
SEAgent: Self-Evolving Computer Use Agent with Autonomous Learning from Experience

Today's paper presents SEAgent, a self-evolving computer-use agent that learns to operate unfamiliar desktop software without human-labeled data. It combines an in-context task generator, a trajectory-aware reward model, and reinforcement learning to acquire skills through experience, moving from simple actions to complex workflows.
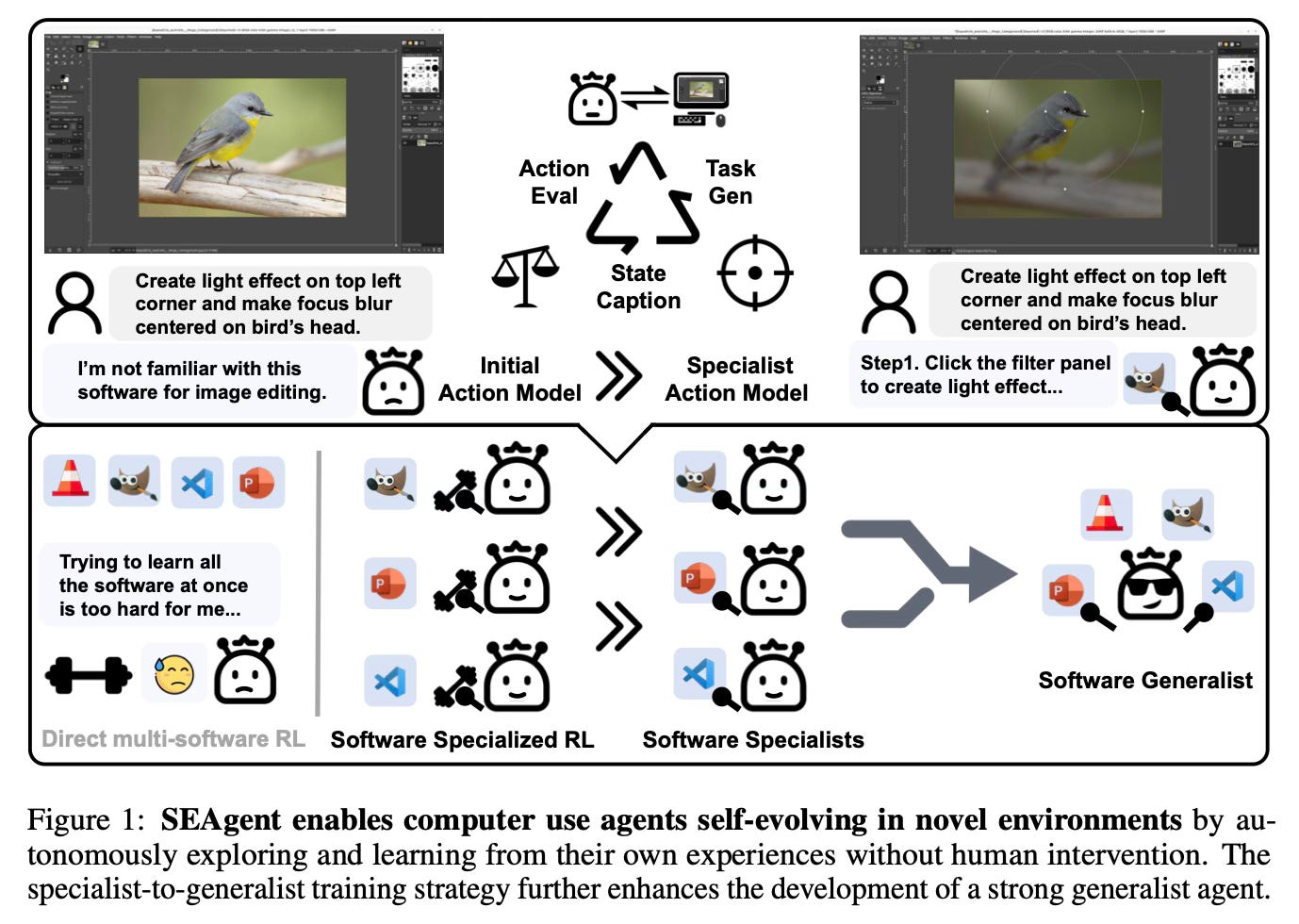
Method Overview
At a high level, the method runs an agent in a new software environment which has the ability to try actions, evaluate what happened or propose the next set of training tasks. Three components work together:
An Actor Model that interacts with the GUI using mouse and keyboard actions to complete tasks.
