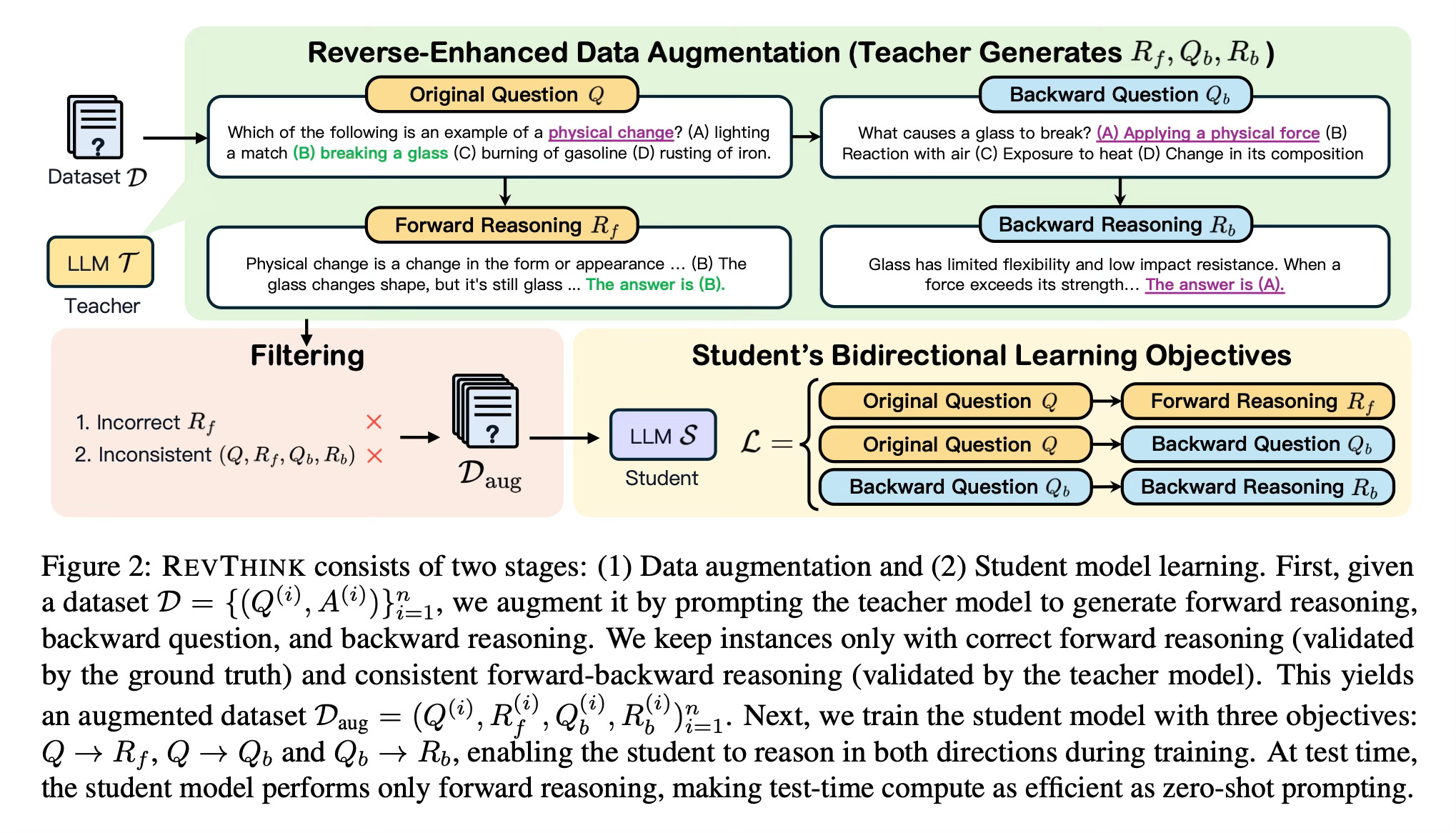
The method carefully filters these generated examples, keeping only those where the forward reasoning is correct and the backward reasoning is consistent with the original question. This ensures high-quality training data.
In the second stage, a smaller student model is trained using three objectives: generating forward reasoning from the question, generating backward questions from the original question, and generating backward reasoning from the backward question. This multi-task approach helps the model internalize both forward and backward reasoning patterns.
Importantly, while the model learns both forward and backward reasoning during training, at test time it only performs forward reasoning, making it as computationally efficient as standard approaches.
