
SLA2: Sparse-Linear Attention with Learnable Routing and QAT

Today’s paper addresses the computational bottlenecks inherent in video diffusion models, specifically aiming to accelerate the attention mechanism which typically scales quadratically with sequence length. While prior approaches like Sparse-Linear Attention (SLA) attempted to mitigate this by combining sparse and linear attention, they relied on fixed, heuristic rules to split computation, often leading to suboptimal resource allocation and approximation errors. This paper introduces SLA2, a refined framework that replaces these heuristics with learnable components and integrates quantization strategies to significantly speed up video generation while preserving visual quality.
Method Overview
The main concept behind this method is to intelligently divide the workload of the attention mechanism into two distinct parts: a “sparse” part that handles the most critical connections between tokens, and a “linear” part that efficiently approximates the remaining background context. Unlike previous versions that used a static rule to guess which connections were important based on magnitude, this method trains a dynamic “router” to make these decisions. This router acts like a smart switch, predicting exactly which parts of the image or video sequence require detailed processing and which can be handled by the faster, approximate method.
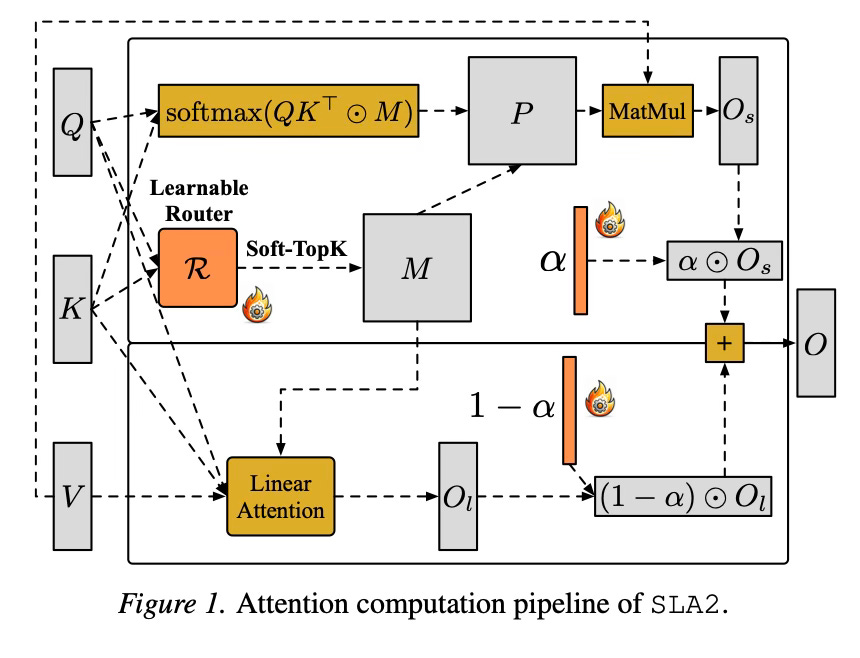
To support this dynamic routing, the paper reformulates how the sparse and linear branches are combined. Previous attempts suffered from a scaling mismatch where the output of the sparse branch did not mathematically align with the linear decomposition. SLA2 introduces a learnable ratio that blends the outputs of the two branches. This ensures that the combination creates a faithful approximation of the full attention map, correcting the scaling errors found in earlier iterations.
Additionally, the method incorporates Quantization-Aware Training (QAT) to further enhance efficiency. This involves training the model using low-bit precision (specifically for the sparse attention branch) during the forward pass. By exposing the model to the lower precision format during training, it learns to adapt to the quantization noise. This allows the model to utilize highly efficient low-bit kernels during inference without the significant drop in quality that usually accompanies post-training quantization.