A World State Model that looks at the entire action history with screenshots, describes state changes, and judges success or failure step by step.
A Curriculum Generator that builds a “software guidebook” from what the agent learns and uses it to create new tasks that gradually increase in diversity and difficulty.
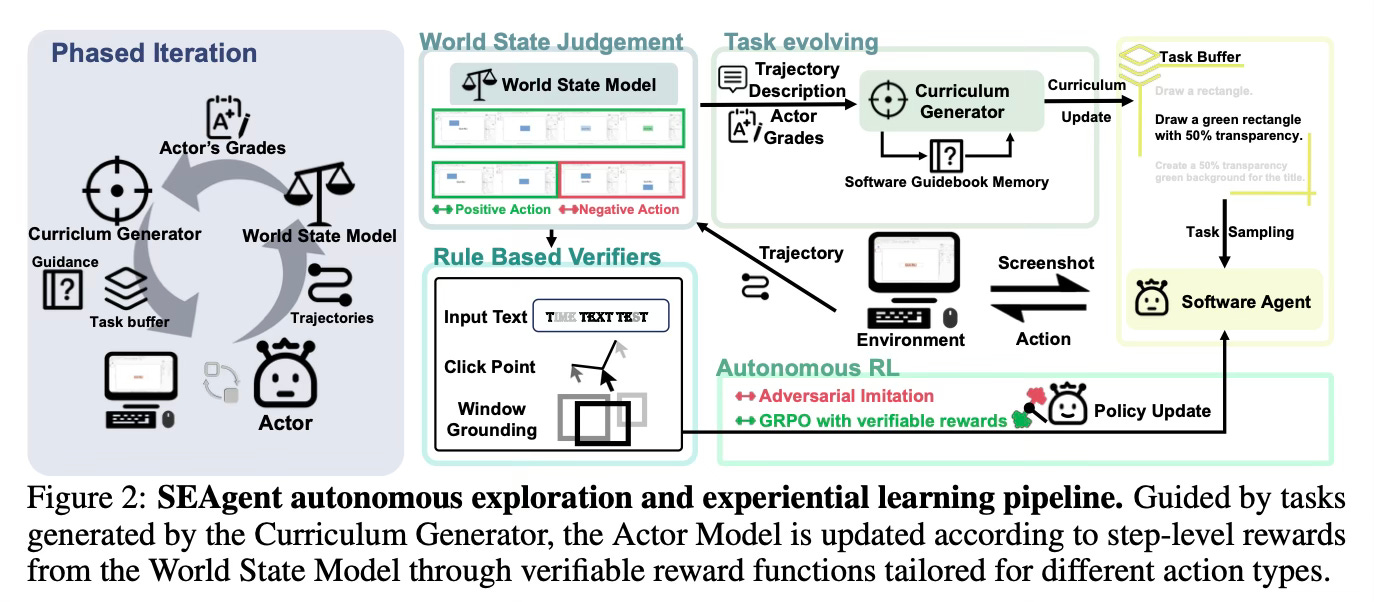
Intuitively, the agent starts with basic operations (e.g., open a menu, create a new file). As it succeeds, the system records what changed on screen and updates a guidebook of the software’s capabilities and interface. Based on that guidebook and the agent’s current skill level, the curriculum proposes harder tasks that chain together more steps (e.g., create a title, change style, insert media, save to a specific location). This cycle repeats in phases, steadily expanding what the agent can do.
Instead of judging only the final screenshot, the World State Model considers the full trajectory and assigns step-wise feedback. It produces detailed captions of GUI changes (e.g., which panel opened, what text appeared) and labels each action as helpful or harmful. That dense, trajectory-aware signal enables the agent to learn from both successes and mistakes. Learning from experience uses two complementary signals:
For actions that move in the right direction, the method applies verifiable rewards tailored to action types (clicks, drags, selections, typing). It optimizes these with Group Relative Policy Optimization (GRPO), encouraging the policy to prefer actions that better match verifiable outcomes (e.g., closer click coordinates, better box overlap, more accurate text).