Results
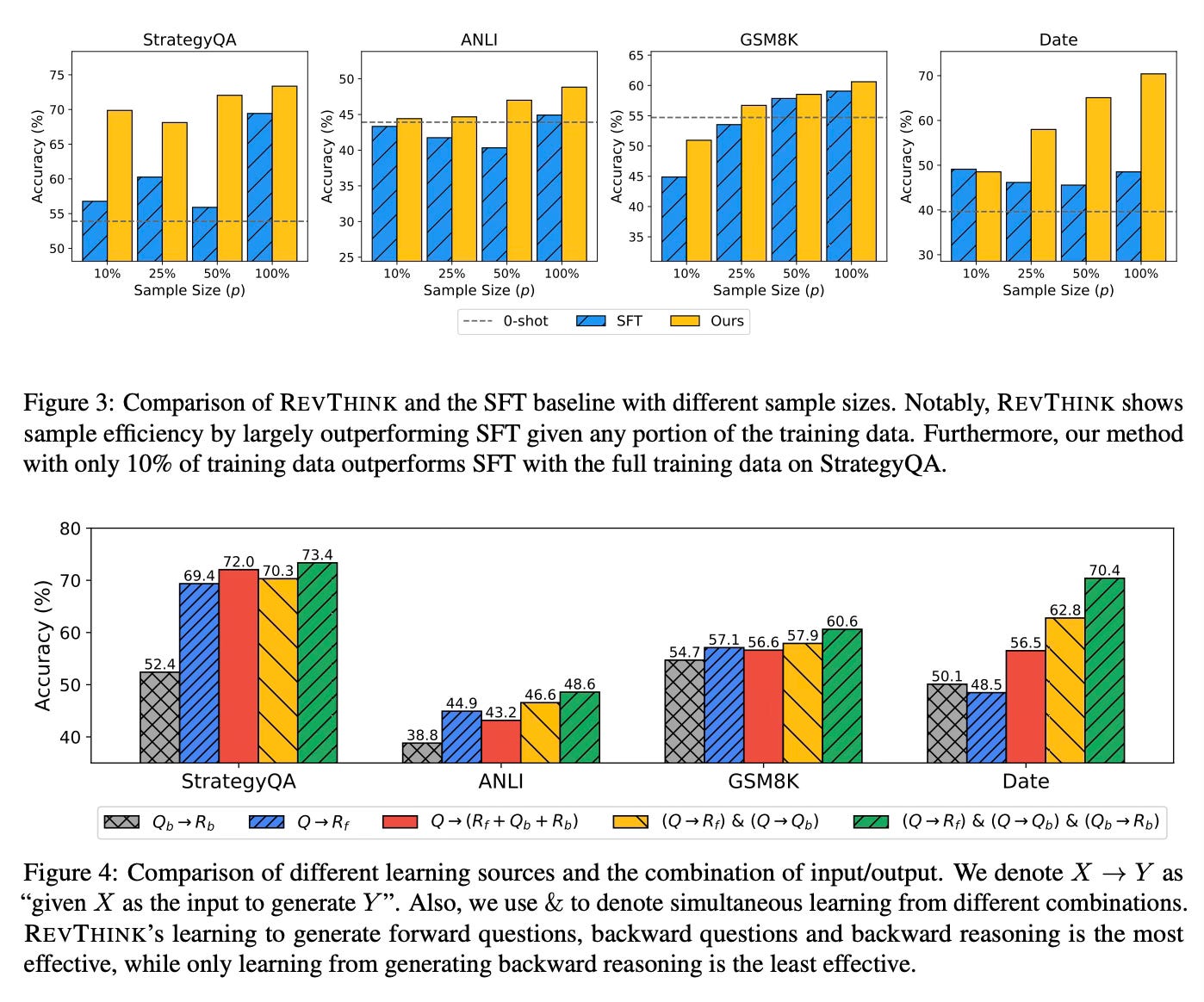
The method demonstrates significant improvements across 12 different datasets covering commonsense, mathematical, and logical reasoning tasks. Key findings include:

13.53% average improvement over zero-shot performance
6.84% improvement over traditional knowledge distillation methods
Effective scaling with model size, where a 7B parameter model with REVTHINK outperforms a 176B parameter model's zero-shot performance
Strong generalization to out-of-distribution datasets
Conclusion
REVTHINK presents an effective approach for enhancing language models' reasoning capabilities through bidirectional thinking. By incorporating both forward and backward reasoning during training, the method achieves significant improvements across various reasoning tasks while maintaining efficient inference. For more information please consult the full paper.
Congrats to the authors for their work!
Chen, Justin Chih-Yao, et al. "Reverse Thinking Makes LLMs Stronger Reasoners." arXiv preprint arXiv:2411.19865 (2024).