
Step 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters

Today’s paper introduces Step 3.5 Flash, a large language model designed to bridge the gap between high-level reasoning capabilities and the computational efficiency required for real-world applications. While open-source models have improved significantly, they often struggle to match closed-source systems in complex agentic tasks or become too slow and costly when processing long contexts. This paper addresses these challenges by proposing a model that achieves frontier-level intelligence while maintaining low latency, making it particularly suitable for deploying sophisticated AI agents.
Method Overview
The core idea behind Step 3.5 Flash is to create a model that possesses a vast reservoir of knowledge but remains lightweight during execution. The method employs a “Sparse Mixture-of-Experts” (MoE) design, which means the model is composed of many specialized sub-networks (experts). For any given word (token) generated, only a small fraction of these experts are activated. This allows the model to scale its total parameter count to a massive 196 billion for high-fidelity modeling, while only utilizing 11 billion active parameters per token, ensuring fast and efficient inference.
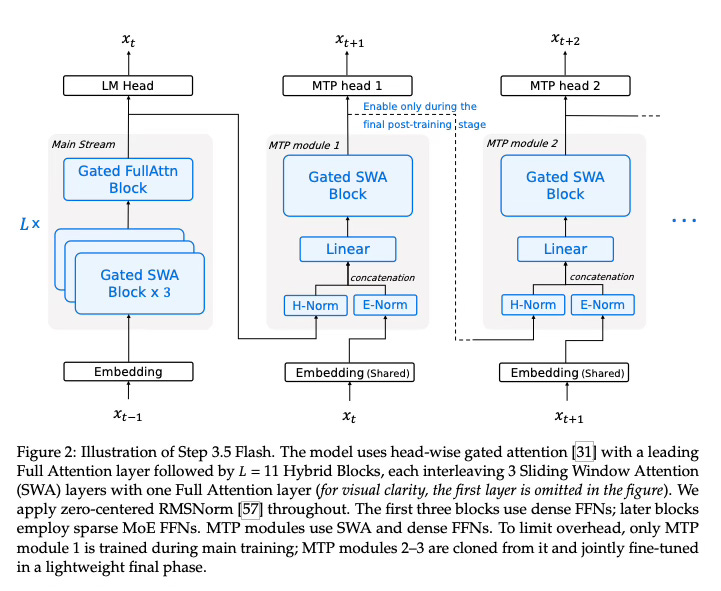
To further optimize performance for long-context tasks, typical of AI agents, the architecture utilizes a hybrid attention mechanism. Instead of using full attention for every layer—which becomes computationally expensive as text gets longer—the model interleaves Sliding Window Attention (SWA) with Full Attention in a 3:1 ratio. This allows the model to process local context efficiently while periodically checking global dependencies. To prevent quality loss often associated with sliding windows, the design increases the number of query heads and incorporates a head-wise gated attention mechanism, which functions similarly to data-dependent sink tokens, ensuring relevant information is retained without unnecessary computation.
The training process is built on a specialized infrastructure focusing on stability and scalability. It employs a multi-stage curriculum that transitions from general open-domain data to long-context and agent-specific data. A significant component of the post-training phase is a unified Reinforcement Learning (RL) framework called MIS-PO (Metropolis Independence Sampling-Filtered Policy Optimization). This technique stabilizes training for long-horizon reasoning by filtering out data samples that drift too far from the model’s policy, reducing gradient variance. The framework alternates between training domain-specific experts (in math, code, etc.) and distilling their capabilities back into a single generalist model, ensuring the final system is both versatile and robust.