For actions that cause failure or looping, the method applies adversarial imitation to explicitly push the policy away from those behaviors.
Finally, the paper proposes a specialist-to-generalist strategy. It first trains separate specialists on individual software using the self-evolving loop. It then distills successful specialist trajectories into a single base model via supervised fine-tuning and continues reinforcement learning across all software. This avoids the instability of learning all applications at once from scratch, and yields a stronger generalist model than training directly in a multi-software setup.
Results
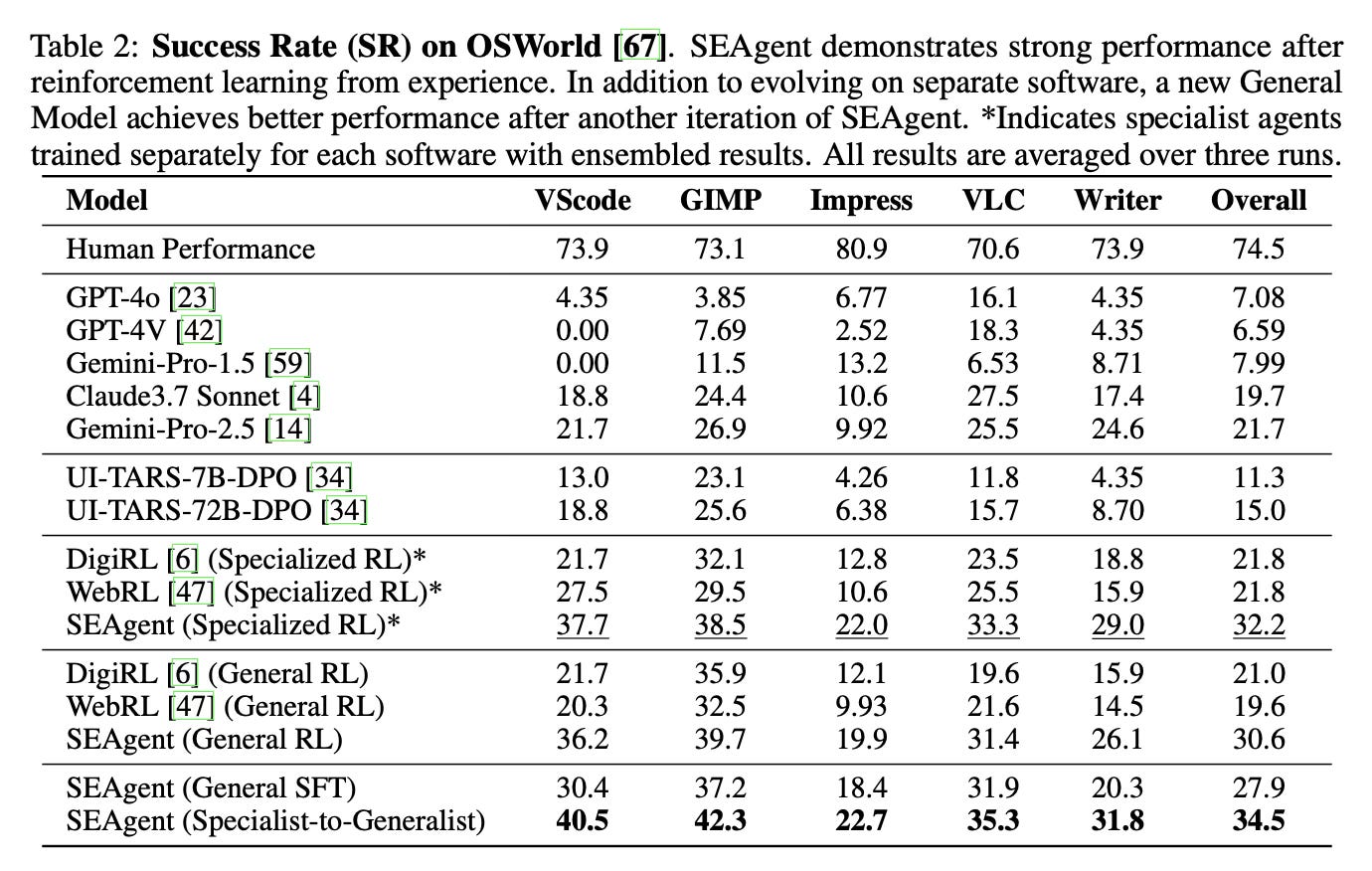
SEAgent demonstrates significant improvements over existing methods. On five professional software applications from the OSWorld benchmark, the system improved success rates from 11.3% to 34.5% - a 23.2% improvement over the baseline UI-TARS model. The specialist-to-generalist approach outperformed both individual specialists and direct multi-software training, achieving 34.5% success rate compared to 32.2% for specialist RL and 30.6% for direct generalist RL.
