
Visual Prompting via Image Inpainting

Today's paper introduces a novel approach to adapt pre-trained visual models to new tasks without requiring task-specific fine-tuning or model modifications. The method, called visual prompting, uses image inpainting to solve various computer vision tasks by completing a specially constructed grid-like image containing example inputs and outputs. This approach is inspired by prompting in natural language processing, where models can be adapted to new tasks simply by providing examples in the input.
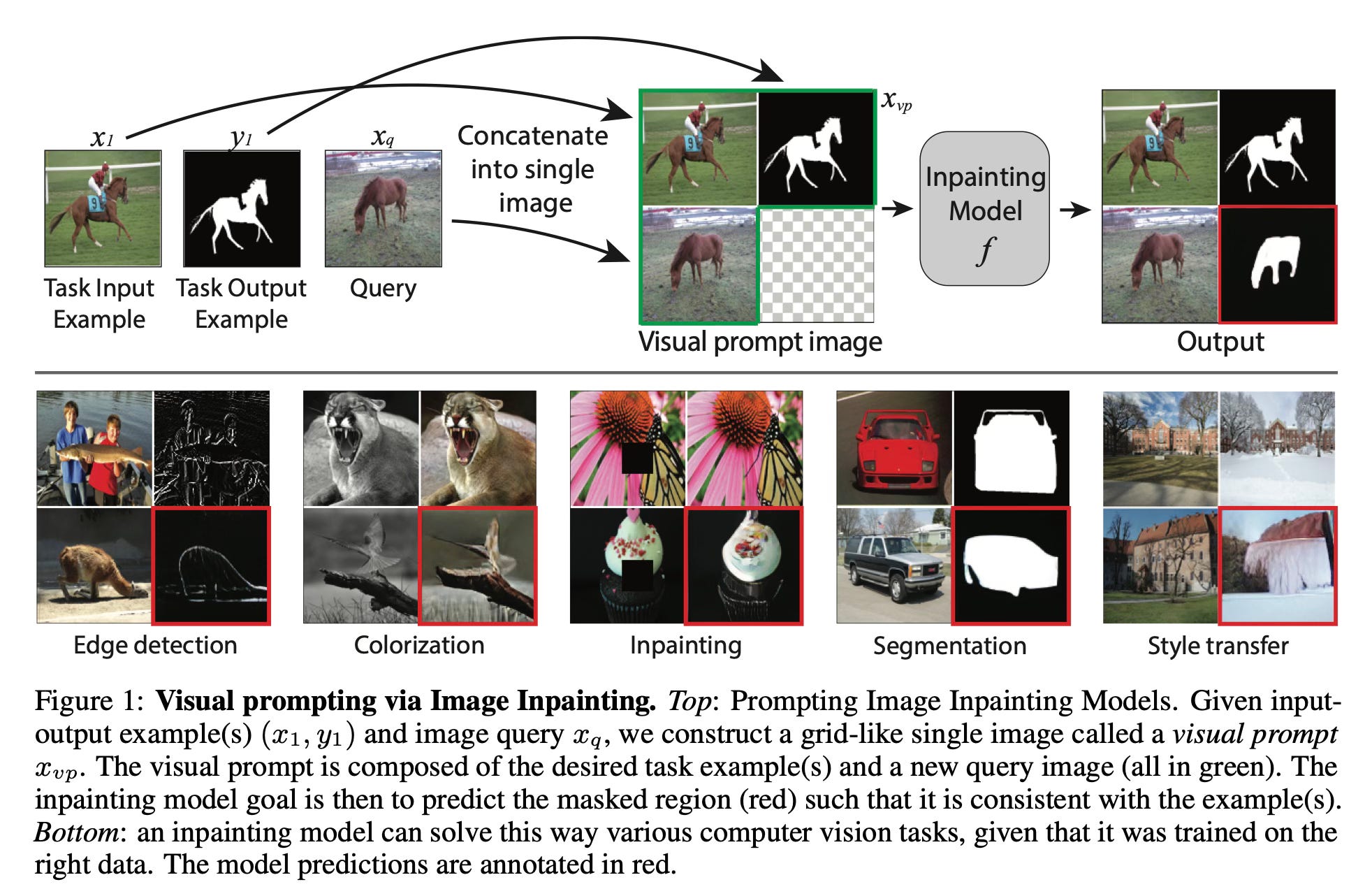
Method Overview
The approach works by constructing a special grid-like image called a "visual prompt" that contains example input-output pairs and a new query image. The model then completes this grid by filling in the missing part using image inpainting, effectively solving the desired task for the query image.