Results
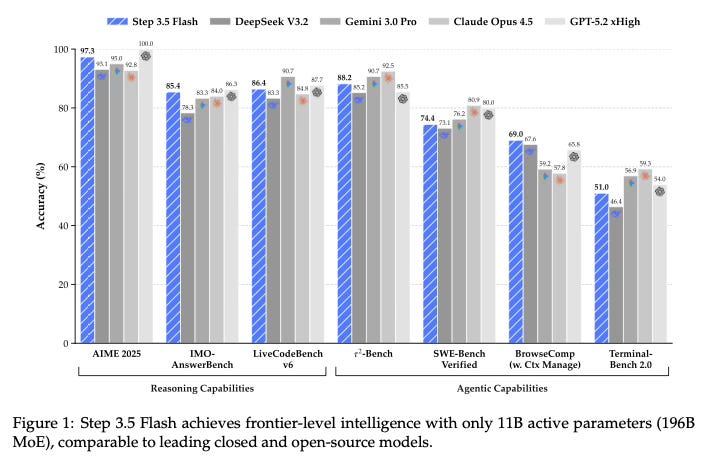
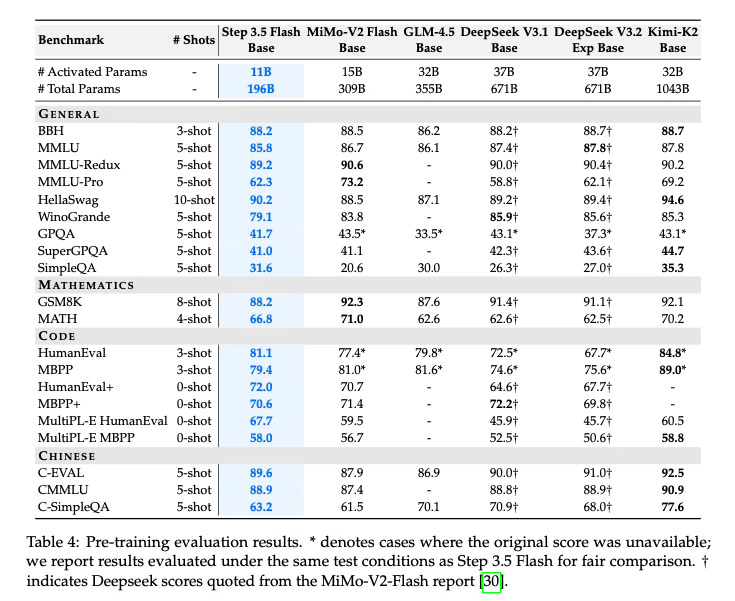
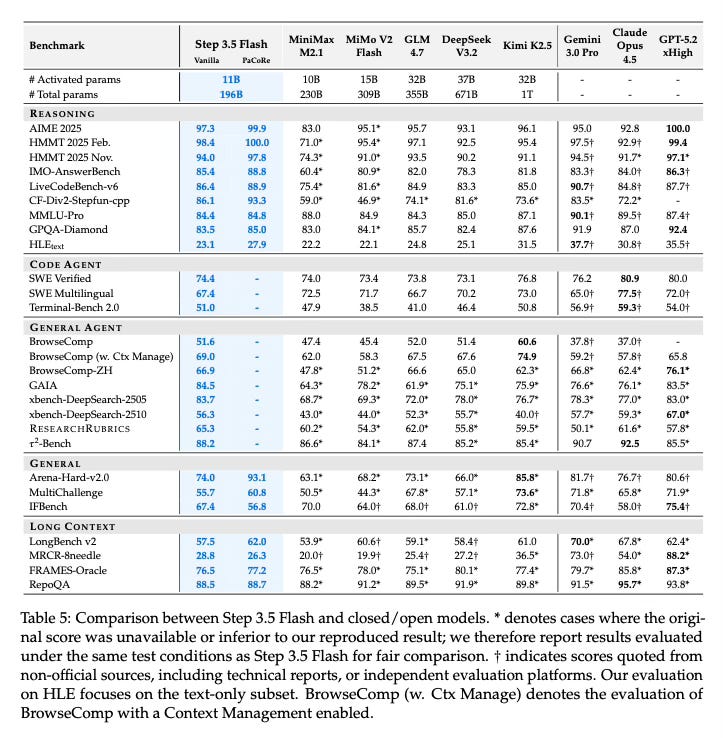
The paper demonstrates that Step 3.5 Flash achieves strong performance across various benchmarks, effectively balancing intelligence and efficiency.
Reasoning and Coding: The model scores 85.4% on IMO-AnswerBench and 86.4% on LiveCodeBench-v6, showing robust capabilities in mathematics and programming.
Agentic Capabilities: In tool-use and long-horizon tasks, it achieves 88.2% on 𝜏2-Bench and 69.0% on BrowseComp, indicating its suitability for complex agent workflows.
Efficiency: Under deployment conditions, the model sustains high throughput (approximately 170 tokens/s on Hopper GPUs), validating the architectural choices made for latency reduction.
Comparative Performance: The text reports performance on par with frontier systems such as GPT-5 and Gemini 3.0 Pro, suggesting it successfully narrows the gap between open models and proprietary leaders.
Conclusion
Step 3.5 Flash presents a high-density foundation for AI agents by combining a massive sparse MoE architecture with efficient hybrid attention and multi-token prediction. Through a stable training curriculum and a scalable reinforcement learning framework, the model delivers frontier-level reasoning and coding abilities with the speed requisite for industrial deployment.
For more information please consult the full paper.
Congrats to the authors for their work!
StepFun Team. “Step 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters.” arXiv preprint arXiv:2602.10604 (2026).