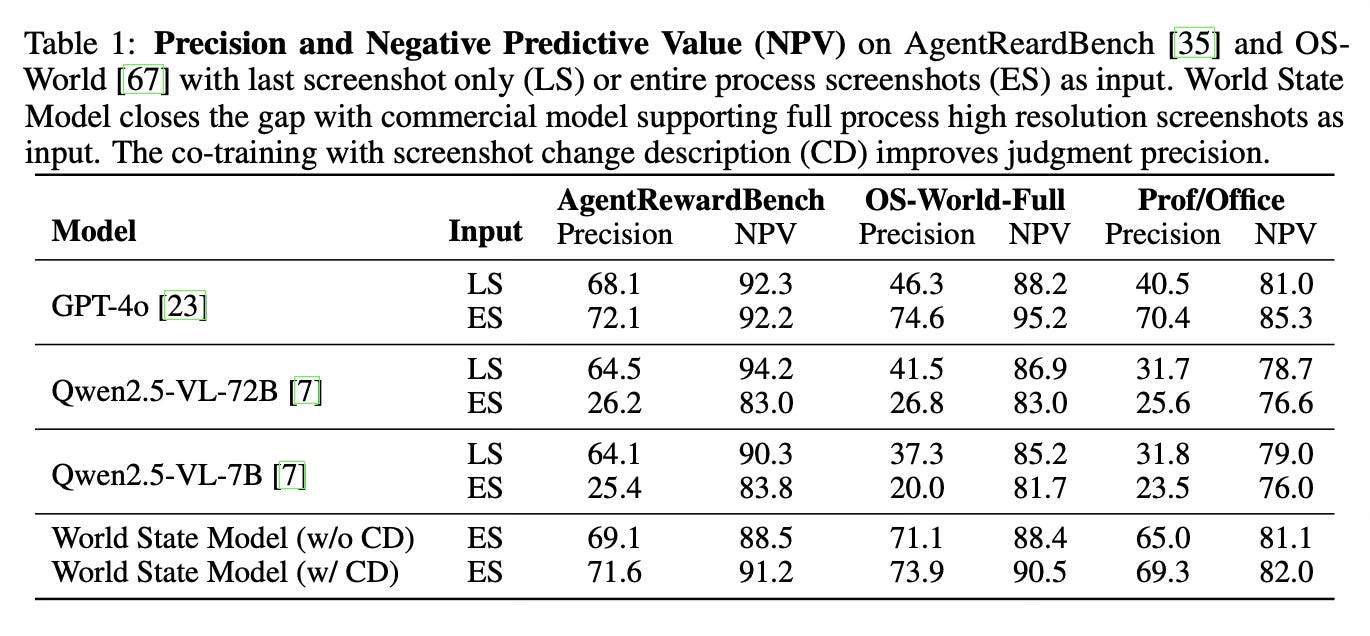
The World State Model, which provides step-level reward signals, proved crucial for the system's success. It achieved performance comparable to commercial models like GPT-4o while being based on an open-source foundation. The curriculum learning approach successfully generated increasingly complex tasks, with agents progressing from basic operations to sophisticated multi-step workflows across different software applications.
Conclusion
SEAgent presents a promising approach for developing autonomous computer use agents that can learn and adapt to new software environments without human supervision. The combination of curriculum learning, step-level reward signals, and the specialist-to-generalist training strategy enables agents to achieve substantial performance improvements through self-evolution. For more information please consult the full paper.
Congrats to the authors for their work!
Sun, Zeyi, et al. "SEAgent: Self-Evolving Computer Use Agent with Autonomous Learning from Experience." arXiv preprint arXiv:2508.04700 (2025).
Is there any tutorial for this implementation?