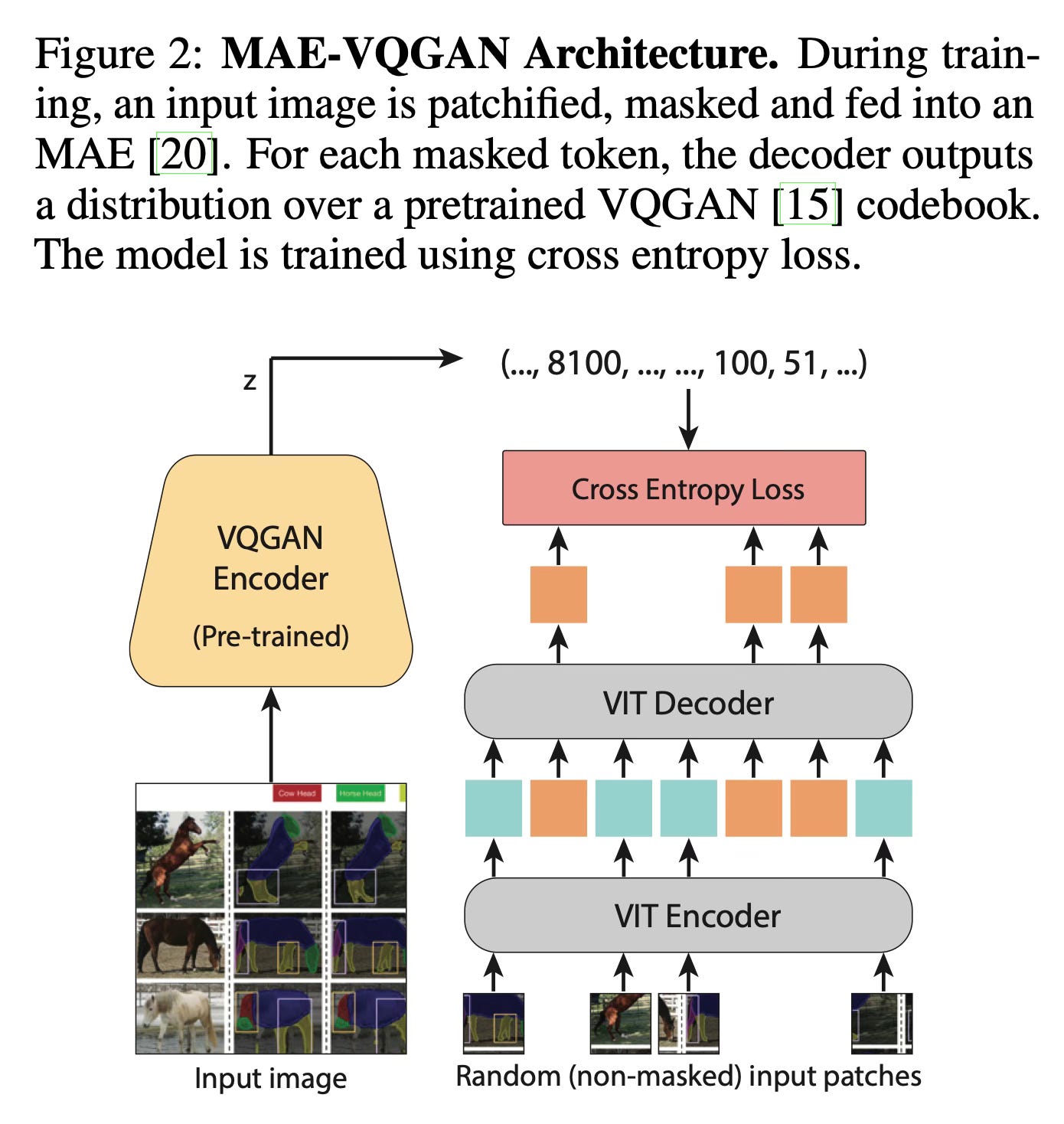
The key component is a modified Masked Autoencoder (MAE-VQGAN) that is trained on a specially curated dataset of 88,000 figures from computer vision research papers. This dataset is crucial because it contains many examples of grid-like layouts showing various image transformations, which helps the model learn to understand and replicate different types of visual tasks.

The method uses a vocabulary of visual tokens from a pre-trained VQGAN model to represent image patches, allowing it to handle ambiguity in the possible completions. During inference, the model processes the visual prompt as a single image and predicts the appropriate completion based on the provided examples.