Results
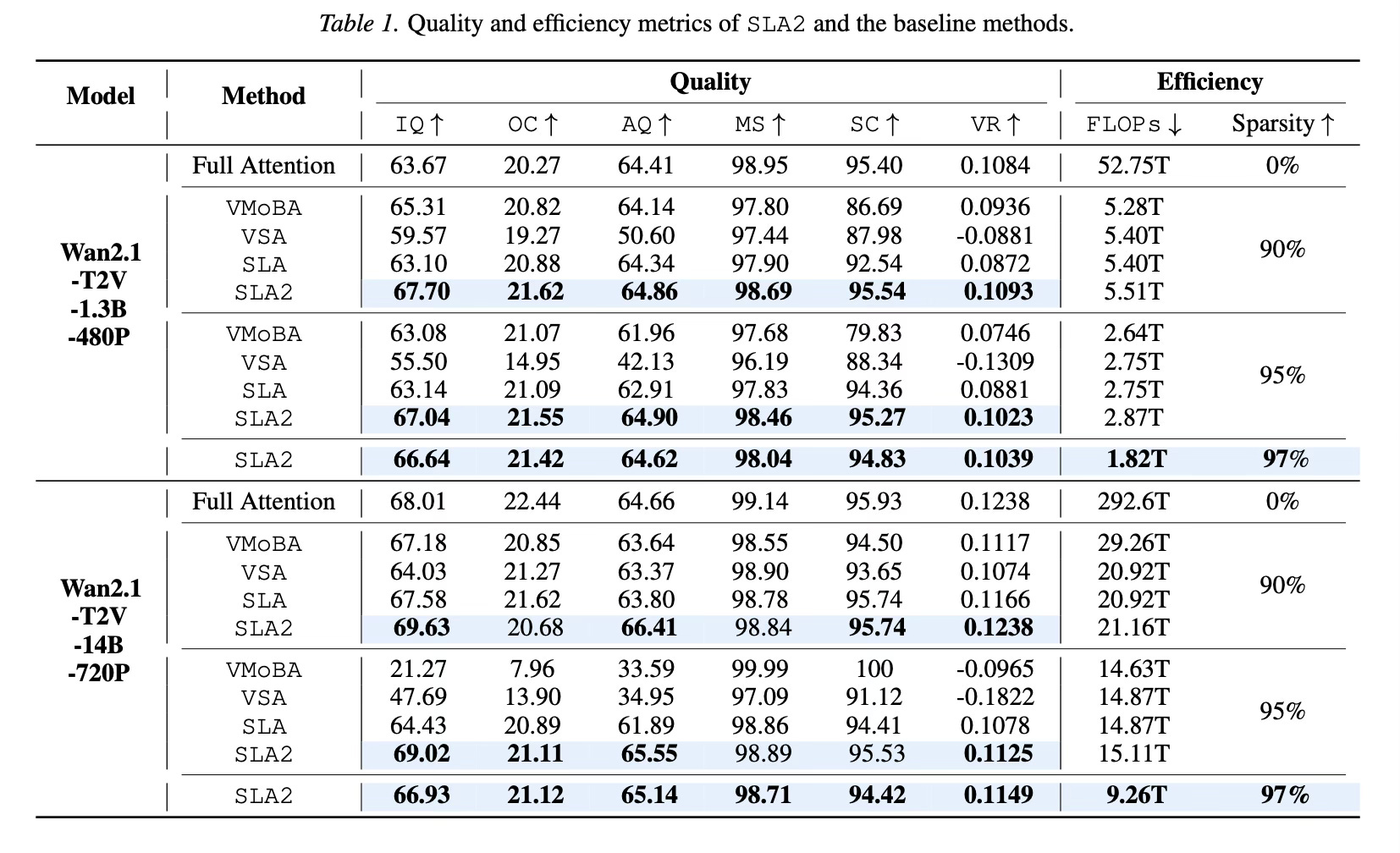
The method achieves substantial efficiency gains on video diffusion models, specifically tested on Wan2.1-1.3B and Wan2.1-14B. SLA2 reaches 97% attention sparsity, meaning only a tiny fraction of the full attention matrix is computed explicitly. This reduction results in an 18.6x speedup in attention runtime compared to standard FlashAttention. Despite this aggressive pruning, the method maintains generation quality that rivals full-attention models and outperforms baseline sparse attention methods at lower sparsity levels.

Conclusion
SLA2 presents a robust solution for accelerating diffusion transformers by optimizing the trade-off between sparse and linear attention. By introducing a learnable router, correcting mathematical formulation mismatches, and integrating quantization-aware training, the paper delivers a high-speed attention mechanism suitable for high-quality video generation.
For more information please consult the full paper.
Congrats to the authors for their work!
Zhang, Jintao, et al. “SLA2: Sparse-Linear Attention with Learnable Routing and QAT.” arXiv preprint arXiv:2602.12675 (2026).