Results
The paper demonstrates successful results on various computer vision tasks including:
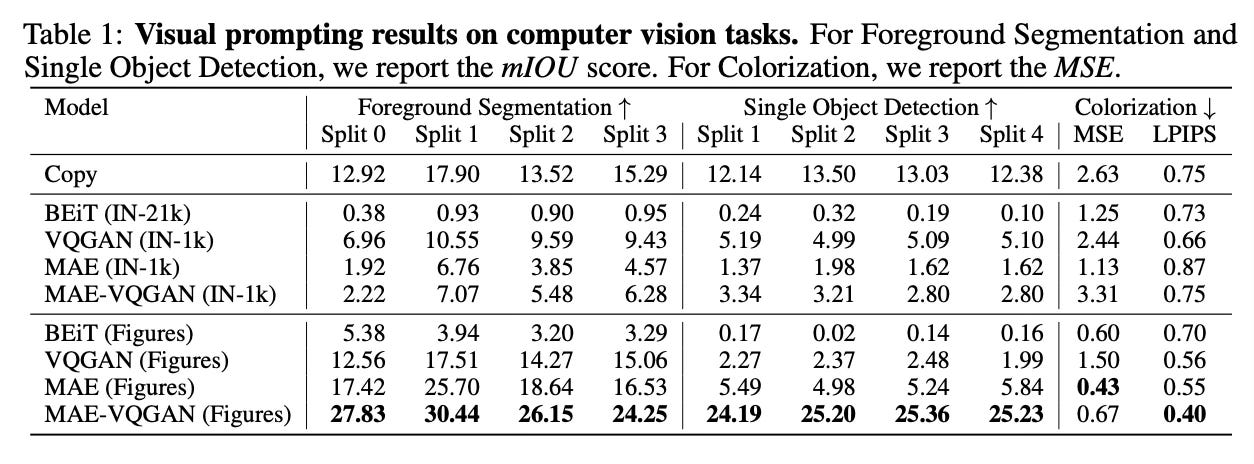
Foreground segmentation with up to 30.44% mean IOU
Single object detection with approximately 25% mean IOU
Image colorization with improved MSE and LPIPS metrics
Synthetic tasks involving color, shape, and size transformations
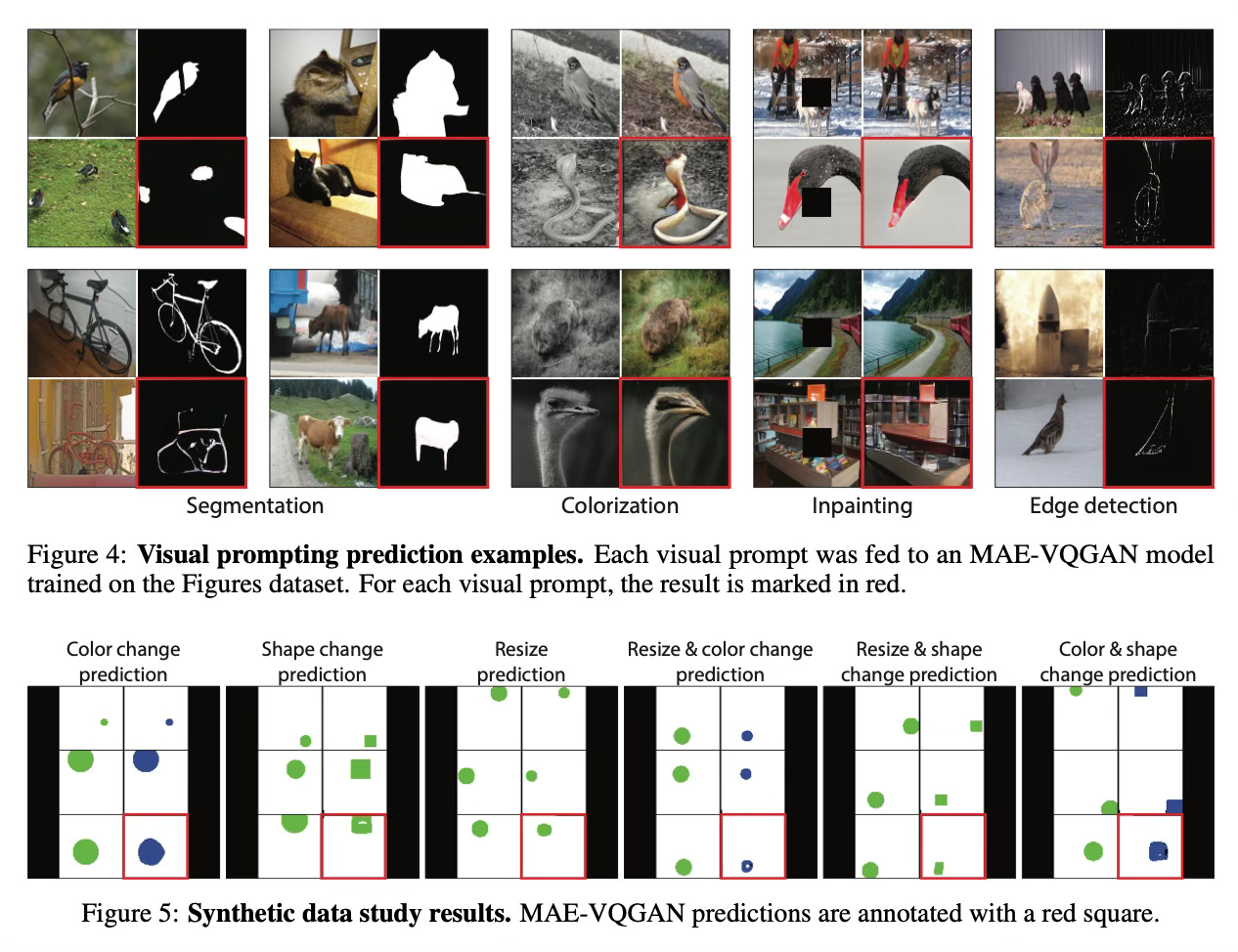
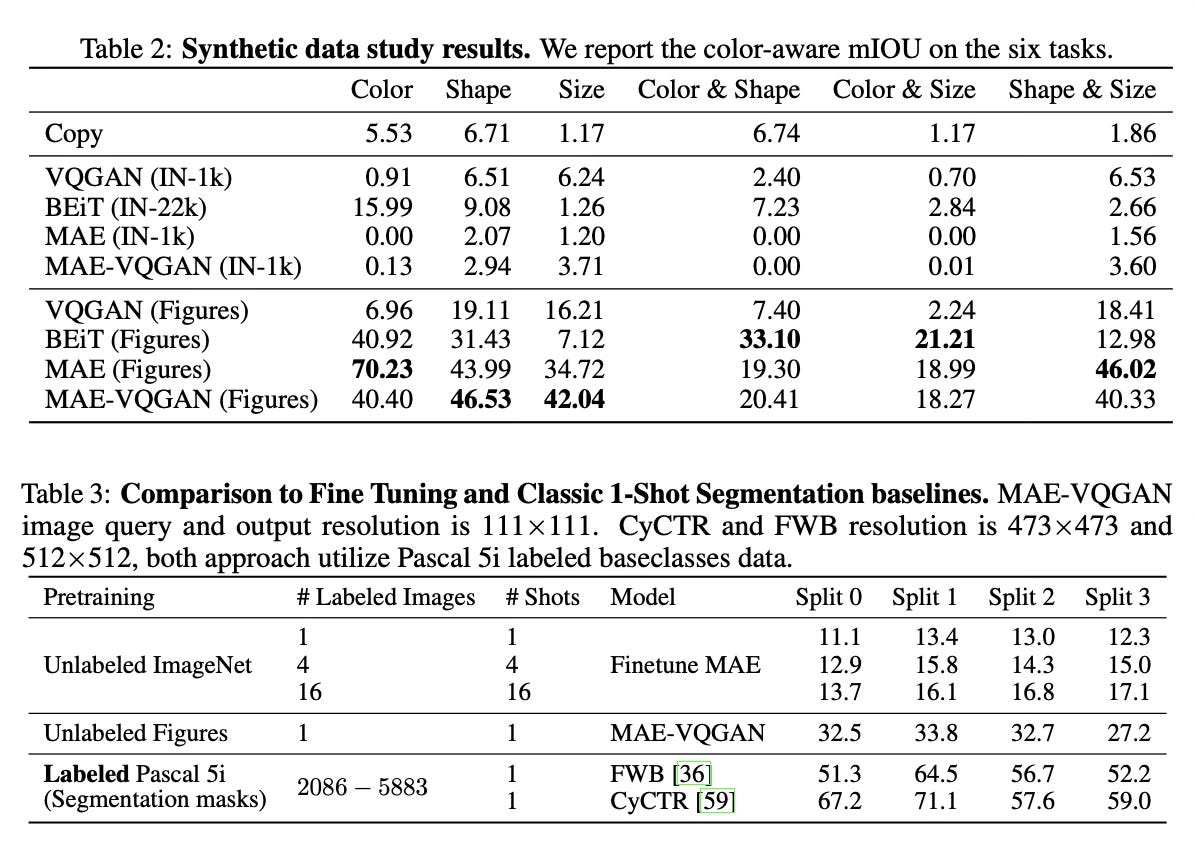
The method performs significantly better when trained on the curated figures dataset compared to training on standard image datasets like ImageNet. Additionally, performance improves when using multiple examples in the visual prompt.
Conclusion
The paper presents a simple yet effective approach for adapting visual models to new tasks through prompting. By reformulating various computer vision tasks as image inpainting problems and training on an appropriate dataset, the method can perform multiple tasks without task-specific training or architecture modifications. While not yet competitive with fully supervised approaches, this work opens new possibilities for more flexible and adaptable computer vision systems. For more information please consult the full paper.
Congrats to the authors for their work!
Bar, Amir, et al. "Visual Prompting via Image Inpainting." arXiv preprint arXiv:2209.00647 (2022).